
Linux:冯诺依曼体系-CSDN博客先了解一下这篇的基础知识
操作系统简述-CSDN博客还有这篇
ok我们来说进程
进程是什么?
在Windows下我们按下Esc+Ctrl+Shift召唤任务管理器,查看Windows下的进程
我们的进程也是由操作系统管理的,操作系统对进程的管理也是先描述再组织。
进程
课本概念:程序的一个执行实例,正在执行的程序等
内核观点:担当分配系统资源(CPU时间、内存)的实体
每一个进程创建时都会有一个对应的struct PCB。它们本身都存在磁盘里,当你需要时,它们会从磁盘加载到内存里。

什么叫PCB?
PCB(process control block)进程控制块,简单来说是一个结构体,但是是操作系统来管理进程的一个结构体。
每次我们使用电脑开机的过程,都是先加载操作系统。操作系统没开机的时候,也是存在磁盘里的一个二进制文件,是开机时打开的第一个软件,将存在磁盘里的操作系统加载到内存部。进程不仅要将可执行程序的代码和数据加载到内存中,还要给它的结构体PCB也申请一个内存出来,方便操作系统对进程进行管理。
这个PCB怎么用呢?
一个PCB代表了一个进程的储存信息,那么用多个PCB将它们用指针串起来,是不是就形成了一个进程管理的链表?我们对进程的管理也就变成了对链表的增删改查。不用直接加载我们的可执行程序,因为一个一个加载很麻烦(我们有时候也不需要那么多的信息)而是管理我们的进程控制块。
为什么要有PCB呢?
还记得我们刚才说的先描述后组织吗?PCB就在这里起到了一个描述的作用,一个进程=内核task_struct结构体+程序的代码+数据,方便我们的操作系统管理进程。
struct task_struct
{//Linux进程控制块}操作系统对进程进行运行调度,本质上就是让进程控制块task_struct进行排队,因为他们是描述进程的结构体,你不能让进程一个一个排队,但是可以让描述他们的结构体来排队。
怎样理解进程是动态运行的?
我们的进程可能会出现在各种地方,比如说现在在磁盘等待被加载,然后又在CPU里被运行,然后又在等待显示器、键盘的网络资源。进程动态运行的特点主要体现在CPU或其他设备想要被进程访问执行时,都是以PCB为代表被来回调度运行的。
这个调度运行就是我们进程的动态运行,我们的PCB怎样运行,也就意味着我们的进程怎样运行。task_struct在不同的队列中,PCB节点就被放到不同的地方,进程就可以访问不同的资源。
task_struct属性
启动
./xxxx运行某个程序本质就是让系统创建进程并运行

我们学过的命令在Linux下也是可执行程序


我们自己写的程序本质上也是可执行程序。

查看进程
ps axj
我们在Linux下运行的大部分操作本质上都是运行进程。当然,进程只有程序在运行的时候才被称为进程。一个程序运行完结束了之后,他就不叫进程了,也就无法通过此条命令被查询出来。
这样我们可以查到所有的进程。那么如何可以检索到某个特定的进程呢?
使用我们之前所学的管道和grep命令。
ps axj | grep myprocess
通过管道和关键词检索的方式查出了指定进程,grep本身也是一个进程,所以也被检索出来了
那么每一列都是什么意思?我们可以通过下面这个命令把首行解释列出。
ps ajx | head -1把首行解释和进程列表一起列出可以用&&来连接两条命令
ps ajx | head -1 && ps axj | grep process首行解释和进程列表

每个学生都有自己的学号,每个人都有自己的身份证号,每个进程也有自己唯一的标识符,叫做pid,进程PCB唯一区分用unsigned int pid
如果一个进程想要知道自己的pid该怎么办? task_struct被称为内核数据结构,pid就在里面,用户是不能直接访问内核数据结构的,应该通过操作系统为我们调用 task_struct的pid,例如 getpid()
process.c:
#include<stdio.h>
#include<unistd.h>
#include<sys/types.h>
#include<unistd.h>int main()
{pid_t id = getpid();while(1){printf("I am a process!,pid:%d\n",id);sleep(1);}return 0;
}运行一下可以看到进程的pid:

此时我们分屏打开第二个终端,在另一个终端中输入查找进程的指令,就可以确认该pid是不是进程pid

可以看到,确实是该进程的pid。
可能有些人理解不了,为什么要让一个程序一直在打印?因为一个程序一直在打印,才能说明他是一个正在运行的程序。我们输入命令没有反应的时候,就会通过新建一个终端来操作另一个终端。
在Windows下,我们启动一个进程,可以双击它的exe文件。在Linux下启动一个进程就是./执行可执行程序。
程序已经启动,我们可以用ps命令来查找进程。终止进程,我们可以使用ctrl+C,来让所有正在显示器进行的东西停止。
 还有一计,我们可以通过在另一个终端上输入以下命令,就可以把另一个进程停止掉。
还有一计,我们可以通过在另一个终端上输入以下命令,就可以把另一个进程停止掉。
kill -9 pid
pid,我们知道是什么意思吧。那么ppid是什么意思呢? pid的其中一个p是process啊,ppid前面那个多出来的p的意思是parent,他的意思就是获取父进程的pid,对于子进程就是ppid
pid_t getppid(void)//获取ppid的函数#include<stdio.h>
#include<unistd.h>
#include<sys/types.h>
#include<unistd.h>int main()
{pid_t id = getpid();pid_t parent = getppid();while(1){printf("I am a process!,pid:%d ,ppid:%d\n",id,parent);sleep(1);}return 0;
}ps ajx | head -1 && ps axj | grep process还是这样查询


我们会发现每次启动一个程序时,它的pid都不一样,这很正常。因为每次一个程序运行时,操作系统会为他分发一个新的pid,然后在程序结束时回收这个旧的pid,下次运行时在随机分发一个新的pid,所以才每次不一样,不然你的进程不就可以随便被人锁定了吗?
顺便一提,关闭会话管理器可以在[查看]里重新开启。
我们知道pid是我们正在运行这个程序的身份号码?那么ppid是哪个程序呢?

我们的命令解释器就是父进程了。
每创建一个进程是否有代表操作系统里多了一个进程?是这样的,多了一个进程就相当于多了一份PCB和一套该进程对应的代码和数据。创建一套进程会创建它的PCB,也就是它的内核数据结构,可是用户是没有权限对内核数据结构进行增删改查的,用户不能直接创建一个task_struct,操作系统可以为用户提供系统调用。
是什么呢?
这里插播一下 Man手册的使用,有时候你在man手册里面查不到对应的库函数的时候,可能是因为你的man手册不全。你可以通过以下命令来安装。
sudo apt-get install manpages-posix-dev但是我使用了之后发现,他告诉我命令不存在,于是我又查找了一下,最后发现我CentOS的系统中没有apt-get命令,需要从Yum中下载软件包,像这样
sudo yum install man-pages于是你就可以下载更全面的man手册。
 好了我们来查一下fork函数
好了我们来查一下fork函数

fork除了有叉子的意思还有岔路分叉的意思。他的作用就是
创建一个进程。
#include<stdio.h>
#include<unistd.h>
#include<sys/types.h>
#include<unistd.h>int main()
{printf("process is running,only me!\n");sleep(3);fork();printf("hello world\n");sleep(5);return 0;
}实时检测一下
while :; do ps ajx | head -1 && ps axj | grep process | grep -v grep; sleep 1; done
刚开始是没有任何进程的,直到我们开始执行process.out这个程序之后,我们发现出现了第一个进程监控,它的pid是22655,这个22655,就是一开始的父进程。之后我们发现后面又出现了一个新的进程,它的pid是22705,而它的PPID是22655,也就是说这个新的进程是我们刚刚创建出来的进程的子进程。
那这个子进程是怎么来的?就是我们刚刚查出的fork函数创造出来的。fork的功能就是创造出一个子进程。 fork之后,系统中多了一个进程,也就是说,它多了一个task_struct的进程控制块。但是这个进程还要有自己的代码和数据才能组成一个PCB块,那么它的代码和数据从哪里来?父进程的代码和数据是从磁盘加载来的。默认情况下子进程继承父进程的代码和数据。所以子进程的PCB=自己的task_struct+父进程的代码+父进程的数据。

可以看到执行进程一个是父,一个是子
主要是想让大家了解一下子进程执行和父进程执行不一样的代码,我们还需要学习一下fork的返回值。
pid_t fork(void);如果fork函数成功了,它会返回子进程的pid给父进程,返回0给子进程;如果创建失败,则返回-1,错误码被设置,也就是说fork会返回两次,创建成功则给两方返回不同的值,不成功则都返回-1
来试一下
#include<stdio.h>
#include<unistd.h>
#include<sys/types.h>
#include<unistd.h>int main()
{printf("process is running,only me!,pid:%d\n", getpid());sleep(3);pid_t id = fork();if (id == -1) return 1;else if (id == 0){//childwhile (1){printf("id:%d,I am child process, pid: % d, ppid : % d\n",id,getpid(),getppid());sleep(1);}}else{//parentwhile (1){printf("id:%d,I am parent process,pid:%d,ppid:%d\n",id, getpid(), getppid());sleep(2);}}return 0;
}这个代码的意思是,如果我们用id来接收fork的返回值,如果id是-1,就返回1,程序结束;如果id等于0,就进入while循环,如果id不等于1,也不等于0,就进入另一个while循环。

我们发现代码在fork之后进入了两个while循环,我们一般情况下只会进入一个while循环,不会出现两个while循环同时跑的情况(我们之前学习的都是单进程多进程情况也一样)
id为什么会进入两个while循环呢?
因为我们的for函数会有两个返回值且返回两次。它是由操作系统(OS)提供的,有自己的实现逻辑。当我们的函数执行到return的时候,这是否意味着函数的核心工作已经完成了?也就是说,当fork函数开始思考返回什么的时候,是不是意味着它已经解决了新建子进程的工作(无论他新建是否成功)
那么我们就应该return代码。 fork内部前半部分由父进程创建,子进程执行到return的时候我们的子进程已经创建完成了,父进程本来就在,这时候就有两个进程了,他们的代码共享。父进程执行一次return,子进程执行一次return。
但是我们同时进入了两个while循环,这就意味着我们的id大于0又等于零吗?
并不是,我们的子进程在创建的时候有自己的PCB,这个PCB在数据结构的层面与父进程的PCB是并列的,也就是说他们两个都在以同一条链子上串着,没有谁高谁低之分;但是在逻辑上是存在父子关系的。
父进程的代码和数据是从磁盘上加载来的。子进程继承父进程的代码和数据,子进程也要用父进程的代码和数据。
也就是说,从fork之后,我们这个代码被分为了两块并行,一块是给父进程执行的,一块是给子进程执行的。而这个ID他在父进程返回的值和在紫禁城返回的值也是不一样的,他们的变量名都叫ID,但是内容不一样。
一次创建5个进程
#include<stdio.h>
#include<unistd.h>
#include<sys/types.h>
#include<unistd.h>void RunChild()
{while (1){printf("I am parent, pid :%d,ppid: %d\n", getpid(), getppid());sleep(1);}
}
int main()
{const int num = 5;//创建五个子进程,改成几就创建几个子进程int i = 0;for (i = 0; i < num; i++){pid_t id = fork();if (id == 0) //因为父进程的id不等于0,所以直接跳过判断执行下次循环,创建紫禁城{RunChild();}sleep(1);}while (1){sleep(1);printf("I am parent, pid :%d,ppid: %d\n", getpid(), getppid());}return 0;
}
进程创建可以用代码的方式:fork(),而不是每次都需要./来启动进程
查看进程
除了ps命令,进程还可以通过/proc系统文件夹查看(proc是根目录下的一个文件夹):
 要获取PID为1021的进程信息,你需要查看/proc/1021这个文件夹,其中目录是以进程的pid命名的:
要获取PID为1021的进程信息,你需要查看/proc/1021这个文件夹,其中目录是以进程的pid命名的:
ll /proc/29129我们的进程都存在这里,都以进程的pid为目录名存在proc这个文件夹里。如果想要获取pid为1的进程信息,可以查看这个文件夹。
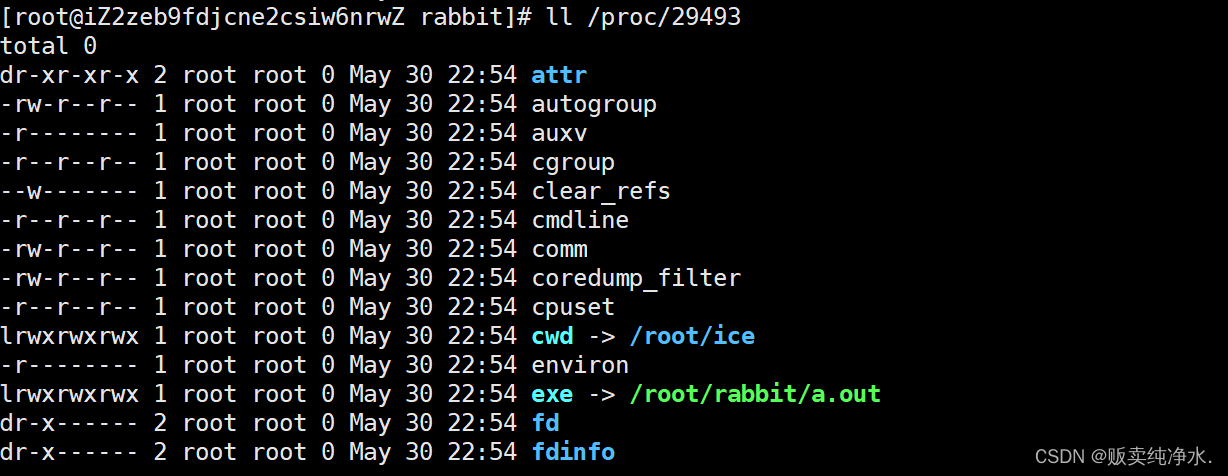
我们去7705里看看

其中一个比较重要的属性是exe。
这个exe是由绿色路径下的可执行程序加载出来的,如果我们把后面绿色路径这个可执行的程序干掉的话,程序也能跑。这是为什么?因为文件能够被继承调度是因为它在内存里。他为什么在内存里?是因为它从磁盘里加载出来。如果你在磁盘层面上把它删掉的话,内存里它还有还是可以跑的,只不过你重新关开关机之后可能就用不了了。
当然也有可能跑不了,比如说电脑内存只有8g,可执行程序占磁盘16G,你把这个16g删了,进程可能运行着运行着就出现问题了。
进程的PCB会记录自己对应的可执行程序路径。那么上面的cwd是什么呢?
cwd(current work dir)进程的当前工作路径
每个进程在启动时会记录自己在哪个路径下启动,也就是进程当前的路径。如果我们在代码里写一个新建文件的代码,它会在当前的工作路径下新建。
#include<stdio.h>
#include<sys/types.h>
#include<unistd.h>int main()
{chdir("/root/ice");//这行是改变工作路径FILE *fp = fopen("log.txt","w");(void)fp; //ignore warnning fclose(fp);while(1){printf("I am a process,pid:%d\n",getpid());sleep(1);}return 0;
}可以发现路径发生改变了:
也确实在我们指定的目录下新建文件了:

进程状态
每个进程都要有自己的状态
Linux进程状态
进程状态是task_struct内部的一个属性:
#define RUN 1
#define SLEEP 2
#define STOP 3struct task_struct
{//内部属性int status;}struct task_struct process1;
process1.status = RUN;Linux改变一个进程的状态就是在改变task_struct的内部属性 (定义出的标志位,为了表示进程的状态)
Linux内核中对于状态有什么定义呢?
可以看看kernel的源码:
/*
* The task state array is a strange "bitmap" of
* reasons to sleep. Thus "running" is zero, and
* you can test for combinations of others with
* simple bit tests.
*/
static const char * const task_state_array[] = {
"R (running)", /* 0 */
"S (sleeping)", /* 1 */
"D (disk sleep)", /* 2 */
"T (stopped)", /* 4 */
"t (tracing stop)", /* 8 */
"X (dead)", /* 16 */
"Z (zombie)", /* 32 */
};









 "酒店客房管理系统(Java+MySQL)")

