
1、前言
1.1、本地锁和分布式锁区别
锁我想对大家都不陌生,在我们刚学习 Java 的时候,肯定知道synchronized和Lock锁;这两者都是本地锁。
何为本地锁呢?本地锁就是该锁只针对当前节点有效,也就是当 node A 获取锁时,那么 node B 同样还可以获取锁,这种情况就是本地锁。
如果服务只部署了一个节点的话,用这种本地锁是没有问题的。
现现在很多系统为了抗高并发、高可用和高性能,会部署多节点(集群部署),那么此时如果还用本地锁的话就会出现问题,因此分布式锁就诞生了。
分布式锁就是当有一个节点获取到锁后,其它节点是不可以获取锁的。
1.2、Redis 分布式锁和 Zookeeper 分布式锁区别
谈起分布式集群,就绕不开CAP理论,也就是强一致性、可用性和分区容错性。三者只能选其二,不可兼容。这里我就不具体分析其原因之类了,直接步入两把分布式锁区别。
Redis分布式锁:它追求的高可用性和分区容错性。Redis 在追求高可用性时会在 Redis 写入主节点数据后,立即返回成功,不关心异步主节点同步从节点数据是否成功。Redis 是基于内存的,性能极高,官方给的指标是每秒可达到 10W 的吞吐量。
Zookeeper分布式锁:它追求的是强一致性和分区容错性。Zookeeper 在写入主节点数据后会等到从节点同步完数据成后才会返回成功。为了数据的强一致性牺牲了一部分可用性。
两者综合对比下来,技术派为了追求用户体验度,就采用了 Redis 分布式锁来实现。
2、使用 Redis 分布式锁背景
项目里面使用 Redis 分布式锁的背景是,用户根据 articleId 查询文章详情,查询出结果后返回。
查询文章详情流程图如下所示:

如果并发量不是特别高的情况下没有问题,但就怕并发量高;会出现什么问题呢?什么时候出现呢?
当缓存中没有数据,需要到 MySQL 中查询这一步。
问题出现点如下所示:

因为当高并发时,如果查询缓存中没有数据,大量的用户会同时去访问 DB 层 MySQL,MySQL 的资源是非常珍贵的,并且性能没有 Redis 好,很容易将我们的 MySQL 打宕机,进而影响整个服务。(缓存击穿雪崩)
针对这种问题,该怎么解决呢?
当大量用户同时访问同一篇文章时,只允许一个用户去 MySQL 中获取数据。由于服务是集群化部署,就需要用到 Redis 分布式锁。
逻辑如下所示:

采用加锁的方式就能很好地保护 DB 层数据库,进而保证系统的高可用性。

3、Redis 分布式锁几种实现方式
其实可以直接给大家讲最终的实现方式,这样我也比较省事;但是心里总感觉少点什么,所以接下来我就用几种方式由简到繁一点一点的推出最佳的实现方式。
3.1、Redis 实现分布式锁
代码如下图所示:

3.1.1、第一种 setIfAbsent(key,value,time)
redisTemplate.opsForValue().setIfAbsent(key, value, time, TimeUnit.SECONDS)对应的 Redis 命令是set key value EX time NX。
set key value EX time NX是一个复合操作,setNx + setEx,底层采用的是 lua 脚本来保证其原子性,要么全部成功,否则加锁失败。
redisTemplate.opsForValue().setIfAbsent(key, value, time, TimeUnit.SECONDS)含义就是:如果key不存在则加锁成功,返回true;否则加锁失败,返回false。
第一种加锁逻辑如下图所示:

主要逻辑就是:当缓存中没有数据时,开始加锁,加锁成功则允许访问数据库,加锁失败则自旋重新访问。
主要代码如下所示:
/*** Redis分布式锁第一种方法** @param articleId* @return ArticleDTO*/
private ArticleDTO checkArticleByDBOne(Long articleId) {String redisLockKey =RedisConstant.REDIS_PAI + RedisConstant.REDIS_PRE_ARTICLE + RedisConstant.REDIS_LOCK + articleId;ArticleDTO article = null;// 加分布式锁:此时value为null,时间为90s(结合自己场景设置合适过期时间,这里我为了验证随便设置的时间)Boolean isLockSuccess = redisUtil.setIfAbsent(redisLockKey, null, 90L);if (isLockSuccess) {// 加锁成功可以访问数据库article = articleDao.queryArticleDetail(articleId);} else {try {// 短暂睡眠,为了让拿到锁的线程有时间访问数据库拿到数据后set进缓存,// 这样在自旋时就能够从缓存中拿到数据;注意时间依旧结合自己实际情况Thread.sleep(200);} catch (InterruptedException e) {e.printStackTrace();}// 加锁失败采用自旋方式重新拿取数据this.queryDetailArticleInfo(articleId);}return article;
}主要逻辑都在代码注释中。下面我说说它的缺点:
虽然我们在 setIfAbsent 中设置了过期时间,但是会出现一种情况:当我们业务执行完之后,锁还被持有着。
虽然有过期时间,且 Redis 中有淘汰策略,但还是不建议这么做,因为 Redis 缓存资源是非常重要的;正确的做法应该是当业务执行完之后,直接释放锁。
3.1.2、第二种在第一种的基础上及时释放锁
针对第一种方式产生的问题:锁不能及时释放,我们将其进行优化为当业务执行完后立即释放锁。代码如下所示:
/*** Redis分布式锁第二种方法** @param articleId* @return ArticleDTO*/
private ArticleDTO checkArticleByDBTwo(Long articleId) {String redisLockKey =RedisConstant.REDIS_PAI + RedisConstant.REDIS_PRE_ARTICLE + RedisConstant.REDIS_LOCK + articleId;ArticleDTO article = null;Boolean isLockSuccess = redisUtil.setIfAbsent(redisLockKey, null, 90L);try {if (isLockSuccess) {article = articleDao.queryArticleDetail(articleId);} else {Thread.sleep(200);this.queryDetailArticleInfo(articleId);}} catch (InterruptedException e) {e.printStackTrace();} finally {// 和第一种方式相比增加了finally中删除keyRedisClient.del(redisLockKey);}return article;}第二种方法在业务执行完毕之后(也就是增加 finally 块)立即删除了 key 值,这样就针对第一种方式的问题解决了。
但是这种方式仍然存在问题:
释放别人的锁: 线程 A 已经获取到锁,正在执行业务,但还没有执行完成,结果过期时间到了,该锁被释放了;此时线程 B 可以获取该锁了,且执行业务逻辑,但是此时线程 A 执行完成需要释放锁,释放的锁是线程 B 的,也就是释放了别人的锁。
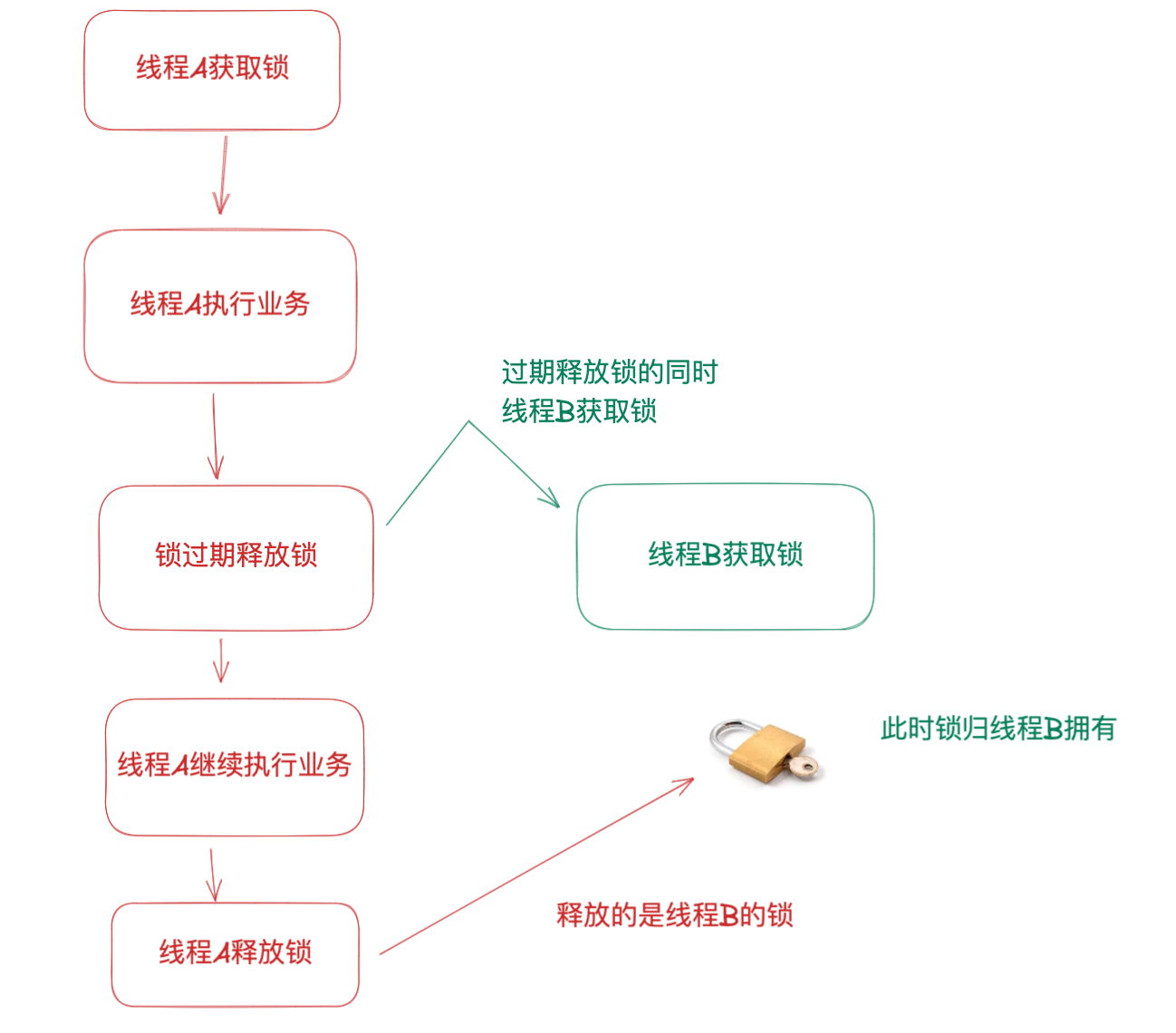
3.1.3、第三种在第二种的情况下不误放别人的锁
针对第二种加锁方式中存在误释放他人锁的情况,我们可以采用加锁的时候设置个 value 值,然后在释放锁前判断给 key 的 value 是否和前面设置的 value 值相等,相等则说明是自己的锁可以删除,否则是别人的锁不能删除。
代码如下所示:
/*** Redis分布式锁第三种方法** @param articleId* @return ArticleDTO*/
private ArticleDTO checkArticleByDBThree(Long articleId) {String redisLockKey =RedisConstant.REDIS_PAI + RedisConstant.REDIS_PRE_ARTICLE + RedisConstant.REDIS_LOCK + articleId;// 设置value值,保证不误删除他人锁String value = RandomUtil.randomString(6);Boolean isLockSuccess = redisUtil.setIfAbsent(redisLockKey, value, 90L);ArticleDTO article = null;try {if (isLockSuccess) {article = articleDao.queryArticleDetail(articleId);} else {Thread.sleep(200);this.queryDetailArticleInfo(articleId);}} catch (InterruptedException e) {e.printStackTrace();} finally {// 这种先get出value,然后再比较删除;这无法保证原子性,为了保证原子性,采用了lua脚本/*String redisLockValue = RedisClient.getStr(redisLockKey);if (!ObjectUtils.isEmpty(redisLockValue) && StringUtils.equals(value, redisLockValue)) {RedisClient.del(redisLockKey);}*/// 采用lua脚本来进行先判断,再删除;和上面的这种方式相比保证了原子性Long cad = redisLuaUtil.cad("pai_" + redisLockKey, value);log.info("lua 脚本删除结果:" + cad);}return article;}业务逻辑如下所示:
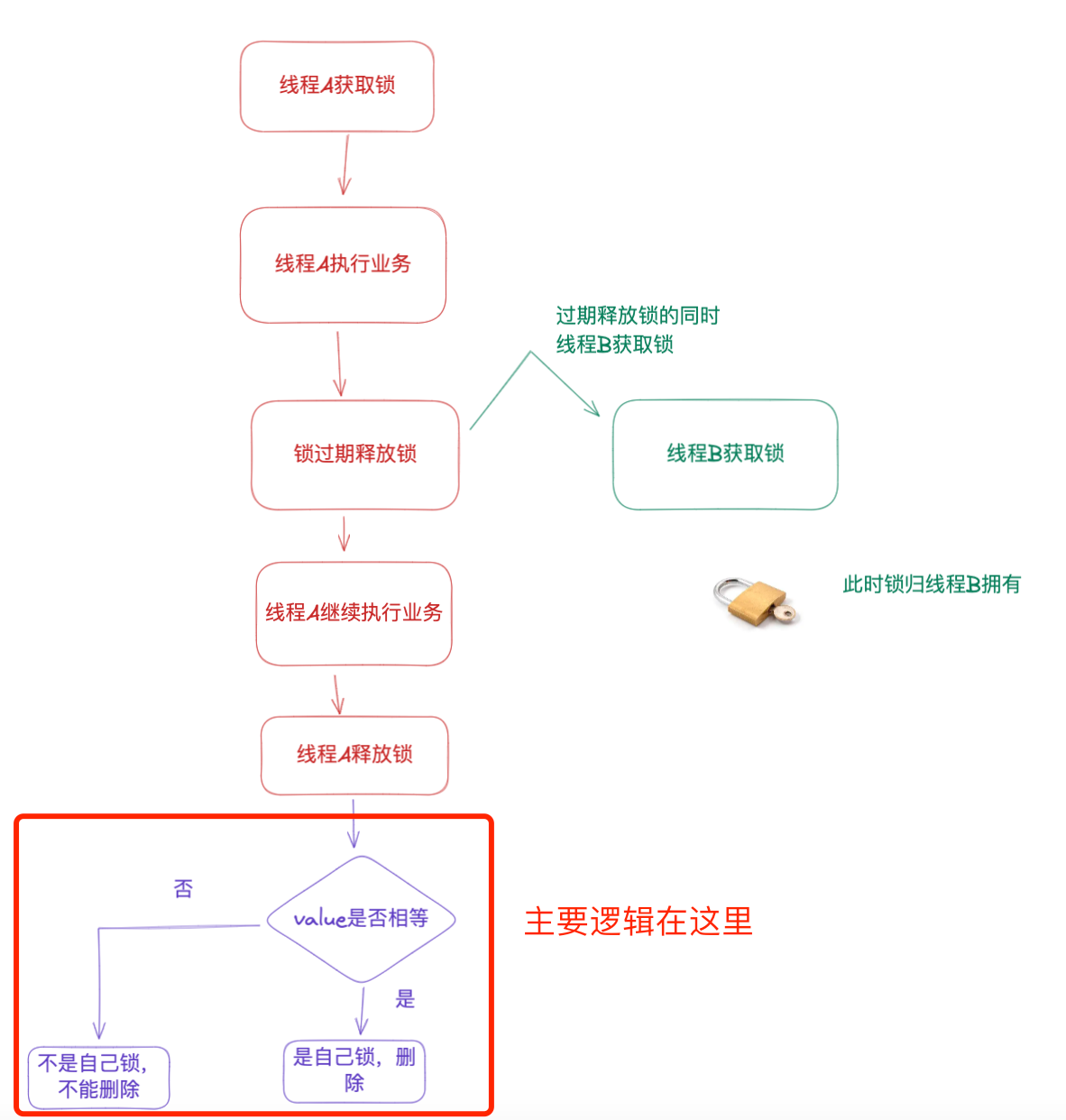
第三种方式解决了误删他人锁的问题,但是还存在一个问题——过期时间的值到底如何设置?
- 时间设置过短:可能业务还没有执行完毕,过期时间已经到了,锁被释放,其他线程可以拿到锁去访问 DB,违背了我们的初心。
- 时间设置过长:过长的话,可能在我们加锁成功后,还没有执行到释放锁,在这一段过程中节点宕机了,那么在锁未过期的这段时间,其他线程是不能获取锁的,这样也不好。
因此锁的过期时间设置是个大学问。
针对这个问题,可以写一个守护线程,然后每隔固定时间去查看业务是否执行完毕,如果没有的话就延长其过期时间,也就是为锁续期;
上面俗称看门狗机制,且已经有技术实现——Redission。
下面我就详细讲解下Redission 实现分布式锁的逻辑。3.2、Redission 实现分布式锁
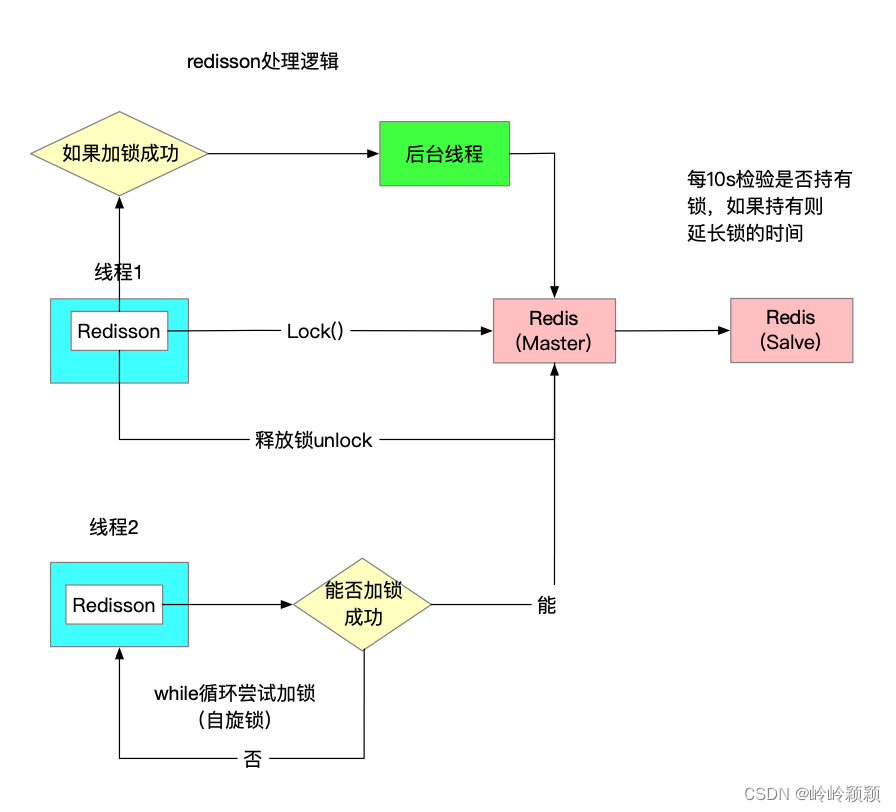
redission 实现分布式锁流程图:
代码如下所示:
/*** Redis分布式锁第四种方法** @param articleId* @return ArticleDTO*/
private ArticleDTO checkArticleByDBFour(Long articleId) {String redisLockKey =RedisConstant.REDIS_PAI + RedisConstant.REDIS_PRE_ARTICLE + RedisConstant.REDIS_LOCK + articleId;// 获取锁RLock lock = redissonClient.getLock(redisLockKey);//lock.lock();ArticleDTO article = null;try {//尝试加锁,最大等待时间3秒,上锁30秒自动解锁;时间结合自身而定if (lock.tryLock(3, 30, TimeUnit.SECONDS)) {article = articleDao.queryArticleDetail(articleId);} else {// 未获得分布式锁线程睡眠一下;然后再去获取数据Thread.sleep(200);this.queryDetailArticleInfo(articleId);}} catch (InterruptedException e) {e.printStackTrace();} finally {//判断该lock是否已经锁 并且 锁是否是自己的if (lock.isLocked() && lock.isHeldByCurrentThread()) {lock.unlock();}}return article;
}redission 首先获取锁(get lock()),然后尝试加锁,加锁成功后可以执行下面的业务逻辑,执行完毕之后,会释放该分布式锁。
redission 解决了 redis 实现分布式锁中出现的锁过期问题,还有释放他人锁的问题。
另外,它还是可重入锁:内部机制是默认锁过期时间是 30s,然后会有一个定时任务在每 10s 去扫描一下该锁是否被释放,如果没有释放那么就延长至 30s,这个机制就是看门狗机制。
如果请求没有获取到锁,那么它将 while 循环继续尝试加锁。
上面的 redission 我只是大概讲了一下用法,内部具体逻辑还没有讲解;大家如果感兴趣的话可以看下它得内部源码,相对来说也不是特别复杂。
4、总结
上面由简到繁地讲解了四种方式,建议采用Redission实现分布式锁,它基本上解决了所有问题。
redission 实际还存在一个问题,就是当 redis 是主从架构时,线程 A 刚刚成功的加锁了 master 节点,还没有同步到 slave 节点,此时 master 节点挂了,然后线程 B 这时过来是可以加锁的,但是实际上它已经加锁过了,这个问题涉及了高一致性 ,也就是 C 原则了;redission 是无法解决高一致性问题的。
如果想要解决高一致性可以使用红锁,或者 zk 锁;他们保证了高一致性,但是不建议使用,因为为了保证高一致性,它丢失了高可用性,对用户体验感不好,且上述问题出现的几率不大,不能因为很小的问题而舍弃其高可用性。
这里我也就不过多的对这两种锁来做具体的讲述,大家如果有兴趣的话可以自己找找文章,它们的原理无非就是必须多节点加锁成功才算加锁成功












