
《博主简介》
小伙伴们好,我是阿旭。专注于人工智能、AIGC、python、计算机视觉相关分享研究。
✌更多学习资源,可关注公-仲-hao:【阿旭算法与机器学习】,共同学习交流~
👍感谢小伙伴们点赞、关注!
《------往期经典推荐------》
一、AI应用软件开发实战专栏【链接】
| 项目名称 | 项目名称 |
|---|---|
| 1.【人脸识别与管理系统开发】 | 2.【车牌识别与自动收费管理系统开发】 |
| 3.【手势识别系统开发】 | 4.【人脸面部活体检测系统开发】 |
| 5.【图片风格快速迁移软件开发】 | 6.【人脸表表情识别系统】 |
| 7.【YOLOv8多目标识别与自动标注软件开发】 | 8.【基于YOLOv8深度学习的行人跌倒检测系统】 |
| 9.【基于YOLOv8深度学习的PCB板缺陷检测系统】 | 10.【基于YOLOv8深度学习的生活垃圾分类目标检测系统】 |
| 11.【基于YOLOv8深度学习的安全帽目标检测系统】 | 12.【基于YOLOv8深度学习的120种犬类检测与识别系统】 |
| 13.【基于YOLOv8深度学习的路面坑洞检测系统】 | 14.【基于YOLOv8深度学习的火焰烟雾检测系统】 |
| 15.【基于YOLOv8深度学习的钢材表面缺陷检测系统】 | 16.【基于YOLOv8深度学习的舰船目标分类检测系统】 |
| 17.【基于YOLOv8深度学习的西红柿成熟度检测系统】 | 18.【基于YOLOv8深度学习的血细胞检测与计数系统】 |
| 19.【基于YOLOv8深度学习的吸烟/抽烟行为检测系统】 | 20.【基于YOLOv8深度学习的水稻害虫检测与识别系统】 |
| 21.【基于YOLOv8深度学习的高精度车辆行人检测与计数系统】 | 22.【基于YOLOv8深度学习的路面标志线检测与识别系统】 |
| 23.【基于YOLOv8深度学习的智能小麦害虫检测识别系统】 | 24.【基于YOLOv8深度学习的智能玉米害虫检测识别系统】 |
| 25.【基于YOLOv8深度学习的200种鸟类智能检测与识别系统】 | 26.【基于YOLOv8深度学习的45种交通标志智能检测与识别系统】 |
| 27.【基于YOLOv8深度学习的人脸面部表情识别系统】 | 28.【基于YOLOv8深度学习的苹果叶片病害智能诊断系统】 |
| 29.【基于YOLOv8深度学习的智能肺炎诊断系统】 | 30.【基于YOLOv8深度学习的葡萄簇目标检测系统】 |
| 31.【基于YOLOv8深度学习的100种中草药智能识别系统】 | 32.【基于YOLOv8深度学习的102种花卉智能识别系统】 |
| 33.【基于YOLOv8深度学习的100种蝴蝶智能识别系统】 | 34.【基于YOLOv8深度学习的水稻叶片病害智能诊断系统】 |
| 35.【基于YOLOv8与ByteTrack的车辆行人多目标检测与追踪系统】 | 36.【基于YOLOv8深度学习的智能草莓病害检测与分割系统】 |
| 37.【基于YOLOv8深度学习的复杂场景下船舶目标检测系统】 | 38.【基于YOLOv8深度学习的农作物幼苗与杂草检测系统】 |
| 39.【基于YOLOv8深度学习的智能道路裂缝检测与分析系统】 | 40.【基于YOLOv8深度学习的葡萄病害智能诊断与防治系统】 |
| 41.【基于YOLOv8深度学习的遥感地理空间物体检测系统】 | 42.【基于YOLOv8深度学习的无人机视角地面物体检测系统】 |
| 43.【基于YOLOv8深度学习的木薯病害智能诊断与防治系统】 | 44.【基于YOLOv8深度学习的野外火焰烟雾检测系统】 |
| 45.【基于YOLOv8深度学习的脑肿瘤智能检测系统】 | 46.【基于YOLOv8深度学习的玉米叶片病害智能诊断与防治系统】 |
| 47.【基于YOLOv8深度学习的橙子病害智能诊断与防治系统】 | 48.【基于深度学习的车辆检测追踪与流量计数系统】 |
| 49.【基于深度学习的行人检测追踪与双向流量计数系统】 | 50.【基于深度学习的反光衣检测与预警系统】 |
| 51.【基于深度学习的危险区域人员闯入检测与报警系统】 | 52.【基于深度学习的高密度人脸智能检测与统计系统】 |
| 53.【基于深度学习的CT扫描图像肾结石智能检测系统】 | 54.【基于深度学习的水果智能检测系统】 |
| 55.【基于深度学习的水果质量好坏智能检测系统】 | 56.【基于深度学习的蔬菜目标检测与识别系统】 |
| 57.【基于深度学习的非机动车驾驶员头盔检测系统】 | 58.【太基于深度学习的阳能电池板检测与分析系统】 |
| 59.【基于深度学习的工业螺栓螺母检测】 | 60.【基于深度学习的金属焊缝缺陷检测系统】 |
| 61.【基于深度学习的链条缺陷检测与识别系统】 | 62.【基于深度学习的交通信号灯检测识别】 |
| 63.【基于深度学习的草莓成熟度检测与识别系统】 | 64.【基于深度学习的水下海生物检测识别系统】 |
| 65.【基于深度学习的道路交通事故检测识别系统】 | 66.【基于深度学习的安检X光危险品检测与识别系统】 |
二、机器学习实战专栏【链接】,已更新31期,欢迎关注,持续更新中~~
三、深度学习【Pytorch】专栏【链接】
四、【Stable Diffusion绘画系列】专栏【链接】
五、YOLOv8改进专栏【链接】,持续更新中~~
六、YOLO性能对比专栏【链接】,持续更新中~
《------正文------》
目录
- 引言
- 为什么我们需要使用OCR的YOLO和Ollama?
- 1.训练自定义Yolo11数据集
- 2.在视频上运行边界框的自定义模型
- 3.在边界框上运行OCR
- 4.使用Ollama优化文本
- 结论
引言

该项目通过将自定义训练的YOLO11模型与EasyOCR集成并使用LLM优化结果来增强文本识别工作流程LLM。
本文将大型语言模型(LLMs)与计算机视觉结合,通过计算机视觉训练的YOLO11模型定位文本区域,之后通过OCR的文本识别之后,最终大语言模型进行识别结果优化,以获取更加准确的文本识别效果。
为什么我们需要使用OCR的YOLO和Ollama?
传统的OCR(光学字符识别)方法可以很好地从简单的图像中提取文本,但当文本与其他视觉元素交织在一起时,往往会出现问题。通过使用自定义YOLO模型首先检测文本区域等对象,我们可以隔离这些区域进行OCR,从而显著降低噪声并提高准确性。
让我们通过在没有YOLO的图像上运行一个基本的OCR示例来演示这一点,以突出单独使用OCR的挑战:

import easyocr
import cv2
# Initialize EasyOCR
reader = easyocr.Reader(['en'])
# Load the image
image = cv2.imread('book.jpg')
# Run OCR directly
results = reader.readtext(image)
# Display results
for (bbox, text, prob) in results:print(f"Detected Text: {text} (Probability: {prob})")
THE 0 R |G |NAL B E STSELLE R THE SECRET HISTORY DONNA TARTT Haunting, compelling and brilliant The Times
不是你想要的,对吧?虽然它可以很好地处理简单的图像,但当有噪音或复杂的视觉模式时,错误就会开始堆积。这就是YOLO模型介入并真正发挥作用的地方。
1.训练自定义Yolo11数据集
通过对象检测增强OCR的第一步是在数据集上训练自定义YOLO模型。YOLO(You Only Look Once)是一个强大的实时对象检测模型,它将图像划分为网格,使其能够在一次向前传递中识别多个对象。这种方法非常适合检测图像中的文本,特别是当您希望通过隔离特定区域来改善OCR结果时。

我们将使用预先标注的书籍封面数据集,并在其上训练YOLO11模型。YOLO11针对较小的对象进行了优化,使其非常适合在具有挑战性的上下文(如视频或扫描文档)中检测文本。
from ultralytics import YOLOmodel = YOLO("yolo11.pt")
# Train the model
model.train(data="datasets/data.yaml", epochs=50, imgsz=640)
在我的例子中,在Google Colab上训练这个模型花了大约六个小时50个时期。您可以调整参数,如epoch数量和数据集大小,或使用超参数进行实验,以提高模型的性能和准确性。
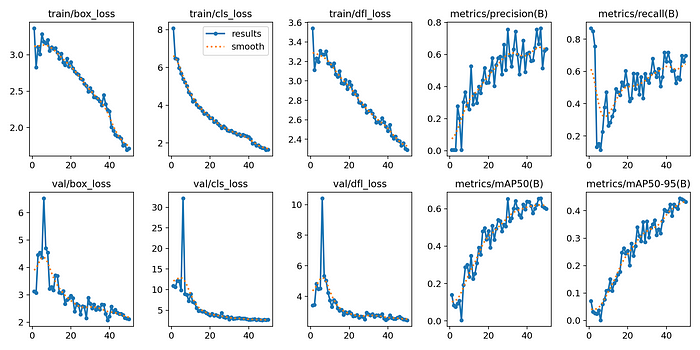
2.在视频上运行边界框的自定义模型
一旦YOLO模型经过训练,您就可以将其应用于视频,以检测文本区域周围的边界框。这些边界框隔离了感兴趣的区域,确保了更清晰的OCR过程:
import cv2
# Open video file
video_path = 'books.mov'
cap = cv2.VideoCapture(video_path)
# Load YOLO model
model = YOLO('model.pt')
# Function for object detection and drawing bounding boxes
def predict_and_detect(model, frame, conf=0.5):results = model.predict(frame, conf=conf)for result in results:for box in result.boxes:# Draw bounding boxx1, y1, x2, y2 = map(int, box.xyxy[0].tolist())cv2.rectangle(frame, (x1, y1), (x2, y2), (255, 0, 0), 2)return frame, results
# Process video frames
while cap.isOpened():ret, frame = cap.read()if not ret:break# Run object detectionprocessed_frame, results = predict_and_detect(model, frame)# Show video with bounding boxescv2.imshow('YOLO + OCR Detection', processed_frame)if cv2.waitKey(1) & 0xFF == ord('q'):break
# Release video
cap.release()
cv2.destroyAllWindows()

此代码实时处理视频,在检测到的文本周围绘制边界框,并隔离这些区域,为下一步- OCR完美地设置它们。
3.在边界框上运行OCR
现在我们已经使用YOLO隔离了文本区域,我们可以在这些特定区域内应用OCR,与在整个图像上运行OCR相比,大大提高了准确性:
import easyocr
# Initialize EasyOCR
reader = easyocr.Reader(['en'])
# Function to crop frames and perform OCR
def run_ocr_on_boxes(frame, boxes):ocr_results = []for box in boxes:x1, y1, x2, y2 = map(int, box.xyxy[0].tolist())cropped_frame = frame[y1:y2, x1:x2]ocr_result = reader.readtext(cropped_frame)ocr_results.append(ocr_result)return ocr_results
# Perform OCR on detected bounding boxes
for result in results:ocr_results = run_ocr_on_boxes(frame, result.boxes)# Extract and display the text from OCR resultsextracted_text = [detection[1] for ocr in ocr_results for detection in ocr]print(f"Extracted Text: {', '.join(extracted_text)}")
'THE, SECRET, HISTORY, DONNA, TARTT'
结果得到了显著改善,因为OCR引擎现在只处理明确识别为包含文本的区域,降低了不相关图像元素的误解风险。
4.使用Ollama优化文本
在使用easyocr提取文本之后,Llama 3可以通过改进通常不完美和混乱的结果来进一步改进。OCR功能很强大,但它仍然可能误解文本或返回无序的数据,特别是书籍标题或作者姓名。
LLM介入整理输出,将原始OCR结果转换为结构化的连贯文本。通过引导Llama 3使用特定的提示来识别和组织内容,我们可以将不完善的OCR数据细化为格式整齐的书名和作者姓名。最精彩的部分?你可以在本地使用Ollama!
import ollama
# Construct a prompt to clean up the OCR output
prompt = f"""
- Below is a text extracted from an OCR. The text contains mentions of famous books and their corresponding authors.
- Some words may be slightly misspelled or out of order.
- Your task is to identify the book titles and corresponding authors from the text.
- Output the text in the format: '<Name of the book> : <Name of the author>'.
- Do not generate any other text except the book title and the author.
TEXT:
{output_text}
"""
# Use Ollama to clean and structure the OCR output
response = ollama.chat(model="llama3",messages=[{"role": "user", "content": prompt}]
)
# Extract cleaned text
cleaned_text = response['message']['content'].strip()
print(cleaned_text)
The Secret History : Donna Tartt
完全正确!一旦LLM清理了文本,抛光输出可以存储在数据库中或在各种现实世界的应用程序中工作,例如:
- 数字图书馆或书店:自动分类和显示图书标题旁边的作者。
- 档案系统:将扫描的书籍封面或文档转换为可搜索的数字记录。
- 自动元数据生成:根据提取的信息为图像、PDF或其他数字资产生成元数据。
- 数据库输入:将清理后的文本直接插入数据库,确保大型系统的结构化和一致的数据。
通过结合对象检测、OCR和LLMs,您可以解锁一个强大的管道,实现更结构化的数据处理,非常适合需要高精度的应用程序。
结论
您可以通过将自定义训练的YOLO11模型与EasyOCR相结合并使用LLM增强结果来显着改进文本识别工作流程。LLM无论您是处理棘手的图像或视频中的文本,清理OCR混乱,还是使一切都超级精美,此管道都可以为您提供实时精确的文本提取和细化。
好了,这篇文章就介绍到这里,喜欢的小伙伴感谢给点个赞和关注,更多精彩内容持续更新~~
关于本篇文章大家有任何建议或意见,欢迎在评论区留言交流!












