
前言
最近需要做关于Mcp工具的依赖,需要关系到工具扫描,这个逻辑高度类似于Mapper之于Mybatis,Controller之于SpringMvc,Bean之于Spring,如下图所示:
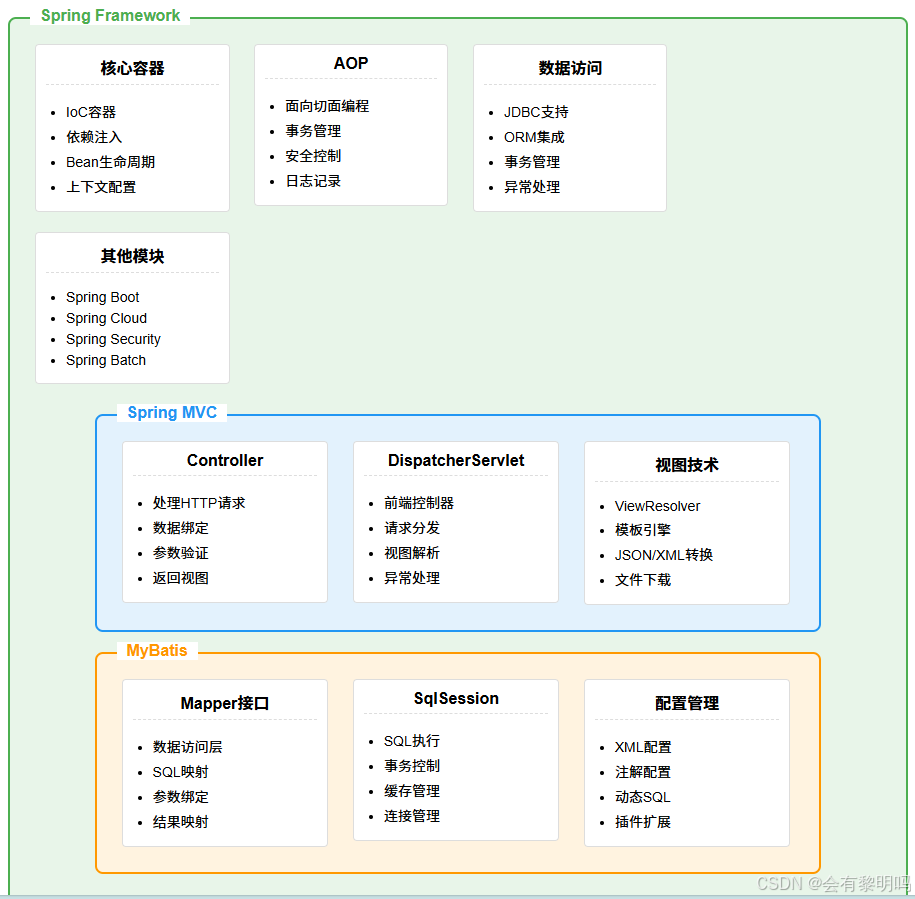
还记得初中第一堂课学的就是,人与动物的核心区别就是是否会使用工具,既然有了现成的对应最佳实践源码,那就直接拿来。
源码debug流程
先是问了一下ai,ComponentScan的代码逻辑在哪,他说 ClassPathBeanDefinitionScanner类里,然后打一个断电,开启debug运行模式。
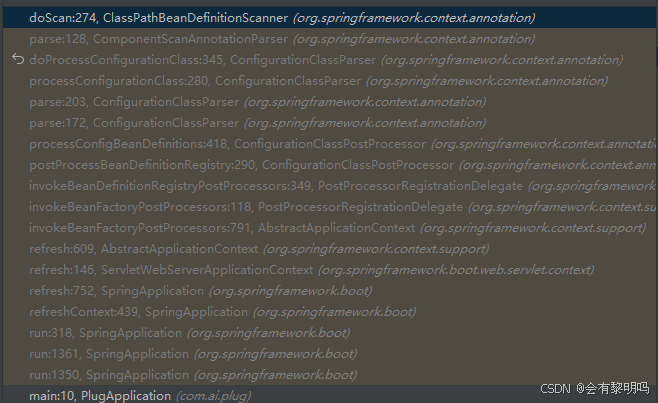
通过方法栈看到现在所处的流程位置大概流程就是项目启动后,开始Bean的生命周期中的Bean定义加载和解析的阶段。
直接打开上图倒数第二个ComponentScanAnnotationParser,这名字翻译过来就直接是ComponentScan注解解析器,好像是我们要找的东西,直接打开他的代码,点进来后是这样
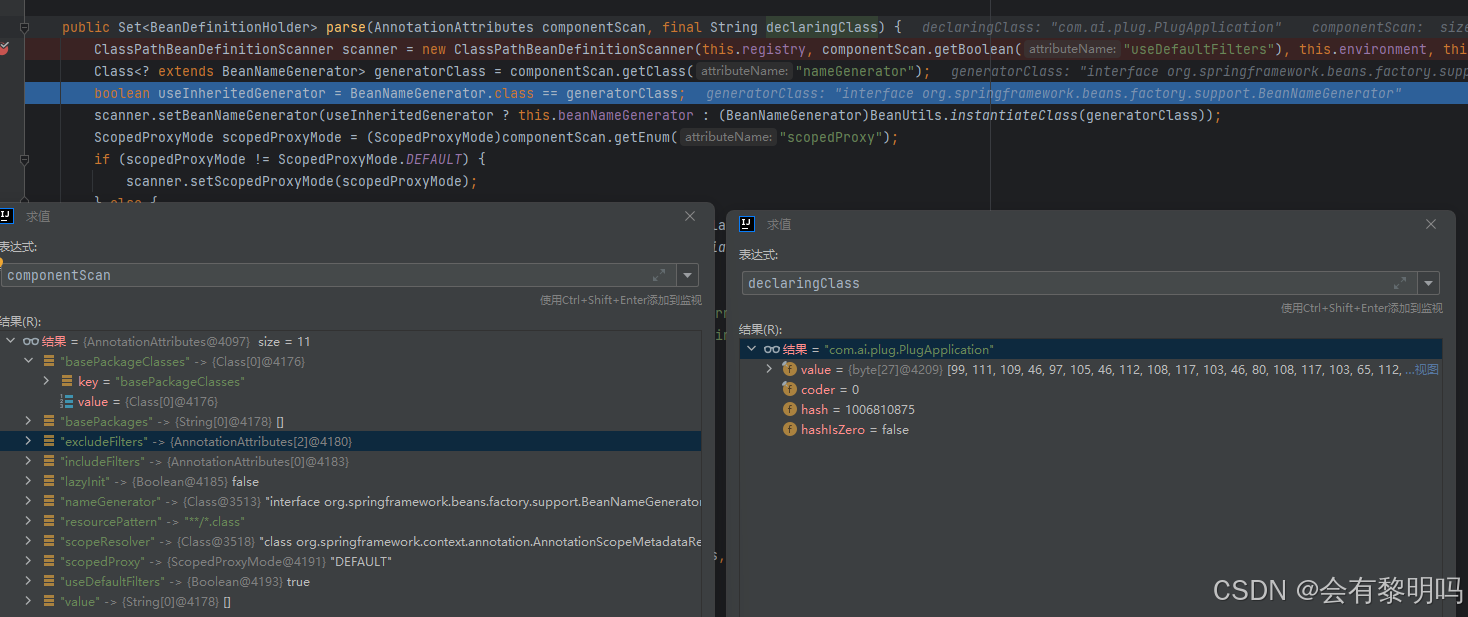
两个参数,一个是@ComponentScan注解的属性信息,一个是这个注解所在的全限定类名,前面这些代码都是一些与核心Bean注册无关的代码,比如是否懒加载,扫描哪个包配置等等,直接跳到核心代码(在下一层方法doScan里):
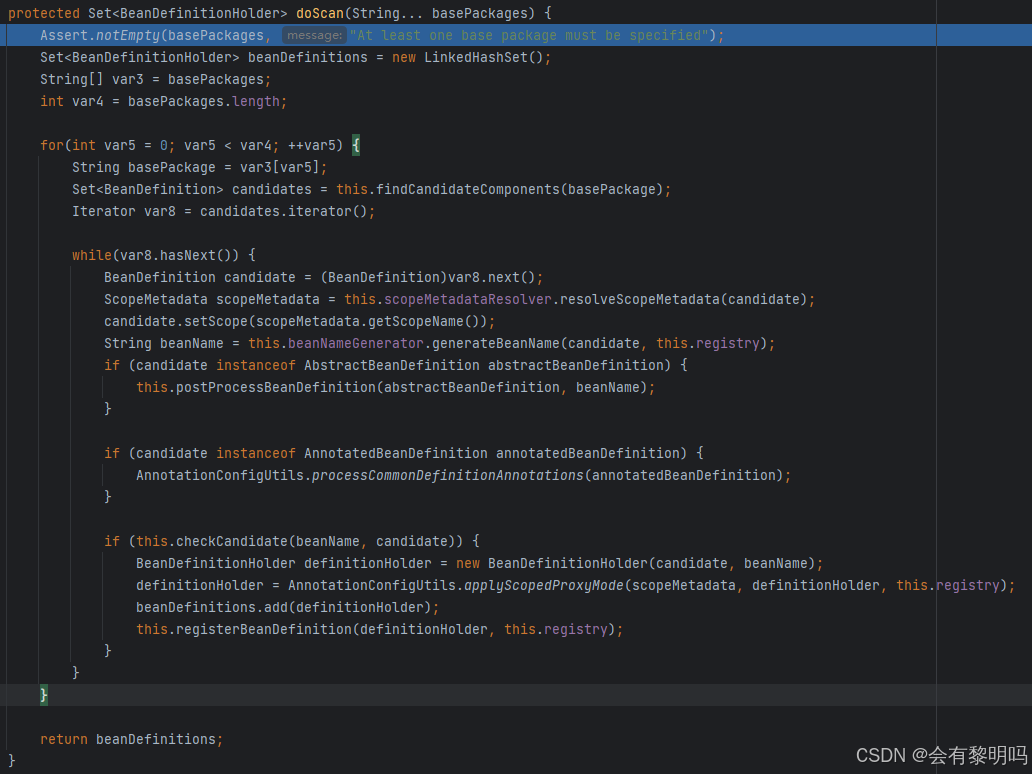
先是判断一下,你如果一个包都没有,那你可以直接退出程序了。然后摆好架势创建一个了熟悉的老角色BeanDefinitions和Bean生命周期中的BeanDefinitionMap十分相似,区别在于一个程序里不只有一个BeanDefinitions,就相当于一个局部的专属于这个Component的BeanDefinitionMap。
由于一个注解可以Scan多个包,就遍历这些包,上来就经过一个 find...方法,看方法名像是在寻找一些还未进行处理的Component,进入代码(实际进了两次,不必在意):
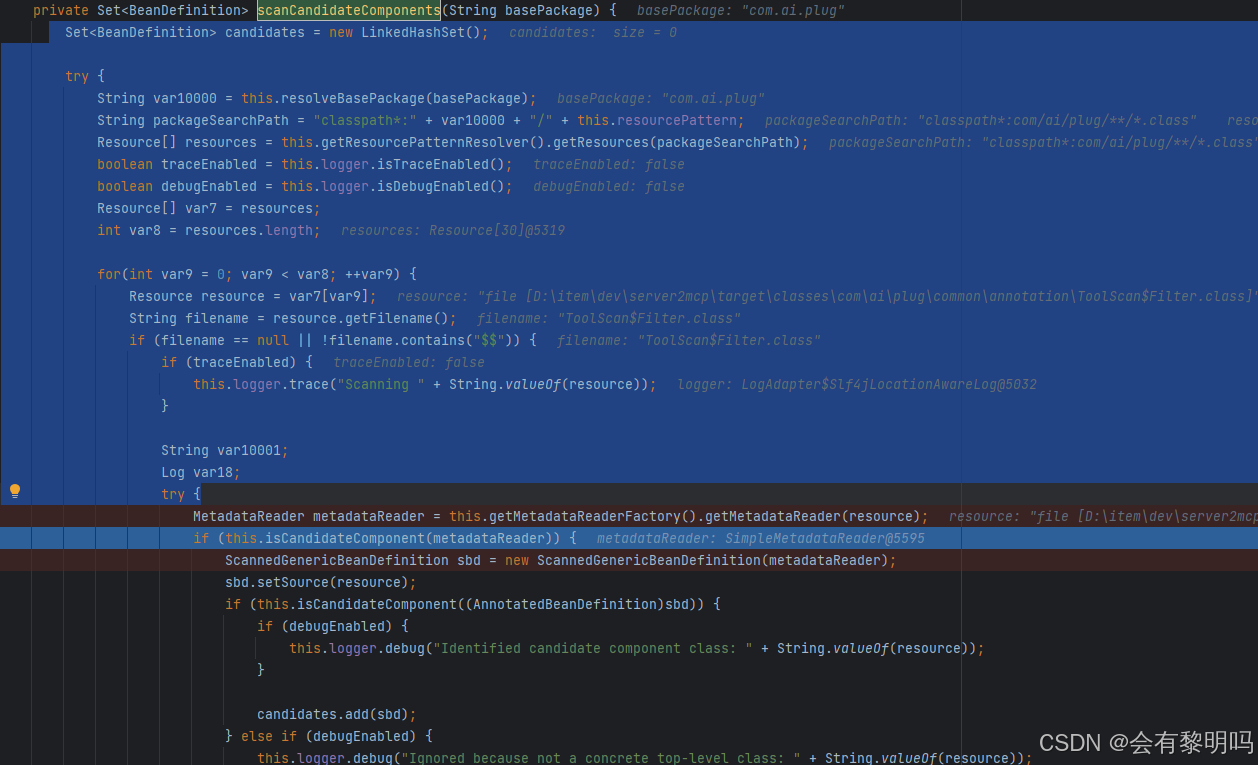
这段就是注册bean的核心逻辑了,先是把这个包下的所有class文件目录全都列出来,然后逐个去检查,这个isCandidateComponent就是去检查这个能不能注册为bean啊
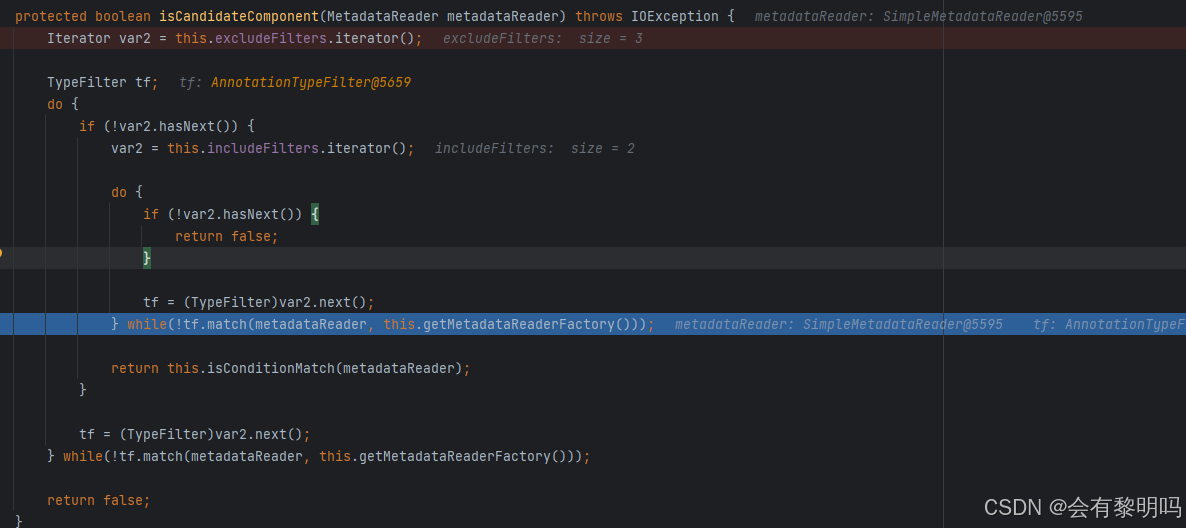
先经过的是excludeFilters,如果在排除过滤器里违反了相应规则,就直接出局了,includeFilter再定义也没什么作用了,springboot默认注册了一个@Component的includeFilter
然后就直接到BeanDifinition定义,再注册了。
反思
我本来想要的设计还是基于Bean容器去完成,但其实Spring的设计更加开放,但为了避免过多隐性和潜在的问题,还是要依赖强大的Spring生态去进行注册与解析。












