
摘要:
介绍了昇思MindSpore模型训练的步骤和具体实现方法。包括构建数据集、定义神经网络模型、超参、损失函数、优化器、训练评估等内容。
一、概念要点
模型训练四步骤:
1.构建数据集。
2.定义神经网络模型。
3.定义超参、损失函数及优化器。
4.输入数据集进行训练与评估。
二、环境准备
安装minspore模块
!pip uninstall mindspore -y
!pip install -i https://pypi.mirrors.ustc.edu.cn/simple mindspore==2.3.0rc1导入numpy、minspore、nn、dataset、transforms等相关模块
import mindspore
from mindspore import nn
from mindspore.dataset import vision, transforms
from mindspore.dataset import MnistDataset三、构建数据集
下载MNIST数据包;
构建训练数据集和测试数据集。
# Download data from open datasets
from download import downloadurl = "https://mindspore-website.obs.cn-north-4.myhuaweicloud.com/" \"notebook/datasets/MNIST_Data.zip"
path = download(url, "./", kind="zip", replace=True)def datapipe(path, batch_size):image_transforms = [vision.Rescale(1.0 / 255.0, 0),vision.Normalize(mean=(0.1307,), std=(0.3081,)),vision.HWC2CHW()]label_transform = transforms.TypeCast(mindspore.int32)dataset = MnistDataset(path)dataset = dataset.map(image_transforms, 'image')dataset = dataset.map(label_transform, 'label')dataset = dataset.batch(batch_size)return datasettrain_dataset = datapipe('MNIST_Data/train', batch_size=64)
test_dataset = datapipe('MNIST_Data/test', batch_size=64)输出:
Downloading data from https://mindspore-website.obs.cn-north-4.myhuaweicloud.com/notebook/datasets/MNIST_Data.zip (10.3 MB)file_sizes: 100%|███████████████████████████| 10.8M/10.8M [00:00<00:00, 101MB/s]
Extracting zip file...
Successfully downloaded / unzipped to ./四、定义神经网络模型
从网络构建中加载代码,构建一个神经网络模型。
class Network(nn.Cell):def __init__(self):super().__init__()self.flatten = nn.Flatten()self.dense_relu_sequential = nn.SequentialCell(nn.Dense(28*28, 512),nn.ReLU(),nn.Dense(512, 512),nn.ReLU(),nn.Dense(512, 10))
def construct(self, x):x = self.flatten(x)logits = self.dense_relu_sequential(x)return logits
model = Network()五、定义超参、损失函数和优化器
1.超参Hyperparameters
调试超参,控制模型训练优化的过程,影响模型训练和收敛速度。
深度学习模型多采用批量随机梯度下降算法进行优化。
随机梯度下降算法的原理公式如下:
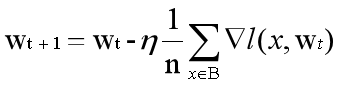
n 批量大小batch size
η 学习率learning rate
wt 训练轮次t中的权重参数
∇l 损失函数的导数
后两个因子直接决定了模型的权重更新,是优化过程中影响模型性能收敛最重要的参数。
定义训练超参:
训练轮次epoch
训练时遍历数据集的次数。
批次大小batch size
数据集分批读取训练,设定每个批次数据的大小。
batch size过小,花费时间多,梯度震荡严重,不利于收敛;
batch size过大,不同batch的梯度方向没有任何变化,容易陷入局部极小值;
合适的batch size有效提高模型精度、全局收敛。
学习率learning rate
学习率偏小,收敛速度变慢,学习率偏大,训练不收敛;
梯度下降法广泛应用在最小化模型误差的参数优化算法上,
通过多次迭代,在每一步中最小化损失函数来预估模型的参数,
学习率在迭代过程中控制模型的学习进度。
epochs = 3
batch_size = 64
learning_rate = 1e-22.损失函数loss function
评估模型的预测值logits和目标值targets之间的误差。
模型训练的目标即为降低损失函数求得的误差。
常见的损失函数包括
用于回归任务的nn.MSELoss(均方误差)
用于分类的nn.NLLLoss(负对数似然)
nn.CrossEntropyLoss结合LogSoftmax和NLLLoss对logits归一化并计算预测误差。
loss_fn = nn.CrossEntropyLoss()3.优化器Optimizer
模型优化是调整模型参数以减少模型误差的过程。
MindSpore优化器提供多种优化算法。
优化器定义了模型参数优化过程(即梯度如何更新至模型参数),封装了所有优化逻辑。
下例中使用SGD(Stochastic Gradient Descent)优化器。
SGD初始化参数为和学习率超参。
模型训练参数用model.trainable_params()方法获取。
optimizer = nn.SGD(model.trainable_params(), learning_rate=learning_rate)微分函数计算获得参数对应的梯度;
优化器实现参数优化。
grads = grad_fn(inputs)
optimizer(grads)六、训练与评估
设置超参、损失函数和优化器后,循环输入数据训练模型。
一次数据集的完整迭代循环称为一轮(epoch)。
每轮执行训练时包括两个步骤:
1.训练 :train_loop函数,迭代训练数据集,尝试收敛到最佳参数。
2.验证/测试: test_loop函数, 迭代测试数据集,检查模型性能是否提升。
具体如下:
定义正向函数forward_fn;
value_and_grad获得微分函数grad_fn;
将微分函数和优化器的执行封装为train_step函数;
train_loop函数循环迭代数据集进行训练。
test_loop函数循环遍历数据集,调用模型计算loss和Accuray并返回最终结果。
# Define forward function
def forward_fn(data, label):logits = model(data)loss = loss_fn(logits, label)return loss, logits
# Get gradient function
grad_fn = mindspore.value_and_grad(forward_fn, None, optimizer.parameters, has_aux=True)
# Define function of one-step training
def train_step(data, label):(loss, _), grads = grad_fn(data, label)optimizer(grads)return loss
def train_loop(model, dataset):size = dataset.get_dataset_size()model.set_train()for batch, (data, label) in enumerate(dataset.create_tuple_iterator()):loss = train_step(data, label)
if batch % 100 == 0:loss, current = loss.asnumpy(), batchprint(f"loss: {loss:>7f} [{current:>3d}/{size:>3d}]")def test_loop(model, dataset, loss_fn):num_batches = dataset.get_dataset_size()model.set_train(False)total, test_loss, correct = 0, 0, 0for data, label in dataset.create_tuple_iterator():pred = model(data)total += len(data)test_loss += loss_fn(pred, label).asnumpy()correct += (pred.argmax(1) == label).asnumpy().sum()test_loss /= num_batchescorrect /= totalprint(f"Test: \n Accuracy: {(100*correct):>0.1f}%, Avg loss: {test_loss:>8f} \n")下面将实例化的损失函数和优化器传入train_loop和test_loop中。
训练3轮并输出loss和Accuracy,查看性能变化。
loss_fn = nn.CrossEntropyLoss()
optimizer = nn.SGD(model.trainable_params(), learning_rate=learning_rate)
for t in range(epochs):print(f"Epoch {t+1}\n-------------------------------")train_loop(model, train_dataset)test_loop(model, test_dataset, loss_fn)
print("Done!")输出:
Epoch 1
-------------------------------
loss: 2.296380 [ 0/938]
loss: 1.757596 [100/938]
loss: 0.974483 [200/938]
loss: 0.511490 [300/938]
loss: 0.500946 [400/938]
loss: 0.597918 [500/938]
loss: 0.317115 [600/938]
loss: 0.389769 [700/938]
loss: 0.387721 [800/938]
loss: 0.434749 [900/938]
Test: Accuracy: 90.9%, Avg loss: 0.319289 Epoch 2
-------------------------------
loss: 0.530089 [ 0/938]
loss: 0.261937 [100/938]
loss: 0.322976 [200/938]
loss: 0.277932 [300/938]
loss: 0.376985 [400/938]
loss: 0.304954 [500/938]
loss: 0.188373 [600/938]
loss: 0.354012 [700/938]
loss: 0.178002 [800/938]
loss: 0.265701 [900/938]
Test: Accuracy: 92.8%, Avg loss: 0.253910 Epoch 3
-------------------------------
loss: 0.307720 [ 0/938]
loss: 0.127973 [100/938]
loss: 0.440307 [200/938]
loss: 0.162731 [300/938]
loss: 0.163589 [400/938]
loss: 0.294433 [500/938]
loss: 0.151987 [600/938]
loss: 0.299143 [700/938]
loss: 0.153824 [800/938]
loss: 0.290957 [900/938]
Test: Accuracy: 94.0%, Avg loss: 0.209416 Done!





_百度推广优化方案_郑州官网网络营销外包)





