
1. CBAM(Convolutional Block Attention Module)
CBAM(Convolutional Block Attention Module):是一种轻量级的注意力机制模块,用于增强卷积神经网络(CNN)的特征表示能力。它通过引入通道注意力和空间注意力机制,使网络能够自适应地关注重要的特征通道和空间区域。CBAM 由通道注意力模块(Channel Attention Module, CAM)和 空间注意力模块(Spatial Attention Module, SAM)组成,可以无缝集成到现有的 CNN 架构中。
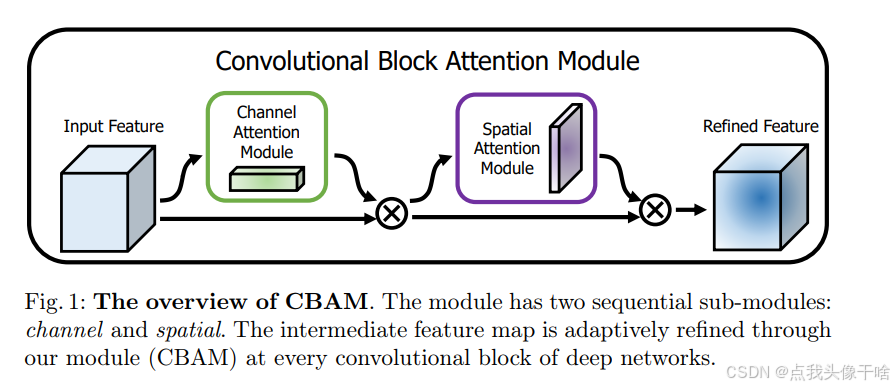
CBAM 的核心思想:
1. 通道注意力模块(CAM):关注“哪些通道的特征更重要”。通过全局平均池化和全局最大池化捕获通道间的依赖关系。使用共享的多层感知机(MLP)生成通道注意力权重。
2. 空间注意力模块(SAM):关注“特征图的哪些空间区域更重要”。通过沿通道维度计算平均和最大值,生成空间注意力图。使用卷积操作生成空间注意力权重。
3. 顺序结合:CBAM 首先应用通道注意力模块,然后应用空间注意力模块。这种顺序设计使得网络能够先关注重要的通道,再关注重要的空间区域。
CBAM 的结构:
通道注意力模块(CAM):
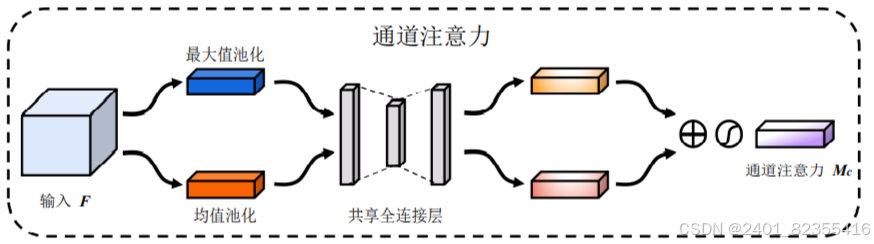
输入:特征图 F∈R(C×H×W),其中 C 是通道数,H 和 W 是空间维度。
操作:
1. 对特征图分别进行全局平均池化和全局最大池化,得到两个 C×1×1的向量。
2. 将这两个向量输入共享的 MLP(多层感知机),生成通道注意力权重。
3. 将两个权重相加并通过 Sigmoid 激活函数,得到最终的通道注意力权重Mc∈R(C×1×1)
4. 将权重 Mc与输入特征图F相乘,得到通道注意力加权的特征图。
公式:
![]()
其中,σ是 Sigmoid 激活函数。
空间注意力模块(SAM):
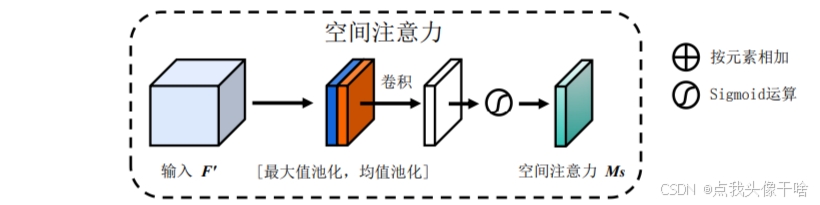
输入:经过通道注意力加权的特征图 F′∈R(C×H×W)
操作:
1. 沿通道维度计算平均值和最大值,得到两个1×H×W的特征图。
2. 将这两个特征图拼接在一起,形成2×H×W的特征图。
3. 使用一个卷积层(通常为 7×7卷积)生成空间注意力权重。
4. 通过 Sigmoid 激活函数,得到最终的空间注意力权重 Ms∈R(1×H×W)
5. 将权重 Ms 与输入特征图 F'相乘,得到空间注意力加权的特征图。
公式:
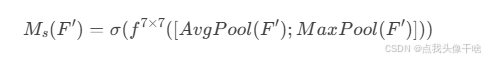
其中,f(7×7) 是 7×7卷积操作。
CBAM 的整体流程:
1. 输入特征图 F
2. 应用通道注意力模块:
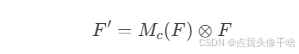
3. 应用空间注意力模块:
![]()
4. 输出加权的特征图F''
CBAM 是一种简单而有效的注意力机制模块,通过通道注意力和空间注意力的结合,显著提升了 CNN 的特征表示能力。它的轻量级设计和通用性使其成为许多视觉任务的理想选择。
2. ResNet + CBAM
将Transformer模块集成到ResNet中,通常是为了结合卷积神经网络(CNN)的局部特征提取能力和Transformer的全局建模能力。
这里添加的位置在每个残差块内部
代码如下:
import torch
import torch.nn as nn
import torch.nn.functional as Fclass ChannelAttention(nn.Module):def __init__(self, in_planes, ratio=16):super(ChannelAttention, self).__init__()self.avg_pool = nn.AdaptiveAvgPool2d(1)self.max_pool = nn.AdaptiveMaxPool2d(1)self.fc1 = nn.Conv2d(in_planes, in_planes // ratio, 1, bias=False)self.relu1 = nn.ReLU()self.fc2 = nn.Conv2d(in_planes // ratio, in_planes, 1, bias=False)self.sigmoid = nn.Sigmoid()def forward(self, x):avg_out = self.fc2(self.relu1(self.fc1(self.avg_pool(x))))max_out = self.fc2(self.relu1(self.fc1(self.max_pool(x))))out = avg_out + max_outreturn self.sigmoid(out)class SpatialAttention(nn.Module):def __init__(self, kernel_size=7):super(SpatialAttention, self).__init__()self.conv1 = nn.Conv2d(2, 1, kernel_size, padding=kernel_size//2, bias=False)self.sigmoid = nn.Sigmoid()def forward(self, x):avg_out = torch.mean(x, dim=1, keepdim=True)max_out, _ = torch.max(x, dim=1, keepdim=True)x = torch.cat([avg_out, max_out], dim=1)x = self.conv1(x)return self.sigmoid(x)class CBAM(nn.Module):def __init__(self, in_planes, ratio=16, kernel_size=7):super(CBAM, self).__init__()self.ca = ChannelAttention(in_planes, ratio)self.sa = SpatialAttention(kernel_size)def forward(self, x):x = self.ca(x) * xx = self.sa(x) * xreturn xclass BasicBlock(nn.Module):expansion = 1def __init__(self, in_planes, planes, stride=1, downsample=None):super(BasicBlock, self).__init__()self.conv1 = nn.Conv2d(in_planes, planes, kernel_size=3, stride=stride, padding=1, bias=False)self.bn1 = nn.BatchNorm2d(planes)self.relu = nn.ReLU(inplace=True)self.conv2 = nn.Conv2d(planes, planes, kernel_size=3, stride=1, padding=1, bias=False)self.bn2 = nn.BatchNorm2d(planes)self.downsample = downsampleself.stride = strideself.cbam = CBAM(planes)def forward(self, x):identity = xout = self.conv1(x)out = self.bn1(out)out = self.relu(out)out = self.conv2(out)out = self.bn2(out)out = self.cbam(out)if self.downsample is not None:identity = self.downsample(x)out += identityout = self.relu(out)return outclass ResNet(nn.Module):def __init__(self, block, layers, num_classes=1000):super(ResNet, self).__init__()self.in_planes = 64self.conv1 = nn.Conv2d(3, 64, kernel_size=7, stride=2, padding=3, bias=False)self.bn1 = nn.BatchNorm2d(64)self.relu = nn.ReLU(inplace=True)self.maxpool = nn.MaxPool2d(kernel_size=3, stride=2, padding=1)self.layer1 = self._make_layer(block, 64, layers[0])self.layer2 = self._make_layer(block, 128, layers[1], stride=2)self.layer3 = self._make_layer(block, 256, layers[2], stride=2)self.layer4 = self._make_layer(block, 512, layers[3], stride=2)self.avgpool = nn.AdaptiveAvgPool2d((1, 1))self.fc = nn.Linear(512 * block.expansion, num_classes)def _make_layer(self, block, planes, blocks, stride=1):downsample = Noneif stride != 1 or self.in_planes != planes * block.expansion:downsample = nn.Sequential(nn.Conv2d(self.in_planes, planes * block.expansion, kernel_size=1, stride=stride, bias=False),nn.BatchNorm2d(planes * block.expansion),)layers = []layers.append(block(self.in_planes, planes, stride, downsample))self.in_planes = planes * block.expansionfor _ in range(1, blocks):layers.append(block(self.in_planes, planes))return nn.Sequential(*layers)def forward(self, x):x = self.conv1(x)x = self.bn1(x)x = self.relu(x)x = self.maxpool(x)x = self.layer1(x)x = self.layer2(x)x = self.layer3(x)x = self.layer4(x)x = self.avgpool(x)x = torch.flatten(x, 1)x = self.fc(x)return xdef resnet18_cbam(num_classes=1000):return ResNet(BasicBlock, [2, 2, 2, 2], num_classes=num_classes)model = resnet18_cbam(num_classes=5)
print(model)x = torch.randn(1, 3, 224, 224)
output = model(x)
print(output.shape) # 输出: torch.Size([1, 5])输出如下:
ResNet(
(conv1): Conv2d(3, 64, kernel_size=(7, 7), stride=(2, 2), padding=(3, 3), bias=False)
(bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(maxpool): MaxPool2d(kernel_size=3, stride=2, padding=1, dilation=1, ceil_mode=False)
(layer1): Sequential(
(0): BasicBlock(
(conv1): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(conv2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(cbam): CBAM(
(ca): ChannelAttention(
(avg_pool): AdaptiveAvgPool2d(output_size=1)
(max_pool): AdaptiveMaxPool2d(output_size=1)
(fc1): Conv2d(64, 4, kernel_size=(1, 1), stride=(1, 1), bias=False)
(relu1): ReLU()
(fc2): Conv2d(4, 64, kernel_size=(1, 1), stride=(1, 1), bias=False)
(sigmoid): Sigmoid()
)
(sa): SpatialAttention(
(conv1): Conv2d(2, 1, kernel_size=(7, 7), stride=(1, 1), padding=(3, 3), bias=False)
(sigmoid): Sigmoid()
)
)
)
(1): BasicBlock(
(conv1): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(conv2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(cbam): CBAM(
(ca): ChannelAttention(
(avg_pool): AdaptiveAvgPool2d(output_size=1)
(max_pool): AdaptiveMaxPool2d(output_size=1)
(fc1): Conv2d(64, 4, kernel_size=(1, 1), stride=(1, 1), bias=False)
(relu1): ReLU()
(fc2): Conv2d(4, 64, kernel_size=(1, 1), stride=(1, 1), bias=False)
(sigmoid): Sigmoid()
)
(sa): SpatialAttention(
(conv1): Conv2d(2, 1, kernel_size=(7, 7), stride=(1, 1), padding=(3, 3), bias=False)
(sigmoid): Sigmoid()
)
)
)
)
(layer2): Sequential(
(0): BasicBlock(
(conv1): Conv2d(64, 128, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(conv2): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(downsample): Sequential(
(0): Conv2d(64, 128, kernel_size=(1, 1), stride=(2, 2), bias=False)
(1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
(cbam): CBAM(
(ca): ChannelAttention(
(avg_pool): AdaptiveAvgPool2d(output_size=1)
(max_pool): AdaptiveMaxPool2d(output_size=1)
(fc1): Conv2d(128, 8, kernel_size=(1, 1), stride=(1, 1), bias=False)
(relu1): ReLU()
(fc2): Conv2d(8, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(sigmoid): Sigmoid()
)
(sa): SpatialAttention(
(conv1): Conv2d(2, 1, kernel_size=(7, 7), stride=(1, 1), padding=(3, 3), bias=False)
(sigmoid): Sigmoid()
)
)
)
(1): BasicBlock(
(conv1): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(conv2): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(cbam): CBAM(
(ca): ChannelAttention(
(avg_pool): AdaptiveAvgPool2d(output_size=1)
(max_pool): AdaptiveMaxPool2d(output_size=1)
(fc1): Conv2d(128, 8, kernel_size=(1, 1), stride=(1, 1), bias=False)
(relu1): ReLU()
(fc2): Conv2d(8, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(sigmoid): Sigmoid()
)
(sa): SpatialAttention(
(conv1): Conv2d(2, 1, kernel_size=(7, 7), stride=(1, 1), padding=(3, 3), bias=False)
(sigmoid): Sigmoid()
)
)
)
)
(layer3): Sequential(
(0): BasicBlock(
(conv1): Conv2d(128, 256, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(downsample): Sequential(
(0): Conv2d(128, 256, kernel_size=(1, 1), stride=(2, 2), bias=False)
(1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
(cbam): CBAM(
(ca): ChannelAttention(
(avg_pool): AdaptiveAvgPool2d(output_size=1)
(max_pool): AdaptiveMaxPool2d(output_size=1)
(fc1): Conv2d(256, 16, kernel_size=(1, 1), stride=(1, 1), bias=False)
(relu1): ReLU()
(fc2): Conv2d(16, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(sigmoid): Sigmoid()
)
(sa): SpatialAttention(
(conv1): Conv2d(2, 1, kernel_size=(7, 7), stride=(1, 1), padding=(3, 3), bias=False)
(sigmoid): Sigmoid()
)
)
)
(1): BasicBlock(
(conv1): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(cbam): CBAM(
(ca): ChannelAttention(
(avg_pool): AdaptiveAvgPool2d(output_size=1)
(max_pool): AdaptiveMaxPool2d(output_size=1)
(fc1): Conv2d(256, 16, kernel_size=(1, 1), stride=(1, 1), bias=False)
(relu1): ReLU()
(fc2): Conv2d(16, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(sigmoid): Sigmoid()
)
(sa): SpatialAttention(
(conv1): Conv2d(2, 1, kernel_size=(7, 7), stride=(1, 1), padding=(3, 3), bias=False)
(sigmoid): Sigmoid()
)
)
)
)
(layer4): Sequential(
(0): BasicBlock(
(conv1): Conv2d(256, 512, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(conv2): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(downsample): Sequential(
(0): Conv2d(256, 512, kernel_size=(1, 1), stride=(2, 2), bias=False)
(1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
(cbam): CBAM(
(ca): ChannelAttention(
(avg_pool): AdaptiveAvgPool2d(output_size=1)
(max_pool): AdaptiveMaxPool2d(output_size=1)
(fc1): Conv2d(512, 32, kernel_size=(1, 1), stride=(1, 1), bias=False)
(relu1): ReLU()
(fc2): Conv2d(32, 512, kernel_size=(1, 1), stride=(1, 1), bias=False)
(sigmoid): Sigmoid()
)
(sa): SpatialAttention(
(conv1): Conv2d(2, 1, kernel_size=(7, 7), stride=(1, 1), padding=(3, 3), bias=False)
(sigmoid): Sigmoid()
)
)
)
(1): BasicBlock(
(conv1): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(conv2): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(cbam): CBAM(
(ca): ChannelAttention(
(avg_pool): AdaptiveAvgPool2d(output_size=1)
(max_pool): AdaptiveMaxPool2d(output_size=1)
(fc1): Conv2d(512, 32, kernel_size=(1, 1), stride=(1, 1), bias=False)
(relu1): ReLU()
(fc2): Conv2d(32, 512, kernel_size=(1, 1), stride=(1, 1), bias=False)
(sigmoid): Sigmoid()
)
(sa): SpatialAttention(
(conv1): Conv2d(2, 1, kernel_size=(7, 7), stride=(1, 1), padding=(3, 3), bias=False)
(sigmoid): Sigmoid()
)
)
)
)
(avgpool): AdaptiveAvgPool2d(output_size=(1, 1))
(fc): Linear(in_features=512, out_features=5, bias=True)
)
torch.Size([1, 5])











 "开源cms建站_橙子建站是诈骗平台吗_昆山网站制作哪家好_新闻热点事件2021(最新)")
