
文章目录
- Flink基础
- 今日课程内容介绍
- Flink的容错机制
- 为什么需要容错机制
- Flink 的精确一次
- Flink的eos要点
- Flink checkpoint机制
- 分布式Checkpoint的难题
- Checkpoint的核心要点
- Checkpoint的整体流程
- 对齐与非对齐checkpoint
- checkpoint相关参数和API
- 状态后端
- 基础概念
- MemoryStateBackend
- FsStateBackend
- RocksDBStateBackend
- sink端容错机制
- 幂等写入方式
- 两阶段事务写入
- 核心流程
- 代码示例
- 优缺点
- Flink的容错配置及测试
- Task级失败重启恢复状态
- Task失败的自动重启策略
- Failover-strategy策略
- 案例演示
- 模拟异常的代码
- Checkpoint配置和重启策略的配置
- 演示none重启策略
- 演示fixed-delay重启策略
- 演示failure-rate重启策略
- exponential-delay重启策略
- 案例演示
- 模拟异常的代码
- Checkpoint配置和重启策略的配置
- 演示none重启策略
- 演示fixed-delay重启策略
- 演示failure-rate重启策略
- exponential-delay重启策略
- Cluster级失败重启恢复状态
- save points概念
- savepoints操作命令
- 从savepoints恢复注意要点
- 从savepoint恢复时,快照数据的重分配问题
- 容错测试案例
- Flink程序分布式部署运行
- Flink架构体系
- Yarn模式安装部署
- 前提
- 部署方式
- Yarn-session模式
- Per-job模式
- Application模式
- Yarn三种模式总结
- 任务提交流程
- 抽象级别
- 具体模式下任务提交
- Standalone模式下的任务提交
- Yarn-session模式下的任务提交
- per-job模式下的任务提交
Flink基础
今日课程内容介绍
- Flink的容错机制
- Flink的Checkpoint机制
- Sink端容错机制
- Flink的容错配置及测试
- Flink程序分布式部署运行
Flink的容错机制
为什么需要容错机制
Flink是一个stateful(带状态)的数据处理系统;系统在处理数据的过程中,各算子所记录的状态会随着数据的处理而不断变化;
一旦系统崩溃,需要重启后能够恢复出崩溃前的状态才能进行数据的接续处理;因此,必须要一种机制能对系统内的各种状态进行持久化容错;
Flink 的精确一次
Exactly-Once 语义:指端到端的一致性,从数据读取、引擎计算、写入外部存储的整个过程中,即使机器或软件出现故障,都确保数据仅处理一次,不会重复、也不会丢失。
对于flink程序来说,端到端EOS语义则包含source、state、sink三个环节的紧密配合

Flink的eos要点
要实现端到端的EOS保证,核心点在于:
一条(或者一批)数据,从 注入系统、中间处理、到输出结果的整个流程中,要么每个环节都处理成功,要么失败回滚(回到从未处理过的状态)!
Flink在目前的各类分布式计算引擎中,对EOS的支持是最完善的;
在合理的数据源选择,合理的算子选择,合理的目标存储系统选择,合适的参数配置下,可以实现严格意义上的端到端EOS
source端的保证:
Flink的很多source算子都能为EOS提供保障,如kafka Source :
- 能够记录偏移量
- 能够重放数据
- 将偏移量记录在state中,与下游的其他算子的state一起,经由checkpoint机制实现了“状态数据的”快照统一
算子状态的EOS语义保证:
基于分布式快照算法:(Chandy-Lamport),flink实现了整个数据流中各算子的状态数据快照统一;
既:一次checkpoint后所持久化的各算子的状态数据,确保是经过了相同数据的影响;
这样一来,就能确保:
-
一条(或一批)数据要么是经过了完整正确处理;
-
如果这条(批)数据在中间任何过程失败,则重启恢复后,所有算子的state数据都能回到这条数据从未处理过时的状态
sink端的保证:
从前文所述的source端和内部state的容错机制来看,一批数据如果在sink端写出过程中失败(可能已经有一部分数据进入目标存储系统),则重启后重放这批数据时有可能造成目标存储系统中出现数据重复,从而破坏EOS;
对此,flink中也设计了相应机制来确保EOS
-
采用幂等写入方式
-
采用两阶段提交(2PC,two phase)事务写入方式
-
采用预写日志2PC提交方式
Flink checkpoint机制
分布式Checkpoint的难题
由于flink是一个分布式的系统,数据在流经系统中各个算子时,是有先后顺序的;换个角度来说就是:整个系统对一条数据的处理过程,并不是一个原子性的过程;
这样一来,对系统中各算子的状态进行持久化(快照),就成了一件棘手的事情;
来看如下数据处理场景:
-
算子1: 从kafka中读取数据,并在状态中记录消费位移
-
算子2: 对流入的整数进行累加,并输出累加结果
-
算子3: 对流入是整数进行累加,并输出累加结果
先注意观察正常情况下,整个系统的各算子状态变化及最终输出结果

出于容错考虑,需要在某个时机对整个系统各个算子的状态数据进行快照持久化,如下:

系统重启后加载快照数据,恢复各算子崩溃前的状态,但是会发现,处理结果相对正常时完全错误:

从最终结果来看,整个计算
-
丢失了数据2的结果
-
数据3则因为内部状态的紊乱而产生了错误的结果
Checkpoint的核心要点
checkpoint是flink内部对状态数据的快照机制;
flink的checkpoint机制是源于 Chandy-Lamport 算法(分布式快照算法);
底层逻辑:通过插入序号单调递增的barrier,把无界数据流划分成逻辑上的数据批(段),并通过段落标记(barrier)来为这段数据的处理,加持"事务(transaction)" 特性:
-
每一段数据流要么被完整成功处理;
-
要么回滚一切不完整的影响(状态变化);
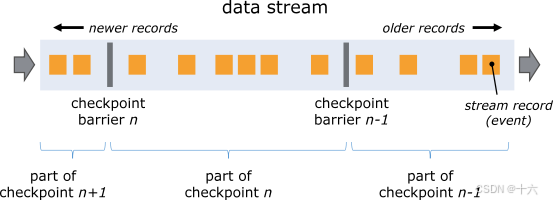
Checkpoint的整体流程
-
JobMaster 即 CheckpointCoordinator 会定期向每个 source task发送命令 start checkpoint(trigger checkpoint);
-
当 source task 收到 trigger checkpoint 指令后,产生 barrier 并通过广播的方式发送到下游。source task 及所有其他task,收到barrier-n,会执行本地 checkpoint-n,当 checkpoint-n 完成后,向 JobMaster 发送 ack;
-
当流图的所有节点都完成 checkpoint-n,JobMaster会收到所有节点的 ack,那么就表示完成 checkpoint-n,随即就会向所有task广播一条checkpoint-n全部完成的通知消息;

说明:checkpoint 机制的调用流程实质是 2PC。JobMaster 是协调者,所有operator task 是执行者。start checkpoint 是 pre-commit 的开始信号,而每个 operator task 的 checkpoint 是 pre-commit 过程,ack 是执行者 operator task 反馈给协调者 JobMaster ,最后 callback 是 commit。
1)Barrier 会在数据流源头被注人并行数据流中
Barrier-n 所在的位置就是恢复时数据重新处理的起始位置。 例如,在 Kafka 中,这个位置就是最后一个记录在分区内的消费位移 ( offset) ,作业恢复时,会根据这个位置从这个偏移量向kafka 请求数据,这个偏移量就是 State 中保存的内容之一。
2)Barrier 接着向下游传递
当一个非数据源算子从所有的输入流中收到Barrier-n时,该算子就会对自己的 State 保存快照,并向自己的下游 广播 发送Barrier-n ;
3)一旦 Sink 算子接收到 Barrier ,有两种情况
(1)如果是引擎内严格一次处理保证,当 Sink 算子已经收到了所有上游的Barrie-n 时, Sink 算子对自己的 State 进行快照,然后通知检查点协调器( CheckpointCoordinator) 。当所有的算子都向检查点协调器汇报成功之后,检查点协调器向所有的算子确认本次快照完成。
(2)如果是端到端严格一次处理保证,当 Sink 算子已经收到了所有上游的Barrie-n 时, Sink算子对自己的 State 进行快照,并预提交事务(两阶段提交的第一阶段),再通知检查点协调器( CheckpointCoordinator) ,检查点协调器向所有的算子确认本次快照完成,Sink 算子提交事务(两阶段提交的第二阶段),本次事务完成;

- 对于每个并行数据源,记录快照启动时该流中的偏移量 / 位置。
- 对于每个操作符,有一个指针指向作为快照一部分存储的状态。
对齐与非对齐checkpoint
对齐的checkpoint
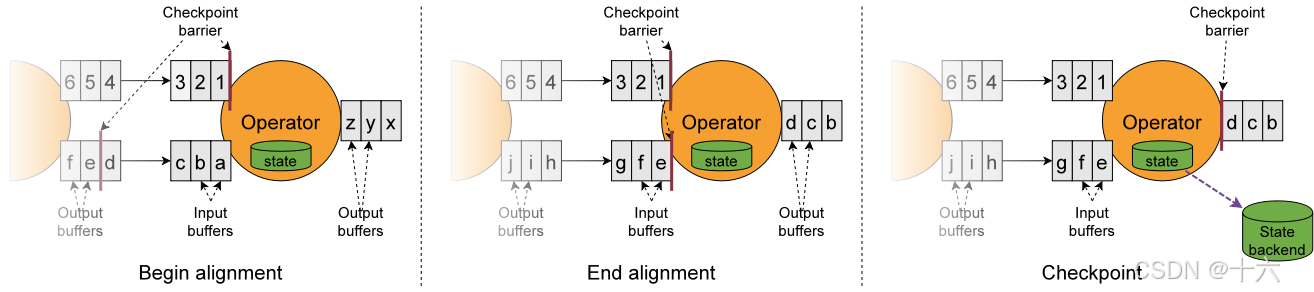
-
算子收到数字流 Barrier,字母流对应barrier 尚未到达 ;
-
算子收到数字流 Barrier,会继续从数字流中接收数据,但这些流只能被搁置,记录不能被处理,而是放入缓存中,等待字母流 Barrier 到达。在字母流到达前, 1,2,3 数据已经被缓存。
-
字母流到达,算子开始对齐 State 进行异步快照,并将 Barrier 向下游广播,并不等待快照完毕。
-
算子做异步快照,首先处理缓存中积压数据,然后再从输入通道中获取数据。
非对齐的checkpoint

barrier 不对齐:就是指当还有其他流的 barrier 还没到达时,为了不影响性能,也不用理会,直接处理 barrier 之后的数据。等到所有流的 barrier 的都到达后,就可以对该Operator做CheckPoint了;
如果不对齐,那么在chk-100快照之前,已经处理了一些chk-100对应的offset之后的数据,当程序从chk-100恢复任务时,chk-100 对应的 offset之后的数据还会被处理一次,所以就出现了重复消费。
checkpoint相关参数和API
env.enableCheckpointing(3000); // 传入的参数是checkpoint的间隔时间
// 指定checkpoint数据的存储位置
env.getCheckpointConfig().setCheckpointStorage(new Path("hdfs://node1:8020/flink-jobs-checkpoints/")); // 容许checkpoint失败的最大次数
env.getCheckpointConfig().setTolerableCheckpointFailureNumber(10); // checkpoint的算法模式(是否需要对齐)
env.getCheckpointConfig().setCheckpointingMode(CheckpointingMode.EXACTLY_ONCE); // job取消时是否保留checkpoint数据
env.getCheckpointConfig().setExternalizedCheckpointCleanup(CheckpointConfig.ExternalizedCheckpointCleanup.RETAIN_ON_CANCELLATION); // 设置checkpoint对齐的超时时间
env.getCheckpointConfig().setAlignedCheckpointTimeout(Duration.ofMillis(2000)); // 两次checkpoint的最小间隔时间,为了防止两次checkpoint的间隔时间太短
env.getCheckpointConfig().setCheckpointInterval(2000); // 最大并行的checkpoint数
env.getCheckpointConfig().setMaxConcurrentCheckpoints(3); // 要用状态,最好还要指定状态后端(默认是HashMapStateBackend)
env.setStateBackend(new EmbeddedRocksDBStateBackend());
状态后端
基础概念
状态后端的基本概念
-
所谓状态后端,就是状态数据的存储管理实现,包含状态数据的本地读写、快照远端存储功能;
-
状态后端是可插拔替换的,它对上层屏蔽了底层的差异,因为在更换状态后端时,用户的代码不需要做任何更改;

可用的状态后端类型
-
HashMapStateBackend
-
EmbeddedRocksDBStateBackend
Fsstatebackend和MemoryStatebackend整合成了HashMapStateBackend
而且HashMapStateBackend和EmBeddedRocksDBStateBackend所生成的快照文件也统一了格式,因而在job重新部署或者版本升级时,可以任意替换statebackend
如需使用rocksdb-backend,需要引入依赖
<dependency><groupId>org.apache.flink</groupId><artifactId>flink-statebackend-rocksdb</artifactId><version>${flink.version}</version>
</dependency>
状态后端的配置代码
- 可以在代码中设置
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setStateBackend(...);
- 可以在配置文件 flink-conf.yaml 中配置
# The backend that will be used to store operator state checkpoints
state.backend: hashmap# Directory for storing checkpoints
state.checkpoints.dir: hdfs://node1:8020/flink/checkpoints
MemoryStateBackend
内存,掉电易失。不安全。基本不用。

配置如下:
state.backend: hashmap
# 可选,当不指定 checkpoint 路径时,默认自动使用 JobManagerCheckpointStorage
state.checkpoint-storage: jobmanager
FsStateBackend
FsStateBackend,文件系统的状态后端,就是把状态保存在文件系统中,常用来保存状态的文件系统有HDFS。
工作中常用。

配置如下:
state.backend: hashmap
state.checkpoints.dir: file:///checkpoint-dir/ # 默认为FileSystemCheckpointStorage
state.checkpoint-storage: filesystem
RocksDBStateBackend
RocksDBStateBackend,把状态保存在RocksDB数据库中。
RocksDB,是一个小型文件系统的数据库。

配置如下:
state.backend: rocksdb
state.checkpoints.dir: file:///checkpoint-dir/# Optional, Flink will automatically default to FileSystemCheckpointStorage
# when a checkpoint directory is specified.
state.checkpoint-storage: filesystem
可以保持巨大的状态,且支持增量状态保存。
sink端容错机制
幂等写入方式
Sink端主要的问题是,作业失败重启时,数据重放可能造成最终目标存储中被写入了重复数据;
如果目标存储系统支持幂等写入,且数据中有合适的key(主键),则flink的sink端完全可以利用目标系统的幂等写入特点,来实现数据的最终一致(精确一次);
只是,幂等写入的方式,能实现最终一致,但依然存在弊端:
-
“过程中的不一致”
-
可能导致下游数据消费者出现脏读;
注: 动态过程不一致,主要出现在“输出结果非确定”的计算场景中,如,
输入: guid, event_id, event_cout
输出: guid, event_id, event_cout, insert_time(数据插入的时间或者随机数)
则重复写入guid,event_id相同的两次数据时,第一次的值和后面覆盖的值,是发生了变化的
两阶段事务写入
核心流程
Flink中的两阶段事务提交sink,主要是利用了上述的“checkpoint两阶段提交协议”和目标存储系统的事务支持机制(比如mysql等);
Flink中两阶段事务提交的核心过程如下:
-
Sink算子在一批数据处理过程中,先通过预提交事务开始对外输出数据
-
待这批数据处理完成(即收到了checkpoint信号)后,向checkpoint coordinator上报自身checkpoint完成信息
-
checkpoint coordinator收到所有算子任务的checkpoint完成信息后,再向各算子任务广播本次checkpoint全局完成信息
-
两阶段事务提交sink算子收到checkpoint coordinator的回调信息时,执行事务commit操作;


代码示例
Flink为开发者设计了两阶段事务提交的sink算子接口(TwoPhaseCommitSinkFunction);
用户通过实现该接口,即可获得一个实现了两阶段事务提交机制的sink算子;
代码示例如下:
import lombok.AllArgsConstructor;
import lombok.Data;
import lombok.NoArgsConstructor;
import org.apache.flink.api.common.eventtime.SerializableTimestampAssigner;
import org.apache.flink.api.common.eventtime.WatermarkStrategy;
import org.apache.flink.api.common.functions.MapFunction;
import org.apache.flink.api.common.state.ListState;
import org.apache.flink.api.common.state.ListStateDescriptor;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.api.java.typeutils.TypeExtractor;
import org.apache.flink.runtime.state.FunctionInitializationContext;
import org.apache.flink.runtime.state.FunctionSnapshotContext;
import org.apache.flink.streaming.api.checkpoint.CheckpointedFunction;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.sink.TwoPhaseCommitSinkFunction;
import org.apache.flink.streaming.api.functions.source.RichParallelSourceFunction;
import org.apache.flink.streaming.api.functions.source.SourceFunction;
import org.apache.flink.streaming.api.functions.timestamps.BoundedOutOfOrdernessTimestampExtractor;
import org.apache.flink.streaming.api.functions.windowing.AllWindowFunction;
import org.apache.flink.streaming.api.windowing.time.Time;
import org.apache.flink.streaming.api.windowing.windows.TimeWindow;
import org.apache.flink.util.Collector;
import org.apache.flink.util.Preconditions;import java.io.BufferedWriter;
import java.io.IOException;
import java.io.Serializable;
import java.nio.file.Files;
import java.nio.file.Path;
import java.nio.file.Paths;
import java.time.Duration;
import java.time.Instant;
import java.time.LocalDateTime;
import java.time.ZoneId;
import java.time.format.DateTimeFormatter;
import java.util.*;public class TransactionSinkExample {/*** 主入口方法,设置流处理环境并执行数据处理逻辑。** @param args 命令行参数* @throws Exception 可能抛出的异常*/public static void main(String[] args) throws Exception {// 设置流处理执行环境final StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();//为了方便观察设置并行度为1env.setParallelism(1);// 配置检查点,每10秒进行一次检查点env.getCheckpointConfig().setCheckpointInterval(10 * 1000);// 使用事件时间作为应用的时间特性env.setStreamTimeCharacteristic(org.apache.flink.streaming.api.TimeCharacteristic.EventTime);// 配置水印间隔env.getConfig().setAutoWatermarkInterval(1000L);// 摄入传感器数据流DataStream<SensorReading> sensorData = env// 添加生成随机温度读数的源.addSource(new ResettableSensorSource())// 分配时间戳和水印,这是事件时间处理所必需的.assignTimestampsAndWatermarks(WatermarkStrategy//设置最大乱序时间为 5 秒。.<SensorReading>forBoundedOutOfOrderness(Duration.ofSeconds(5)).withTimestampAssigner(new SerializableTimestampAssigner<SensorReading>() {/*** 从 SensorReading 对象中提取时间戳。** @param r SensorReading 对象* @return 提取的时间戳*/@Overridepublic long extractTimestamp(SensorReading r, long recordTimestamp) {return r.getTimestamp();}}));// 计算所有传感器每秒的平均温度DataStream<Tuple2<String, Double>> avgTempDataStream = sensorData.timeWindowAll(Time.seconds(1)).apply(new AllWindowFunction<SensorReading, Tuple2<String, Double>, TimeWindow>() {@Overridepublic void apply(TimeWindow w, Iterable<SensorReading> vals, Collector<Tuple2<String, Double>> out) throws Exception {double sum = 0.0;int count = 0;for (SensorReading reading : vals) {sum += reading.getTemperature();count++;}double avgTemp = sum / count;// 将窗口结束时间格式化为ISO时间字符串long epochSeconds = w.getEnd() / 1000;String tString = LocalDateTime.ofInstant(Instant.ofEpochSecond(epochSeconds), ZoneId.of("UTC")).format(DateTimeFormatter.ISO_LOCAL_DATE_TIME);out.collect(new Tuple2<>(tString, avgTemp));}})// 生成失败以触发作业恢复.map(new FailingMapper<Tuple2<String, Double>>(16)).setParallelism(1);// 选项1(注释掉以禁用)// --------// 使用事务性sink将结果写入文件。// 结果在检查点完成时提交。Path targetDir = Paths.get(createAndGetPaths()[0]);Path transactionDir = Paths.get(createAndGetPaths()[1]);System.out.println("targetDir:" + targetDir);System.out.println("transactionDir:" + transactionDir);avgTempDataStream.addSink(new TransactionalFileSink<>(targetDir.toString(), transactionDir.toString()));// 选项2(取消注释以启用)// --------// 将结果打印到标准输出,不使用预写日志。// 结果在生成时立即打印,并在发生故障时重新发送。// avgTemp.print()// // 强制顺序写入// .setParallelism(1);// 执行流处理作业env.execute();}/*** 创建并获取事务文件接收器的临时路径。*/private static String[] createAndGetPaths() throws IOException {// 获取系统临时目录String tempDir = System.getProperty("java.io.tmpdir");// 定义目标目录路径String targetDir = tempDir + "/committed";// 定义事务目录路径String transactionDir = tempDir + "/transaction";// 将字符串路径转换为Path对象Path targetPath = Paths.get(targetDir);Path transactionPath = Paths.get(transactionDir);// 如果目标目录不存在,则创建目标目录if (!Files.exists(targetPath)) {Files.createDirectory(targetPath);}// 如果事务目录不存在,则创建事务目录if (!Files.exists(transactionPath)) {Files.createDirectory(transactionPath);}// 返回目标目录和事务目录的路径数组return new String[]{targetDir, transactionDir};}/*** 一个映射器类,在处理一定数量的记录后失败,用于演示输出一致性。** @param <IN> 输入数据的类型。*/private static class FailingMapper<IN> implements MapFunction<IN, IN> {// 失败间隔,即在抛出异常之前转发的记录数。private final int failInterval;// 已处理的记录计数器private int cnt = 0;/*** 构造函数,设置在失败前转发的记录数。** @param failInterval 在抛出异常之前转发的记录数。*/public FailingMapper(int failInterval) {this.failInterval = failInterval;}@Overridepublic IN map(IN value) throws Exception {cnt += 1;// 检查失败条件if (cnt > failInterval) {throw new RuntimeException("应用程序失败以演示输出一致性。");}// 转发值return value;}}/*** 可重置传感器数据源类,继承自 {@link RichParallelSourceFunction} 并实现 {@link CheckpointedFunction} 接口。* 该类用于生成传感器读数数据,并支持从上次检查点恢复状态。*/private static class ResettableSensorSource extends RichParallelSourceFunction<SensorReading> implements CheckpointedFunction {/*** 标记表示数据源是否仍在运行。*/private volatile boolean running = true;/*** 最后一次发出的传感器读数。*/private SensorReading[] readings;/*** 用于检查点的传感器状态。*/private transient ListState<SensorReading> sensorsState;/*** 运行方法,持续生成并发出传感器读数,直到被取消。** @param srcCtx 源上下文,用于发出数据* @throws Exception 如果发生异常*/@Overridepublic void run(SourceFunction.SourceContext<SensorReading> srcCtx) throws Exception {// 初始化随机数生成器。Random rand = new Random();// 持续生成数据,直到被取消。while (running) {// 获取检查点锁,确保在检查点期间不会发出数据。synchronized (srcCtx.getCheckpointLock()) {// 发出所有传感器的读数。for (int i = 0; i < readings.length; i++) {// 获取当前读数。SensorReading reading = readings[i];// 更新时间戳和温度。long newTime = reading.getTimestamp() + 100;// 设置种子以生成确定性的温度。rand.setSeed(newTime ^ (long) reading.getTemperature());double newTemp = reading.getTemperature() + (rand.nextGaussian() * 0.5);SensorReading newReading = new SensorReading(reading.getId(), newTime, newTemp);// 存储新的读数并发出。readings[i] = newReading;srcCtx.collect(newReading);}}// 等待100毫秒。Thread.sleep(100);}}/*** 取消方法,停止数据生成。*/@Overridepublic void cancel() {running = false;}/*** 初始化状态方法,从检查点恢复状态或初始化初始数据。** @param context 函数初始化上下文* @throws Exception 如果发生异常*/@Overridepublic void initializeState(FunctionInitializationContext context) throws Exception {// 定义操作符状态为联合列表状态。this.sensorsState = context.getOperatorStateStore().getUnionListState(new ListStateDescriptor<>("sensorsState", SensorReading.class));// 获取状态迭代器。Iterator<SensorReading> sensorsStateIt = sensorsState.get().iterator();if (!sensorsStateIt.hasNext()) {// 状态为空,这是第一次运行。// 创建初始传感器数据。Random rand = new Random();int numTasks = getRuntimeContext().getNumberOfParallelSubtasks();int thisTask = getRuntimeContext().getIndexOfThisSubtask();long curTime = Calendar.getInstance().getTimeInMillis();// 初始化传感器ID和温度。this.readings = new SensorReading[10];for (int i = 0; i < 10; i++) {int idx = thisTask + i * numTasks;String sensorId = "sensor_" + idx;double temp = 65 + rand.nextGaussian() * 20;readings[i] = new SensorReading(sensorId, curTime, temp);}} else {// 选择此任务要处理的传感器。int numTasks = getRuntimeContext().getNumberOfParallelSubtasks();int thisTask = getRuntimeContext().getIndexOfThisSubtask();List<SensorReading> allReadings = new ArrayList<>();while (sensorsStateIt.hasNext()) {allReadings.add(sensorsStateIt.next());}this.readings = allReadings.stream().filter(reading -> (allReadings.indexOf(reading) % numTasks == thisTask)).toArray(SensorReading[]::new);}}/*** 快照状态方法,保存当前的传感器读数状态。** @param context 函数快照上下文* @throws Exception 如果发生异常*/@Overridepublic void snapshotState(FunctionSnapshotContext context) throws Exception {// 替换传感器状态为当前读数。List list = new ArrayList<>();for (SensorReading reading : readings) {list.add(reading);}sensorsState.update(list);}}/*** 事务文件接收器类,继承自 TwoPhaseCommitSinkFunction,用于将数据以事务方式写入文件。** @param <T> 泛型类型,表示要写入的数据类型*/private static class TransactionalFileSink<T> extends TwoPhaseCommitSinkFunction<T, String, Void> {/*** 目标路径,最终文件存储的位置*/private final String targetPath;/*** 临时路径,事务文件存储的位置*/private final String tempPath;/*** 缓冲写入器,用于写入事务文件*/private BufferedWriter transactionWriter;/*** 构造函数,初始化目标路径和临时路径** @param targetPath 目标路径* @param tempPath 临时路径*/public TransactionalFileSink(String targetPath, String tempPath) {super(TypeExtractor.getForClass(String.class).createSerializer(new org.apache.flink.api.common.ExecutionConfig()),TypeExtractor.getForClass(Void.class).createSerializer(new org.apache.flink.api.common.ExecutionConfig()));this.targetPath = Preconditions.checkNotNull(targetPath);this.tempPath = Preconditions.checkNotNull(tempPath);}/*** 开始事务,创建事务文件并返回事务文件名** @return 事务文件名* @throws Exception 如果创建文件失败*/@Overridepublic String beginTransaction() throws Exception {// 构建事务文件路径,包括当前时间和任务索引LocalDateTime now = LocalDateTime.now(ZoneId.of("UTC"));String timeNow = now.format(DateTimeFormatter.ISO_LOCAL_DATE_TIME);int taskIdx = getRuntimeContext().getIndexOfThisSubtask();String transactionFile = TimeConversionUtil.convertToTimestamp(timeNow) + "-" + taskIdx;// 创建事务文件和缓冲写入器Path tFilePath = Paths.get(tempPath, transactionFile);Files.createFile(tFilePath);this.transactionWriter = Files.newBufferedWriter(tFilePath);System.out.println("Creating Transaction File: " + tFilePath);// 返回事务文件名,以便后续识别事务return transactionFile;}/*** 写入数据到事务文件** @param transaction 事务文件名* @param value 要写入的数据* @param context 上下文* @throws Exception 如果写入失败*/@Overridepublic void invoke(String transaction, T value, Context context) throws Exception {transactionWriter.write(value.toString());transactionWriter.newLine();}/*** 预提交事务,刷新并关闭缓冲写入器** @param transaction 事务文件名* @throws Exception 如果刷新或关闭失败*/@Overridepublic void preCommit(String transaction) throws Exception {transactionWriter.flush();transactionWriter.close();}/*** 提交事务,将临时文件移动到目标路径** @param transaction 事务文件名*/@Overridepublic void commit(String transaction) {Path tFilePath = Paths.get(tempPath, transaction);// 检查文件是否存在,确保提交操作幂等if (Files.exists(tFilePath)) {Path cFilePath = Paths.get(targetPath, transaction);try {Files.move(tFilePath, cFilePath);} catch (IOException e) {System.err.println("Failed to move transaction file: " + tFilePath + " to " + cFilePath);e.printStackTrace();}}}/*** 回滚事务,删除临时文件** @param transaction 事务文件名*/@Overridepublic void abort(String transaction) {Path tFilePath = Paths.get(tempPath, transaction);if (Files.exists(tFilePath)) {try {Files.delete(tFilePath);} catch (IOException e) {System.err.println("Failed to delete transaction file: " + tFilePath);e.printStackTrace();}}}}private static class TimeConversionUtil {/*** 将给定的时间字符串转换为时间戳(毫秒)。** @param dateTimeStr 给定的时间字符串,格式为 "yyyy-MM-dd'T'HH:mm:ss.SSS"* @return 时间戳(毫秒)* @throws IllegalArgumentException 如果时间字符串格式不正确*/public static long convertToTimestamp(String dateTimeStr) {// 定义日期时间格式DateTimeFormatter formatter = DateTimeFormatter.ofPattern("yyyy-MM-dd'T'HH:mm:ss.SSS");try {// 解析日期时间字符串LocalDateTime localDateTime = LocalDateTime.parse(dateTimeStr, formatter);// 假设时间为 UTC 时区,转换为 InstantInstant instant = localDateTime.atZone(ZoneId.of("UTC")).toInstant();// 返回时间戳return instant.toEpochMilli();} catch (Exception e) {throw new IllegalArgumentException("日期时间字符串格式不正确: " + dateTimeStr, e);}}}@AllArgsConstructor@NoArgsConstructor@Dataprivate static class SensorReading implements Serializable {private String id;private long timestamp;private double temperature;}
}
优缺点
要使用 TwopahseCommitSinkFunction对外部系统具有如下要求
- 外部系统必须提供事务支持或者能够可以Sink去模拟事务(BucketingSink的原子命名模拟保证了提交的原子性),在事务Committed之前不能对下游系统可见
- 在快照间隔内事务不能timeout,否则无法以事务的方式提交输出。
- 事务必须在收到job manager发送的global commited的消息后,才能commited。在fail recovery的时候,若恢复时间较长(载入大状态),若事务关闭(事务timeout),该数据会丢失。
- 在fail recovery后,事务需要支持恢复之前pending的事务,并进行提交。(一些外部系统能够使用transaction id去commit或者abort之前的事务)
- 事务的提交必须是幂等的,因为在恢复时,会重新提交一遍pending transaction,因此需要对同一个事务的commit是幂等的。
可以看到外部系统不但要支持事务,同时也要能支持根据事务id去恢复之前的事务。
Flink的容错配置及测试
Task级失败重启恢复状态
Task级别的故障重启,是系统自动进行的;
Task失败的自动重启策略
-
固定延迟重启策略
固定延迟重启策略是尝试给定次数重新启动作业。如果超过最大尝试次数,任务最终会失败。在两次连续的重启尝试之间,重启策略需要等待固定的时间。
- 会尝试一个给定的次数来重启 Job;
- 如果超过最大的重启次数(默认 Integer.MAX_VALUE 次),Job 最终将失败;
- 在连续两次重启尝试之间,重启策略会等待一个固定时间;
在flink-conf.yaml中设置:
# 重启策略 restart-strategy: fixed-delay # 尝试次数 restart-strategy.fixed-delay.attempts: 3 # 固定延迟时间 restart-strategy.fixed-delay.delay: 10 s在代码中设置:
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); env.setRestartStrategy(RestartStrategies.fixedDelayRestart(3, // number of restart attemptsTime.of(10, TimeUnit.SECONDS) // delay )); -
指数延迟重启策略
本策略:故障越频繁,两次重启间的惩罚间隔就越长
-
initialBackoff 重启间隔惩罚时长的初始值 : 1s
-
maxBackoff 重启间隔最大惩罚时长 : 60s
-
backoffMultiplier 重启间隔时长的惩罚倍数: 2( 每多故障一次,重启延迟惩罚就在 上一次的惩罚时长上 * 倍数)
-
resetBackoffThreshold 重置惩罚时长的平稳运行时长阈值(平稳运行达到这个阈值后,如果再故障,则故障重启延迟时间重置为了初始值:1s)
jitterFactor 取一个随机数,来加在重启时间点上,已让每次重启的时间点呈现一定随机性
job1: 9.51 9.53+2*0.1 9.57 …
job2: 9.51 9.53+2*0.15 9.57 …
job3: 9.51 9.53+2*0.8 9.57 …
在flink-conf.yaml中设置:
# 重启策略 restart-strategy: exponential-delay # 初次失败后重启时间间隔(初始值) restart-strategy.exponential-delay.initial-backoff: 10 s # 最大重启时间间隔,超过这个最大值后,重启时间间隔不再增大 restart-strategy.exponential-delay.max-backoff: 2 min # 以后每次失败,重启时间间隔为上一次重启时间间隔乘以这个值 restart-strategy.exponential-delay.backoff-multiplier: 2.0 # 多长时间作业运行无失败后,重启间隔时间会重置为初始值(第一个配置项的值) restart-strategy.exponential-delay.reset-backoff-threshold: 10 min # 每次重启间隔时间的最大抖动值(加或减去该配置项范围内的一个随机数),防止大量作业在同一时刻重启 restart-strategy.exponential-delay.jitter-factor: 0.1在代码中设置:
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); env.setRestartStrategy(RestartStrategies.exponentialDelayRestart(Time.milliseconds(1),Time.milliseconds(1000),1.1, // exponential multiplierTime.milliseconds(2000), // threshold duration to reset delay to its initial value0.1 // jitter )); -
-
失败率重启策略
故障率重启策略是在任务失败后重新启动任务,但当故障率(每一个时间间隔的故障率)超过时,任务最终会失败。在两次连续的重启尝试之间,重启策略需要等待一定的时间。即在restart-strategy.failure-rate.failure-rate-interval时间内失败超过restart-strategy.failure-rate.max-failures-per-interval该值则失败。
在flink-conf.yaml中设置:
# 重启策略 restart-strategy: failure-rate # 失败作业之前的给定时间间隔内的最大重启次数 restart-strategy.failure-rate.max-failures-per-interval: 3 # 测量故障率的时间间隔 restart-strategy.failure-rate.failure-rate-interval: 5 min # 两次连续重启尝试之间的延迟 restart-strategy.failure-rate.delay: 10 s在代码中设置:
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); env.setRestartStrategy(RestartStrategies.failureRateRestart(3, // max failures per intervalTime.of(5, TimeUnit.MINUTES), //time interval for measuring failure rateTime.of(10, TimeUnit.SECONDS) // delay )); -
无重启策略
作业直接失败,不尝试重启。
在flink-conf.yaml中设置:
restart-strategy: none在代码中设置:
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); env.setRestartStrategy(RestartStrategies.noRestart()); -
回退策略
后备重启策略,保底策略,即所谓的默认重启策略;集群中如果没有在配置文件(flink-conf.yaml)中显示的配置重启策略,也没有在编程中指定,在检查点机制开启的情况下,任务失败,flink会默认的选用Fixed Delay Restart Strategy重启,且会无限尝试重连(Integer.MAX_VALUE次)。
Failover-strategy策略
fink支持不同的故障恢复策略,通过在flink的flink-conf.yaml配置文件中的jobmanager.execution.failover-strategy属性,本参数的含义是: 当一个task故障,需要restart的时候,是restart整个job中的所有task,还是只restart一部分task;
有两种方式:
-
restart all 在配置文件中的值为full
重启所有task,来实现failover。
jobmanager.execution.failover-strategy: full -
restart pipelilned region 在配置文件中的值是region
这种策略把任务分成互不相连的区域。当检测到任务失败时,此策略重新计算最小的region集以从故障中恢复,对于某些作业,与Restart All Failover策略相比,这会重新启动的任务更少
jobmanager.execution.failover-strategy: region一个region是一个task的集合,这些task的通信是通过pipeline的方式进行数据交换
region重启必要性的计算策略:
-
region包含需要重启的失败的task
-
结果分区被必须重启的region所依赖且不可用时,产出结果分区的region也需要被重启;
-
如果一个需要被重启的region,则消费它数据的region也需要被重启;(这是为了确保数据一致性,因为不确定的计算或分区,可能造成不同的分区)
案例演示
模拟异常的代码
package day05;import org.apache.flink.api.common.RuntimeExecutionMode; import org.apache.flink.api.common.functions.FlatMapFunction; import org.apache.flink.api.common.functions.MapFunction; import org.apache.flink.api.java.functions.KeySelector; import org.apache.flink.api.java.tuple.Tuple2; import org.apache.flink.streaming.api.datastream.DataStreamSource; import org.apache.flink.streaming.api.datastream.KeyedStream; import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator; import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment; import org.apache.flink.util.Collector;/*** @author: itcast* @date: 2022/10/26 17:18* @desc: Flink 代码实现流处理,进行单词统计。数据源来自于socket数据。* todo 演示Flink遇到异常重启。*/ public class Demo05_RestartStrategy {public static void main(String[] args) throws Exception {//1.构建流式执行环境StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();env.setRuntimeMode(RuntimeExecutionMode.STREAMING);env.setParallelism(1);//2.数据输入(数据源)//从socket读取数据,socket = hostname + portDataStreamSource<String> source = env.socketTextStream("node1", 9999);//3.数据处理//3.1 使用flatMap进行扁平化处理SingleOutputStreamOperator<String> flatMapStream = source.flatMap(new FlatMapFunction<String, String>() {@Overridepublic void flatMap(String value, Collector<String> out) throws Exception {String[] words = value.split(" ");for (String word : words) {if (word.equals("evil")) {//evil:恶魔,魔鬼,程序如果碰到魔鬼就退出。throw new Exception("魔鬼来了,程序退出");}out.collect(word);}}});//3.2 使用map进行转换,转换成(单词,1)SingleOutputStreamOperator<Tuple2<String, Integer>> mapStream = flatMapStream.map(new MapFunction<String, Tuple2<String, Integer>>() {@Overridepublic Tuple2<String, Integer> map(String value) throws Exception {return Tuple2.of(value, 1);}});//3.3使用keyBy进行单词分组KeyedStream<Tuple2<String, Integer>, String> keyedStream = mapStream.keyBy(new KeySelector<Tuple2<String, Integer>, String>() {@Overridepublic String getKey(Tuple2<String, Integer> value) throws Exception {return value.f0;}});//3.4 使用reduce(sum)进行聚合操作,sum:就是根据第一个元素(Integer)进行sum操作SingleOutputStreamOperator<Tuple2<String, Integer>> result = keyedStream.sum(1);//4.数据输出result.print();//5.启动流式任务env.execute();} }Checkpoint配置和重启策略的配置
execution.checkpointing.interval: 5000 #设置有且仅有一次模式 目前支持 EXACTLY_ONCE、AT_LEAST_ONCE execution.checkpointing.mode: EXACTLY_ONCE state.backend: hashmap #设置checkpoint的存储方式 state.checkpoint-storage: filesystem #设置checkpoint的存储位置 state.checkpoints.dir: hdfs://node1:8020/checkpoints #设置savepoint的存储位置 state.savepoints.dir: hdfs://node1:8020/checkpoints #设置checkpoint的超时时间 即一次checkpoint必须在该时间内完成 不然就丢弃 execution.checkpointing.timeout: 600000 #设置两次checkpoint之间的最小时间间隔 execution.checkpointing.min-pause: 500 #设置并发checkpoint的数目 execution.checkpointing.max-concurrent-checkpoints: 1 #开启checkpoints的外部持久化这里设置了清除job时保留checkpoint,默认值时保留一个 假如要保留3个 state.checkpoints.num-retained: 3 #默认情况下,checkpoint不是持久化的,只用于从故障中恢复作业。当程序被取消时,它们会被删除。但是你可以配置checkpoint被周期性持久化到外部,类似于savepoints。这些外部的checkpoints将它们的元数据输出到外#部持久化存储并且当作业失败时不会自动 清除。这样,如果你的工作失败了,你就会有一个checkpoint来恢复。 #ExternalizedCheckpointCleanup模式配置当你取消作业时外部checkpoint会产生什么行为: #RETAIN_ON_CANCELLATION: 当作业被取消时,保留外部的checkpoint。注意,在此情况下,您必须手动清理checkpoint状态。 #DELETE_ON_CANCELLATION: 当作业被取消时,删除外部化的checkpoint。只有当作业失败时,检查点状态才可用。 execution.checkpointing.externalized-checkpoint-retention: RETAIN_ON_CANCELLATION# 设置无重启策略 restart-strategy: none每次更改配置之后需要重启Flink集群。
演示none重启策略
#1.启动HDFS #2.把jar包上传到Linux #3.配置Flink的Checkpoint和重启策略 #4.提交任务cd $FLINK_HOMEbin/flink run -c day05.Demo05_RestartStrategy /root/original-gz_flinkbase-1.0-SNAPSHOT.jar #5.在socket中数据单词运行结果如下:

演示fixed-delay重启策略
使用刚刚的jar包演示即可。
配置如下:
# 设置固定延迟策略 restart-strategy: fixed-delay # 尝试重启次数 restart-strategy.fixed-delay.attempts: 3 # 两次连续重启的间隔时间 restart-strategy.fixed-delay.delay: 3 s每次更改配置之后需要重启Flink集群。
提交命令:
bin/flink run -c day05.Demo05_RestartStrategy /root/original-gz_flinkbase-1.0-SNAPSHOT.jar运行结果:

演示failure-rate重启策略
使用刚刚的jar包演示即可。
配置如下:
# 设置失败率重启 restart-strategy: failure-rate # 两次连续重启的间隔时间 restart-strategy.failure-rate.delay: 3 s # 计算失败率的统计时间跨度 restart-strategy.failure-rate.failure-rate-interval: 1 min # 计算失败率的统计时间内的最大失败次数 restart-strategy.failure-rate.max-failures-per-interval: 3每次更改配置之后需要重启Flink集群。
提交命令:
bin/flink run -c day05.Demo05_RestartStrategy /root/original-gz_flinkbase-1.0-SNAPSHOT.jar运行结果:
exponential-delay重启策略
使用刚刚的jar包演示即可。
配置如下:
# 设置指数延迟重启 restart-strategy: exponential-delay # 初次失败后重启时间间隔(初始值) restart-strategy.exponential-delay.initial-backoff: 1 s # 以后每次失败,重启时间间隔为上一次重启时间间隔乘以这个值 restart-strategy.exponential-delay.backoff-multiplier: 2 # 每次重启间隔时间的最大抖动值(加或减去该配置项范围内的一个随机数),防止大量作业在同一时刻重启 restart-strategy.exponential-delay.jitter-factor: 0.1 # 最大重启时间间隔,超过这个最大值后,重启时间间隔不再增大 restart-strategy.exponential-delay.max-backoff: 1 min # 多长时间作业运行无失败后,重启间隔时间会重置为初始值(第一个配置项的值) restart-strategy.exponential-delay.reset-backoff-threshold: 1 h每次更改配置之后需要重启Flink集群。
提交命令:
bin/flink run -c day05.Demo05_RestartStrategy /root/original-gz_flinkbase-1.0-SNAPSHOT.jar -
案例演示
模拟异常的代码
import org.apache.flink.api.common.RuntimeExecutionMode;
import org.apache.flink.api.common.functions.FlatMapFunction;
import org.apache.flink.api.common.functions.MapFunction;
import org.apache.flink.api.java.functions.KeySelector;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.KeyedStream;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.util.Collector;/*** @author: itcast* @date: 2022/10/26 17:18* @desc: Flink 代码实现流处理,进行单词统计。数据源来自于socket数据。* todo 演示Flink遇到异常重启。*/
public class Demo05_RestartStrategy {public static void main(String[] args) throws Exception {//1.构建流式执行环境StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();env.setRuntimeMode(RuntimeExecutionMode.STREAMING);env.setParallelism(1);//2.数据输入(数据源)//从socket读取数据,socket = hostname + portDataStreamSource<String> source = env.socketTextStream("node1", 9999);//3.数据处理//3.1 使用flatMap进行扁平化处理SingleOutputStreamOperator<String> flatMapStream = source.flatMap(new FlatMapFunction<String, String>() {@Overridepublic void flatMap(String value, Collector<String> out) throws Exception {String[] words = value.split(" ");for (String word : words) {if (word.equals("evil")) {//evil:恶魔,魔鬼,程序如果碰到魔鬼就退出。throw new Exception("魔鬼来了,程序退出");}out.collect(word);}}});//3.2 使用map进行转换,转换成(单词,1)SingleOutputStreamOperator<Tuple2<String, Integer>> mapStream = flatMapStream.map(new MapFunction<String, Tuple2<String, Integer>>() {@Overridepublic Tuple2<String, Integer> map(String value) throws Exception {return Tuple2.of(value, 1);}});//3.3使用keyBy进行单词分组KeyedStream<Tuple2<String, Integer>, String> keyedStream = mapStream.keyBy(new KeySelector<Tuple2<String, Integer>, String>() {@Overridepublic String getKey(Tuple2<String, Integer> value) throws Exception {return value.f0;}});//3.4 使用reduce(sum)进行聚合操作,sum:就是根据第一个元素(Integer)进行sum操作SingleOutputStreamOperator<Tuple2<String, Integer>> result = keyedStream.sum(1);//4.数据输出result.print();//5.启动流式任务env.execute();}
}Checkpoint配置和重启策略的配置
execution.checkpointing.interval: 5000
#设置有且仅有一次模式 目前支持 EXACTLY_ONCE、AT_LEAST_ONCE
execution.checkpointing.mode: EXACTLY_ONCE
state.backend: hashmap
#设置checkpoint的存储方式
state.checkpoint-storage: filesystem
#设置checkpoint的存储位置
state.checkpoints.dir: hdfs://node1:8020/checkpoints
#设置savepoint的存储位置
state.savepoints.dir: hdfs://node1:8020/checkpoints
#设置checkpoint的超时时间 即一次checkpoint必须在该时间内完成 不然就丢弃
execution.checkpointing.timeout: 600000
#设置两次checkpoint之间的最小时间间隔
execution.checkpointing.min-pause: 500
#设置并发checkpoint的数目
execution.checkpointing.max-concurrent-checkpoints: 1
#开启checkpoints的外部持久化这里设置了清除job时保留checkpoint,默认值时保留一个 假如要保留3个
state.checkpoints.num-retained: 3
#默认情况下,checkpoint不是持久化的,只用于从故障中恢复作业。当程序被取消时,它们会被删除。但是你可以配置checkpoint被周期性持久化到外部,类似于savepoints。这些外部的checkpoints将它们的元数据输出到外#部持久化存储并且当作业失败时不会自动
清除。这样,如果你的工作失败了,你就会有一个checkpoint来恢复。
#ExternalizedCheckpointCleanup模式配置当你取消作业时外部checkpoint会产生什么行为:
#RETAIN_ON_CANCELLATION: 当作业被取消时,保留外部的checkpoint。注意,在此情况下,您必须手动清理checkpoint状态。
#DELETE_ON_CANCELLATION: 当作业被取消时,删除外部化的checkpoint。只有当作业失败时,检查点状态才可用。
execution.checkpointing.externalized-checkpoint-retention: RETAIN_ON_CANCELLATION# 设置无重启策略
restart-strategy: none
每次更改配置之后需要重启Flink集群。
演示none重启策略
#1.启动HDFS
#2.把jar包上传到Linux
#3.配置Flink的Checkpoint和重启策略
#4.提交任务cd $FLINK_HOMEbin/flink run -c day05.Demo05_RestartStrategy /root/original-gz_flinkbase-1.0-SNAPSHOT.jar
#5.在socket中数据单词
运行结果如下:

演示fixed-delay重启策略
使用刚刚的jar包演示即可。
配置如下:
# 设置固定延迟策略
restart-strategy: fixed-delay
# 尝试重启次数
restart-strategy.fixed-delay.attempts: 3
# 两次连续重启的间隔时间
restart-strategy.fixed-delay.delay: 3 s
每次更改配置之后需要重启Flink集群。
提交命令:
bin/flink run -c day05.Demo05_RestartStrategy /root/original-gz_flinkbase-1.0-SNAPSHOT.jar
运行结果:

演示failure-rate重启策略
使用刚刚的jar包演示即可。
配置如下:
# 设置失败率重启
restart-strategy: failure-rate
# 两次连续重启的间隔时间
restart-strategy.failure-rate.delay: 3 s
# 计算失败率的统计时间跨度
restart-strategy.failure-rate.failure-rate-interval: 1 min
# 计算失败率的统计时间内的最大失败次数
restart-strategy.failure-rate.max-failures-per-interval: 3
每次更改配置之后需要重启Flink集群。
提交命令:
bin/flink run -c day05.Demo05_RestartStrategy /root/original-gz_flinkbase-1.0-SNAPSHOT.jar
运行结果:

exponential-delay重启策略
使用刚刚的jar包演示即可。
配置如下:
# 设置指数延迟重启
restart-strategy: exponential-delay
# 初次失败后重启时间间隔(初始值)
restart-strategy.exponential-delay.initial-backoff: 1 s
# 以后每次失败,重启时间间隔为上一次重启时间间隔乘以这个值
restart-strategy.exponential-delay.backoff-multiplier: 2
# 每次重启间隔时间的最大抖动值(加或减去该配置项范围内的一个随机数),防止大量作业在同一时刻重启
restart-strategy.exponential-delay.jitter-factor: 0.1
# 最大重启时间间隔,超过这个最大值后,重启时间间隔不再增大
restart-strategy.exponential-delay.max-backoff: 1 min
# 多长时间作业运行无失败后,重启间隔时间会重置为初始值(第一个配置项的值)
restart-strategy.exponential-delay.reset-backoff-threshold: 1 h
每次更改配置之后需要重启Flink集群。
提交命令:
bin/flink run -c day05.Demo05_RestartStrategy /root/original-gz_flinkbase-1.0-SNAPSHOT.jar
Cluster级失败重启恢复状态
save points概念
-
savepoint(保存点)是基于 Flink检查点机制的完整快照备份机制,用来保存状态,可以在另一个集群或者另一个时间点从保存的状态中将作业恢复回来;
-
适用于应用升级、集群迁移、Flink 集群版本更新、A/B 测试以及假定场景、暂停和重启、归档等场景;
-
保存点可以视为一个(算子 ID -> State) 的Map,对于每一个有状态的算子,Key 是算子ID,Value 是算子的State;
save points相关配置(flink-conf.yaml)
# Default savepoint target directory
state.savepoints.dir: hdfs:///flink/savepoints
savepoints操作命令
IDEA本地运行时savepoints恢复测试
Configuration conf = new Configuration();
// 指定想要从中恢复的检查点(savepoints)目录
conf.setString("execution.savepoint.path", "file:///D:/checkpoint/7ecbd4f9106957c42109bcde/chk-544");
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(conf);
集群运行时,手动触发savepoint
# 触发一次savepoint
$ bin/flink savepoint :jobId [:targetDirectory]# 为yarn模式集群触发savepoint
$ bin/flink savepoint :jobId [:targetDirectory] -yid :yarnAppId# 停止一个job集群并触发savepoint
$ bin/flink stop --savepointPath [:targetDirectory] :jobId# 从一个指定savepoint恢复启动job集群
$ bin/flink run -s :savepointPath [:runArgs]# 删除一个savepoint
$ bin/flink savepoint -d :savepointPath
集群运行时,指定目录恢复savepoint
# 从一个指定savepoint恢复启动job集群
$ bin/flink run -s :savepointPath [:runArgs]# 删除一个savepoint
$ bin/flink savepoint -d :savepointPath
集群运行时,删除指定savepoint
# 删除一个savepoint
$ bin/flink savepoint -d :savepointPath
从savepoints恢复注意要点
从保存点恢复作业并不简单,尤其是在作业变更(如修改逻辑、修复 bug) 的情况下, 需要考虑:
-
算子的顺序改变
如果对应的 UID 没变,则可以恢复,如果对应的 UID 变了恢复失败。
-
作业中添加了新的算子
如果是无状态算子,没有影响,可以正常恢复,如果是有状态的算子,跟无状态的算子一样处理。
-
从作业中删除了一个有状态的算子
默认需要恢复保存点中所记录的所有算子的状态,如果删除了一个有状态的算子,从保存点回复的时候被删除的 OperatorID 找不到,所以会报错,可以通过在命令中添加:-- allowNonReStoredSlale (short: -n )跳过无法恢复的算子
-
添加和删除无状态的算子
如果手动设置了 UID 则可以恢复,保存点中不记录无状态的算子,如果是自动分配的 UID ,那么有状态算子的可能会变( Flink一个单调递增的计数器生成UID,DAG 改版,计数器极有可能会变) 很有可能恢复失败。
从savepoint恢复时,快照数据的重分配问题
Flink程序,允许在某次重启时,修改程序的JobGraph图(比如改变算子顺序,改变算子并行度等)
而且,在修改了程序的JobGraph图后,依然可以加载之前的状态快照数据,只不过,可能需要对之前的状态快照数据,在新的JobGraph下进行数据重分配;
-
Operator state
快照数据在重分配时,可能会对用户程序的计算逻辑产生不可预料的影响;
- UnionListState用广播模式重分配;
- Liststate用round-robin模式恢复;
-
Keyed state
快照数据在重分配时,因为程序处理数据时接收数据的规律和状态的分配规律完全一致,所以不会产生任何逻辑上的影响;

容错测试案例
在代码中制造一定概率的异常发生;
然后观察task自动重启、手动job重启时,数据从输入到输出的端到端一致性;
/** * @desc : flink的 端到端精确一次 容错能力测试* 从 kafka 读数据(里面有operator-state状态)* 处理过程中用到了带状态的 map算子(里面用了keyed-State状态,逻辑:输入一个字符串,变大写拼接此前字符串,输出)* 用 exactly-once 的 mysql-sink算子输出数据(并附带主键的幂等特性)* 测试用的 kafka-topic :* [root@node1 ~]# kafka-topics.sh --create --topic eos --partitions 1 --replication-factor 1 --zookeeper node1:2181* <p>* 测试用的输入数据:* a* b* c* d* <p>* <p>* 测试用的mysql表:* CREATE TABLE `t_eos` (* `str` varchar(255) NOT NULL,* PRIMARY KEY (`str`)* ) ENGINE=InnoDB DEFAULT CHARSET=utf8;**/
public class ToleranceSideToSideExample {public static void main(String[] args) throws Exception {Configuration conf = new Configuration();//conf.setString("execution.savepoint.path", "file:///D:/checkpoint/7ecbd4f9106957c42109bcde/chk-1");StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(conf);env.setParallelism(1);/* ** checkpoint 容错相关参数设置*/env.enableCheckpointing(1000, CheckpointingMode.EXACTLY_ONCE);env.getCheckpointConfig().setCheckpointStorage("file:///d:/eos_ckpt");/* ** task级别故障自动重启策略*/env.setRestartStrategy(RestartStrategies.fixedDelayRestart(3, Time.milliseconds(1000)));/* ** 状态后端设置 ,默认 : HashMapStateBackend*/env.setStateBackend(new HashMapStateBackend());/*** 构造一个支持eos语义的 kafkasource*/KafkaSource<String> sourceOperator = KafkaSource.<String>builder().setBootstrapServers("node1:9092").setTopics("eos").setGroupId("eos01").setValueOnlyDeserializer(new SimpleStringSchema()).setProperty(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG, "false") // 允许 kafkaconsumer自动提交消费位移到 __consumer_offsets// kafkaSource的做状态checkpoint时,默认会向__consumer_offsets提交一下状态中记录的偏移量// 但是,flink的容错并不优选依赖__consumer_offsets中的记录,所以可以关闭该默认机制.setProperty("commit.offsets.on.checkpoint", "false") // 默认是true// kafkaSource启动时,获取起始位移的策略设置,如果是 committedOffsets ,则是从之前所记录的偏移量开始// 如果没有可用的之前记录的偏移量, 则用策略 OffsetResetStrategy.LATEST 来决定.setStartingOffsets(OffsetsInitializer.committedOffsets(OffsetResetStrategy.LATEST)).build();/*** 构造一个支持精确一次的 jdbcSink*/SinkFunction<String> exactlyOnceJdbcSink = JdbcSink.exactlyOnceSink("insert into t_eos values (?) on duplicate key update str = ? ",new JdbcStatementBuilder<String>() {@Overridepublic void accept(PreparedStatement preparedStatement, String s) throws SQLException {preparedStatement.setString(1, s);preparedStatement.setString(2, s);}},JdbcExecutionOptions.builder().withMaxRetries(3).withBatchSize(1).build(),JdbcExactlyOnceOptions.builder().withTransactionPerConnection(true) // mysql不支持同一个连接上存在并行的多个未完成的事务,必须把该参数设置为true.build(),new SerializableSupplier<XADataSource>() {@Overridepublic XADataSource get() {// XADataSource就是jdbc连接,不过它是支持分布式事务的连接// 而且它的构造方法,不同的数据库构造方法不同MysqlXADataSource xaDataSource = new MysqlXADataSource();xaDataSource.setUrl("jdbc:mysql://node1:3306/flinkdemo?serverTimezone=Asia/Shanghai&useUnicode=true&characterEncoding=UTF-8");xaDataSource.setUser("root");xaDataSource.setPassword("123456");return xaDataSource;}});/* ** 数据处理逻辑*/DataStreamSource<String> stream1 = env.fromSource(sourceOperator, WatermarkStrategy.noWatermarks(), "kfksource");SingleOutputStreamOperator<String> stream2 = stream1.keyBy(s -> "group1").map(new RichMapFunction<String, String>() {ValueState<String> valueState;@Overridepublic void open(Configuration parameters) throws Exception {valueState = getRuntimeContext().getState(new ValueStateDescriptor<String>("preStr", String.class));}@Overridepublic String map(String element) throws Exception {// 从状态中取出上一条字符串String preStr = valueState.value();if (preStr == null) preStr = "";// 更新状态valueState.update(element);// 埋一个异常:当接收到 x 的时候,有 1/3 的概率异常if (element.equals("x") && RandomUtils.nextInt(0, 4) % 3 == 0) {throw new Exception("发生异常了.............");}return preStr + ":" + element.toUpperCase();}});stream2.addSink(exactlyOnceJdbcSink);env.execute();}
}
Flink程序分布式部署运行
Flink架构体系
- 整体架构如下图

- Actor通信系统
Spark:Spark采用的netty通信。
Flink:Flink采用的是Akka通信。
如下图,就是Akka的通信地址。我们不需要记住这个地址,但是要能够看得懂。

- 作业调度器
Spark:Spark有逻辑调度和物理调度,DAGScheduler,TaskScheduler。
DAGScheduler:做逻辑调度的。就是统筹,安排。
TaskScheduler:做物理调度。具体需要的资源等。
Flink:作用调度器。JobMaster。
Flink的JobManager由三个组件组成:
(1)JobMaster,可以做任务调度
(2)ResourceManager:就是Flink的资源管理,和Yarn的ResourceManager没关系。
(3)Dispacher(分发器):把任务分发给JobMaster去调度。
- 检查点协调器
全名叫CheckpointCoordinator,可以做Flink任务的状态一致性,容错机制。
- 内存和IO管理器
Flink任务运行,可能会在多个Slot之上,那么,这个时候就需要使用内存和IO管理。
可以分为三种情况:
#1.进程级别
在同一个进程里(在TaskManager),Slot之间的数据交互是最快的,也是最方便的。
这个交互不需要走网络。
因为进程是程序向操作系统申请资源的最小单位。#2.节点级别
在同一个节点,但是不同的进程。这两个TaskManager节点之间的数据在交互时,就需要走该节点的网络传输了。
这个效率中等。#3.跨节点传输
在多个节点之间,进行数据交互,那么这个时候,就需要跨节点传输。
这个效率是最低的。
我们在第一天上午下午演示Yarn的时候,我们会看到,YarnSessionClusterEntrypoint和TaskManagerRunner这两个进程在同一个节点的原因。
所以,在大数据有句话:移动数据 VS 移动计算?
答案:移动计算。
- 网路管理器
网络管理器,就是在Flink程序需要和别的进程,别的节点进行网络数据传输的时候,需要使用网络管理器。
Yarn模式安装部署
前提
Flink on Yarn的安装部署,非常方便。启动HDFS、Yarn即可。
start-all.sh
Flink可以单独运行(不需要HDFS、Yarn),但是,如果你需要Flink操作HDFS,则要引入Flink操作HDFS的Jar包。
cp flink-shaded-hadoop-3-uber-3.1.1.7.2.9.0-173-9.0.jar commons-cli-1.5.0.jar /export/server/flink/lib
除此之外,不需要做其他的配置。
生产环境建议使用Yarn来运行Flink。Standalone只推荐在开发、测试使用。
部署方式
Flink on Yarn可以有三种方式:
- Yarn-session模式(会话模式)
- per-job模式(Job分离模式)
- Application模式(应用模式)
Yarn-session模式

Yarn-session模式,分两步:
- 启动yarn-session.sh
这一步,会启动WebUI,这个时候,集群没有任何的slot资源。只有主角色(JobManager)在运行。没有从角色(TaskManager)运行。
这个yarn-session会长期运行。(它是一个常服务)
TaskManager会在具体的任务提交时,才会动态分配。而不是在yarn-session启动的时候分配。
任务运行完之后,主角色不会销毁,从角色会销毁
备注:
所有的任务,都会在这一个集群里运行。
cd $FLINK_HOME
bin/yarn-session.sh
- 提交任务到yarn运行
cd $FLINK_HOME
bin/flink run examples/batch/WordCount.jar
运行结果入下:

Per-job模式
Per-job模式,也叫Job分离模式。顾名思义,每一次提交任务,都会创建一个Flink集群。这个时候,每个任务都是独享一套集群的。
任务提交给Yarn时,动态创建集群,任务运行完之后,再销毁集群。(主,从都会销毁)

任务提交:
cd $FLINK_HOME
bin/flink run -m yarn-cluster examples/batch/WordCount.jar
任务运行时的截图:

运行结果如下:

Application模式
Application模式,也叫应用模式。早期的Flink中没有。是为了解决前面两种模式提交的弊端才产生的。
对比Spark:Master,Worker外,Driver客户端
Driver,可以在客户端节点,也可以在集群节点。
Flink,Yarn-session模式和Per-job模式,这两种模式,它们的客户端进程都在客户端节点。类似于Spark的Client模式。
Flink提出了Application模式,这个模式解决了客户端在客户端节点的问题。类似于Spark的Cluster模式。
运行案例:
bin/flink run-application -t yarn-application examples/batch/WordCount.jar --input hdfs://node1:8020/flink/wordcount.txt --output hdfs://node1:8020/wordcount/output1
Yarn三种模式总结
| 选项 | Yarn-session | Per-job | Application |
|---|---|---|---|
| 启动步骤 | 2步(1.yarn-session.sh;2.提交任务) | 1步(提交任务) | 1步(提交任务) |
| JobManager | 在第一步启动,不会销毁,长期运行 | 随着任务的提交而产生 | 随着任务的提交而产生 |
| TaskManager | 在第二步启动,任务运行完之后销毁 | 随着任务的销毁而销毁 | 随着任务的销毁而销毁 |
| 客户端进程 | 在客户端节点 | 在客户端节点 | 在集群中某个节点 |
| 适用范围 | 所有任务都共用一套集群,适合小任务,适合频繁提交场景 | 使用大任务,非频繁提交场景 | 使用大任务,非频繁提交场景 |
任务提交流程
抽象级别

抽象级别:不管是什么模式,大体上就是上面这个流程。
1.任务提交给分发器
2.分发器把任务提交给JobManager上的JobMaster组件
3.JobMaster收到任务之后,就会向JobManager上的ResourceManager去请求Slot
4.JobManager上的ResourceManager会提供给JobMaster相应的Slot
5.JobMaster把任务调度到具体的TaskManager上去执行
6.等待执行结果
具体模式下任务提交
Standalone模式下的任务提交

1.客户端把任务提交给Dispacher(分发器)
2.分发器启动JobMaster,并把任务提交给JobMaster
3.JobMaster收到任务之后,会想JobManager的ResourceManager组件去请求资源
4.JObManager的ResourceManager收到请求后,直接向TaskManager去请求相应的资源
5.TaskManager会向JobMaster提供相应的资源
6.JobMaster把任务调度到TaskManager去执行
Yarn-session模式下的任务提交
Session模式提交分2步:
- 启动yarn-session
流程图如下:

1.yarn-session.sh脚本向Yarn的ResourceManager请求Container(容器),这个容器就是ApplicationMaster
2.Yarn的ResourceManager收到请求后,就会启动JobManager,这个AppMaster就包含了Flink的JobManager(主节点)
3.JobManager这个角色,就会启动Dispacher和ResourceManager,这里没有TaskManager和JobMaster
- 提交任务

1.客户端提交任务到Dispacher(分发器)
2.分发器就会启动JobMaster
3.JobMaster会向JobManager的ResourceManager请求资源
4.JobManager的ResourceManager没有资源,因此向Yarn的ResourceManager申请资源
5.Yarn的ResourceManager收到请求后,就会启动Container(容器),这个容器就包含了TaskManager角色
6.TaskManager启动后就会向JobManager的ResourceManager注册资源,同时也会向JobMaster提供资源
7.JobMaster收到资源后,就会把任务调度给Container去执行,因为Container包含了TaskManager,因此任务会顺利执行完成
8.任务执行完之后,Container就会销毁(TaskManager就被销毁了),集群又恢复到第一步的状态
per-job模式下的任务提交
任务图如下:

1.客户端提交任务到Yarn集群
2.Yarn的ResourceManager收到任务请求后,会启动Container(容器),也就是AppMaster。这里包含了JobManager(Flink的主角色,这个JobManager没有Dispacher,但是有JobMaster和ResourceManager)
3.JobManager里的JobMaster向JobManager里的ResourceManager请求资源
4.JobManager的ResourceManager没有资源,因此会向Yarn去申请资源
5.Yarn的ResourceManager收到请求后,会额外启动Container(容器),启动的容器就会带有TaskManager(Flink的从角色)
6.Container会反向注册到AppMaster,告诉AppMaster自己的资源情况
7.Container会把资源提供给AppMaster(JobManager的JobMaster)
8.JobMaster会把任务具体地调度给Container去执行(TaskManager)
9.任务执行完之后,Container(TaskManager)会被AppMaster销毁,最终,AppMaster也会销毁。












