
文章目录
- 前言
- 一、介绍
- 1、LLaVA(多模态特征组合的简单样例)
- 2、Flamingo(cross-attention的模态交互样例)
- 3、BLIP-2(结构与策略的交互样例)
- 总结
前言
目前多模态模型席卷AI领域,最近也在做一些对齐的工作,记录一下目前主流的模态对齐方法。想详细了解的也可以看看下面的综述论文。
paper:https://arxiv.org/pdf/2311.07594
一、介绍
最近的代表性MLLM分为四类:
(1)将LLM作为多模态特征的直接处理器;
(2)利用多模态感知器的MLLM来处理多模态特征;
(3)将LLM作为处理多模态特征的工具;
(4)在特定格式的数据上学习,赋予LLM适应额外模态的能力
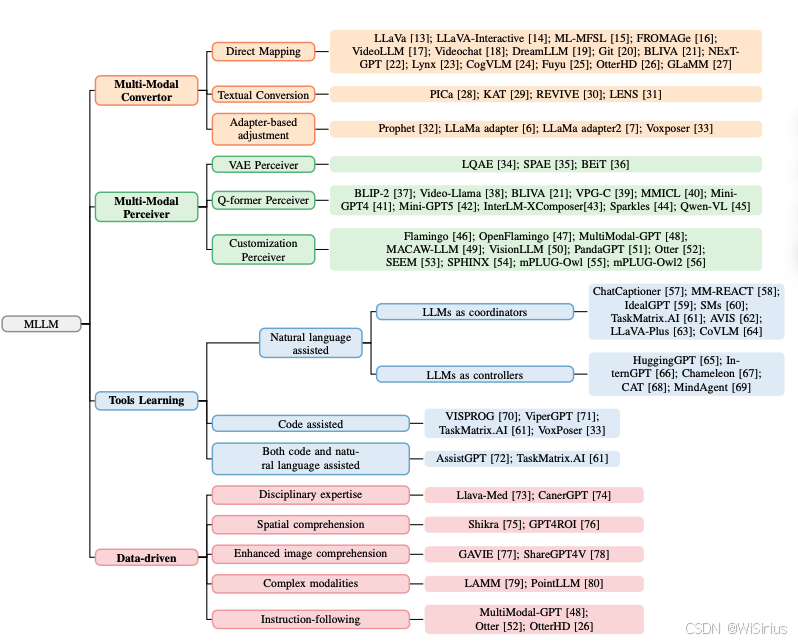
本文主要介绍目前几个完成交互的经典方法
1、LLaVA(多模态特征组合的简单样例)
LLaVA 的对齐方式相对来说比较简单,只有简单的线性层。LLaVA 的模型架构如下图所示,LLM 选择的是 Vicuna,图像编码器选择的是 CLIP 的 ViT-L/14,中间增加了一个线性层 W 将图像特征转换为跟文本 Embedding 相同维度,再一起输入到 LLM 中。
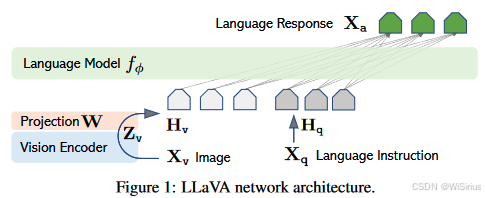
简单来说,文本内容经过embedding后输出为(1,n,c),n为文本token数量,c表示每个token的长度。图像特征经过编码器后输出为(1,n1,c1),对其特征进行重映射输出为(1,n1,c)的特征,进行concat后送入LLM。模型结构如下:
LlavaLlamaForCausalLM((model): LlavaLlamaModel((embed_tokens): Embedding(32000, 4096, padding_idx=0)(layers): ModuleList(......)(norm): LlamaRMSNorm()(vision_tower): CLIPVisionTower(......)(mm_projector): Sequential((0): Linear(in_features=1024, out_features=4096, bias=True)(1): GELU(approximate='none')(2): Linear(in_features=4096, out_features=4096, bias=True)))(lm_head): Linear(in_features=4096, out_features=32000, bias=False)
)可以发现图像特征token长度为1024,经过mm_projector后长度变为4096。
2、Flamingo(cross-attention的模态交互样例)
Flamingo 主要做的是 Caption 任务,即输入一张图片,Flamingo 可以生成图片的标题。不同的是,Flamingo 可以输入多张图片,实现上下文学习的 Few-Shot 效果。
Flamingo 的模型架构如下图所示,首先通过冻结的视觉编码器对图像进行编码,然后通过一个可训练的感知重采样器(Perceiver Resampler)重新提取特征,输出一个固定数量的视觉 tokens,这些视觉 tokens 再通过交叉注意力层被用于预训练的语言模型的每一层(LM block)。
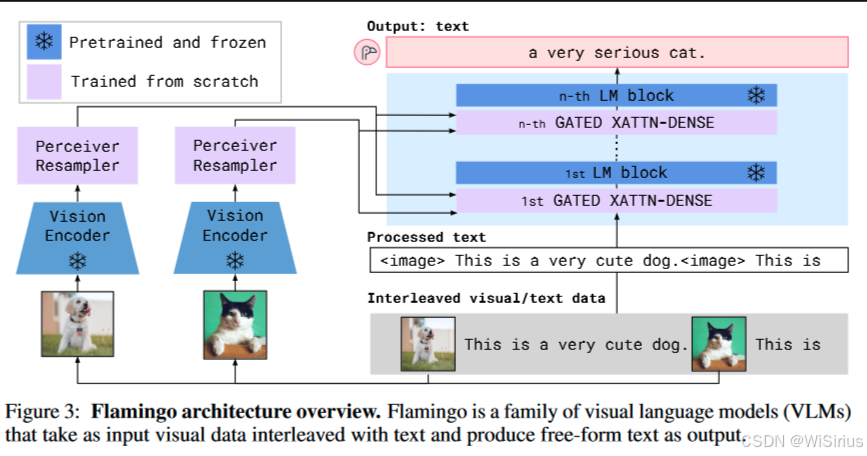
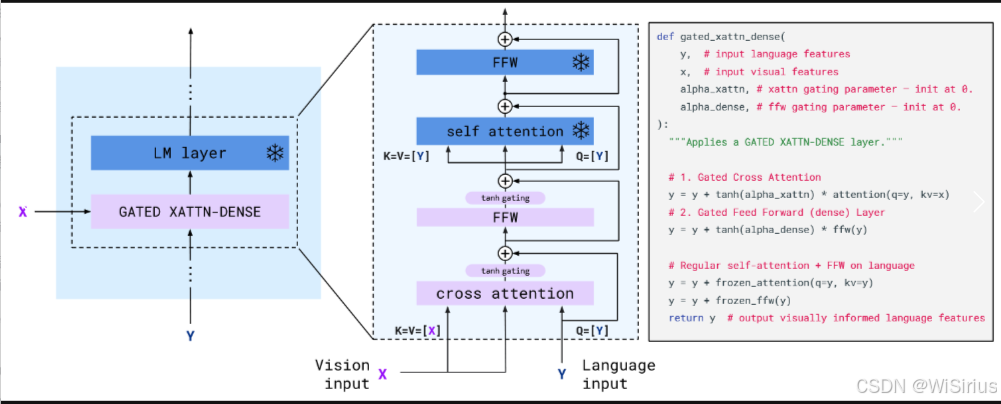
Flamingo 中插入的 Perceiver Resampler 和 GATED XATTN-DENSE 都是重新初始化的,GATED XATTN-DENSE 主要是为了根据视觉输入调整 LM,在冻结的 LM 层之间插入新的交叉注意力层。这些交叉注意力层的 keys 和 values 是从视觉特征中获得的,而 queries 则是从语言输入中获得的。交叉注意力层后面跟的是 FFW,这些层都经过了门控(gated)。(门控这个概念可以追溯到LSTM,这里采用tanh函数作为门控,tanh在LSTM中作为输入门用于保留重要信息,sigmod通常作为遗忘门, LSTM学习推荐)
Flamingo((vision_encoder): VisionTransformer(......)(perceiver): PerceiverResampler((layers): ModuleList((0-5): 6 x ModuleList((0): PerceiverAttention((norm_media): LayerNorm((1024,), eps=1e-05, elementwise_affine=True)(norm_latents): LayerNorm((1024,), eps=1e-05, elementwise_affine=True)(to_q): Linear(in_features=1024, out_features=512, bias=False)(to_kv): Linear(in_features=1024, out_features=1024, bias=False)(to_out): Linear(in_features=512, out_features=1024, bias=False))(1): Sequential((0): LayerNorm((1024,), eps=1e-05, elementwise_affine=True)(1): Linear(in_features=1024, out_features=4096, bias=False)(2): GELU(approximate='none')(3): Linear(in_features=4096, out_features=1024, bias=False))))(norm): LayerNorm((1024,), eps=1e-05, elementwise_affine=True))(lang_encoder): MosaicGPT(......(gated_cross_attn_layers): ModuleList((0-23): 24 x GatedCrossAttentionBlock((attn): MaskedCrossAttention((norm): LayerNorm((2048,), eps=1e-05, elementwise_affine=True)(to_q): Linear(in_features=2048, out_features=512, bias=False)(to_kv): Linear(in_features=1024, out_features=1024, bias=False)(to_out): Linear(in_features=512, out_features=2048, bias=False))(ff): Sequential((0): LayerNorm((2048,), eps=1e-05, elementwise_affine=True)(1): Linear(in_features=2048, out_features=8192, bias=False)(2): GELU(approximate='none')(3): Linear(in_features=8192, out_features=2048, bias=False)))))
)
可以发现,重采样器也是大量线性变换组合而成,对图像特征进行转化。
3、BLIP-2(结构与策略的交互样例)
BLIP-2 的论文中提出了一种新的视觉-语言模型预训练的方法—— Q-Former,主要分为两个阶段:① 基于冻结的图像编码器进行视觉-语言表征学习;② 基于冻结的 LLM 进行视觉-语言生成学习。Q-Former 是一个可训练的模块,通过 BERT Base 来初始化权重,用来连接冻结的图像编码器和冻结的 LLM。对于不同分辨率的图像,Q-Former 都可以通过图像编码器提取固定数量的输出特征。Q-Former 主要包括两个 Transformer 子模块,① 图像 Transformer 用于跟冻结的图像编码器交互,提取视觉特征;② 文本 Transformer 可以既作为文本编码器和文本解码器。
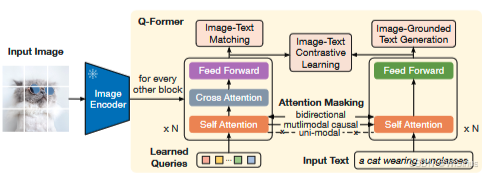
视觉-语言表征学习通过三种任务进行训练:
图文对比学习:对齐图像表征和文本表征(Image-Text contrastive learning)。
图文匹配:判断图文对是否匹配的二分类任务(image-text matching)。
基于图像的文本生成:基于图像生成标题(image-grounded text generation)。
视觉-语言生成学习:基于训练好的 Q-Former 模块和可学习的 query embeddings 提取图像特征,然后用全连接层将 Q-Former 的输出维度跟 LLM 的输入维度进行对齐,最后再输入到 LLM 中。

BLIP2结构如下:
Blip2OPT((visual_encoder): VisionTransformer(......)(ln_vision): LayerNorm((1408,), eps=1e-05, elementwise_affine=True)(Qformer): BertLMHeadModel((bert): BertModel((embeddings): BertEmbeddings((word_embeddings): None(position_embeddings): None(LayerNorm): LayerNorm((768,), eps=1e-12, elementwise_affine=True)(dropout): Dropout(p=0.1, inplace=False))(encoder): BertEncoder((layer): ModuleList((0-11): 12 x: BertLayer((attention): BertAttention((self): BertSelfAttention((query): Linear(in_features=768, out_features=768, bias=True)(key): Linear(in_features=768, out_features=768, bias=True)(value): Linear(in_features=768, out_features=768, bias=True)(dropout): Dropout(p=0.1, inplace=False))(output): BertSelfOutput((dense): Linear(in_features=768, out_features=768, bias=True)(LayerNorm): LayerNorm((768,), eps=1e-12, elementwise_affine=True)(dropout): Dropout(p=0.1, inplace=False)))(crossattention): BertAttention((self): BertSelfAttention((query): Linear(in_features=768, out_features=768, bias=True)(key): Linear(in_features=1408, out_features=768, bias=True)(value): Linear(in_features=1408, out_features=768, bias=True)(dropout): Dropout(p=0.1, inplace=False))(output): BertSelfOutput((dense): Linear(in_features=768, out_features=768, bias=True)(LayerNorm): LayerNorm((768,), eps=1e-12, elementwise_affine=True)(dropout): Dropout(p=0.1, inplace=False)))(intermediate): None(output): None(intermediate_query): BertIntermediate((dense): Linear(in_features=768, out_features=3072, bias=True)(intermediate_act_fn): GELUActivation())(output_query): BertOutput((dense): Linear(in_features=3072, out_features=768, bias=True)(LayerNorm): LayerNorm((768,), eps=1e-12, elementwise_affine=True)(dropout): Dropout(p=0.1, inplace=False))))))(cls): None)(opt_model): OPTForCausalLM(......)(opt_proj): Linear(in_features=768, out_features=2560, bias=True)
)
总结
个人觉得目前模态对齐的方法其实还是集中于第一种和第二种方法,即合并特征或使用cross-attention的方式。但是现在decoder的构建通常只使用self-attention进行完成,因此第二种方式也很少用了。












