一、Hadoop概述
Hadoop 是一个用于跨计算机集群存储和处理大型数据集的软件框架。它旨在处理大数据,即传统数据库无法有效管理的极其庞大和复杂的数据集。Hadoop不是传统意义上的数据仓库,因为它们的用途不同,架构也不同。Hadoop 是一个跨分布式计算机集群存储和处理大量非结构化和半结构化数据的框架。它专为处理大数据而设计,并支持使用 HDFS 和 MapReduce 等技术对大型数据集进行批处理。

而数据仓库是针对查询和分析进行了优化的结构化数据集中存储库。它通常用于存储来自各种来源的结构化数据,将其组织成模式,并提供快速访问以用于报告和分析目的。
1、四大组件
Hadoop 分布式文件系统 (HDFS):这是一个存储系统,它将大文件分解成小块并将它们分布在集群中的多台计算机上。它确保数据可靠性并支持跨集群并行处理数据。
MapReduce:这是一种编程模型,用于在集群中并行处理和分析大型数据集。它由两个主要任务组成:Map,处理并将输入数据转换为中间键值对;Reduce,聚合和汇总中间数据以生成最终输出。
YARN(资源协商器):YARN 是 Hadoop 的资源管理和作业调度组件。它将资源(CPU、内存)分配给集群上运行的各种应用程序并有效地管理它们的执行。
Hadoop Common:包括其他 Hadoop 组件使用的库和实用程序。它为整个 Hadoop 生态系统提供工具和基础设施,例如身份验证、配置和日志记录。
2、特点
Hadoop 的最大优势在于它能够高效处理大量数据。Hadoop 旨在将数据和处理任务分布到集群中的多台计算机,使其能够轻松扩展以处理传统数据库或处理系统难以管理的海量数据集。让用户能够存储、处理和分析大量数据。
3、架构
Hadoop 是一个用 Java 编写的 Apache 开源框架,它允许使用简单的编程模型在计算机集群之间分布式处理大型数据集。Hadoop 框架应用程序在提供跨计算机集群的分布式存储和计算的环境中工作。
Hadoop 的核心有两个主要层,即处理/计算层(MapReduce),以及存储层(Hadoop分布式文件系统)。
Hadoop 分布式文件系统 (HDFS) 基于 Google 文件系统 (GFS),提供旨在在商用硬件上运行的分布式文件系统。它与现有的分布式文件系统有许多相似之处。但是,它与其他分布式文件系统的区别也很大。它具有高度的容错能力,旨在部署在低成本硬件上。它提供对应用程序数据的高吞吐量访问,适用于具有大型数据集的应用程序。
Hadoop 受 GNU/Linux 平台及其变体的支持。虽然 Hadoop 的核心组件是用 Java 编写的,理论上可以运行在任何支持 Java 的平台上,包括 Windows,但 Hadoop 官方并不推荐在 Windows 上运行。
二、大数据
传统方法是企业将拥有一台计算机来存储和处理大数据。为了存储,程序员将借助他们选择的数据库供应商,例如 Oracle、IBM 等。在这种方法中,用户与应用程序交互,应用程序则负责处理数据存储和分析部分。
这种方法对于那些处理数据量较少(标准数据库服务器可以容纳,或者处理数据的处理器可以承受)的应用程序来说效果很好。但是,当涉及到处理大量可扩展数据时,单一数据库的瓶颈立刻就显现出来了。
Google 使用一种名为 MapReduce 的算法解决了这个问题。该算法将任务分成小部分并分配给多台计算机,然后从这些计算机中收集结果,将结果整合在一起,形成结果数据集。利用Google提供的解决方案,Doug Cutting和他的团队开发了一个名为HADOOP的开源项目。
Hadoop 使用 MapReduce 算法运行应用程序,其中数据与其他数据并行处理。简而言之,Hadoop 用于开发能够对大量数据进行完整统计分析的应用程序。
三、手动编译
在源码的BUILDING.txt文件里面,明确说明了需要的相关软件版本。

1、创建了一个ubuntu虚拟机
2、安装ssh、git
3、配置git
4、下载源码
git clone git@github.com:apache/hadoop.gitgit下载慢,还是选择手动下载
从官网下载,用迅雷拽下来,然后上传到虚拟机
Apache Download MirrorsHome page of The Apache Software Foundation![]() https://www.apache.org/dyn/closer.cgi/hadoop/common/hadoop-3.4.0/hadoop-3.4.0-src.tar.gz5、安装jdk
https://www.apache.org/dyn/closer.cgi/hadoop/common/hadoop-3.4.0/hadoop-3.4.0-src.tar.gz5、安装jdk
$ sudo apt-get update$ sudo apt-get -y install openjdk-8-jdk6、安装maven
$ sudo apt-get -y install maven7、安装Native libraries
$ sudo apt-get -y install build-essential autoconf automake libtool cmake zlib1g-dev pkg-config libssl-dev libsasl2-dev8、安装GCC
这一步,ubuntu自带了,如果是没有带的需要自己安装。有版本要求,
9、安装cmake
同上
10、安装Protocol
$ curl -L https://github.com/protocolbuffers/protobuf/archive/refs/tags/v3.21.12.tar.gz > protobuf-3.21.12.tar.gz$ tar -zxvf protobuf-3.21.12.tar.gz && cd protobuf-3.21.12
$ ./autogen.sh
$ ./configure
$ make -j$(nproc)
$ sudo make install11、安装Boost
有一些编译失败,不知道和GCC版本是否有关系,暂时没管,如果编译hadoop失败,那就再重新倒腾。
$ curl -L https://sourceforge.net/projects/boost/files/boost/1.72.0/boost_1_72_0.tar.bz2/download > boost_1_72_0.tar.bz2$ tar --bzip2 -xf boost_1_72_0.tar.bz2 && cd boost_1_72_0$ ./bootstrap.sh --prefix=/usr/$ ./b2 --without-python$ sudo ./b2 --without-python install12、编译
为了快一点,跳过文档
mvn package -Pdist -DskipTests -Dtar -Dmaven.javadoc.skip=true环境都顺利的话,也是要编译很久,编译出来的在hadoop-dist/target目录下。
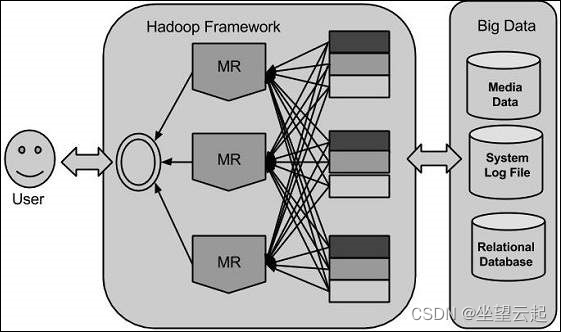
编译结果如下图,基本各个文件夹都是sh或者cmd脚本,以及一些配置文件,只有share下面包含了大量的jar包,其中hadoop的共168个,其它的应该都是依赖的jar包。
然后基于官方的运行安装命令就可以编辑配置文件,执行脚本运行了。当然最简单的办法还是直接下载官方编译好的来运行,这里编译的目的主要是为了测试和了解。