
1. 模型自动化测试
模型的测试中,不同类型的任务评测指标有显著差异,比如:
分类任务:
准确率(Accuracy):正确预测的比例。
精确度(Precision)、召回率(Recall)与F1分数(F1 Score):用于衡量二分类或多分类问题中正类别的识别效果。
文本生成任务:
BLEU (Bilingual Evaluation Understudy) 分数:主要用于机器翻译等自然语言处理任务中,通过比较候选翻译与一个或多个参考翻译之间的n-gram重叠来计算得分。
ROUGE (Recall-Oriented Understudy for Gisting Evaluation) 分数:常用于自动摘要评价,它基于n-gram召回率、精确率以及F-measure。
Perplexity (困惑度):用来衡量概率分布模型预测样本的不确定程度;越低越好。
图像识别/目标检测:
Intersection over Union (IoU):两个边界框相交部分面积与并集面积之比。
mAP (mean Average Precision):平均精度均值,广泛应用于物体检测任务中
ROUGE是基于召回率的评估指标,特别适用于 文本摘要、问答生成 和 机器翻译 等任务。其核心思想是通过对生成文本和参考文本的 n-gram 或 子序列 匹配程度进行评估。
ROUGE Scores (Recall Oriented Understudy for Gisting Evaluation)
rouge-n-(r/p/f): 这是基于词级别的n-gram匹配度量,其中n=1,意味着考虑单个词汇的重合情况;n=2,意味着考虑两个词汇组成的短语的重合情况;n=L(long),意味着考虑一个模型输出与测试用例中最长公共子序列的重合情况。
rouge-n-r:召回率(Recall),表示模型输出正确预测出测试用例的比例。
rouge-n-p:精确率(Precision),表示模型输出有多大部分也出现在测试用例中。
rouge-n-f:F1分数,是召回率和精确率的调和平均值,综合考量了两者的表现。
相关文章:ROUGE: A Package for Automatic Evaluation of Summaries (Chin-Yew Lin, 2004)
Rouge-L分数可以评估输出的SQL语句有多少部分是有用的,因此它能大致反映出模型的能力。
from rouge import Rouge
# 生成文本
generated_text = "你需要的sql: SELECT * FROM employees WHERE employee_id NOT IN (SELECT employee_id FROM job_history)。 你可以用这句SQL查找到你要的信息。"
# 参考文本列表
reference_texts = "SELECT * FROM employees WHERE employee_id NOT IN (SELECT employee_id FROM job_history)"
# 计算 ROUGE 指标
rouge = Rouge()
scores = rouge.get_scores(generated_text, reference_texts)
# 打印结果
print("ROUGE-1 p:", scores[0]["rouge-1"]["p"])
print("ROUGE-1 r:", scores[0]["rouge-1"]["r"])
print("ROUGE-1 f:", scores[0]["rouge-1"]["f"])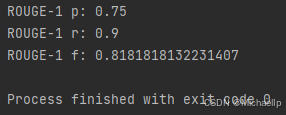
from rouge import Rouge
# 生成文本
generated_text = "SELECT * FROM employees WHERE employee_id NOT IN (SELECT employee_id FROM job_history)"
# 参考文本列表
reference_texts = "SELECT * FROM employees WHERE employee_id NOT IN (SELECT employee_id FROM job_history)"
# 计算 ROUGE 指标
rouge = Rouge()
scores = rouge.get_scores(generated_text, reference_texts)
# 打印结果
print("ROUGE-1 p:", scores[0]["rouge-1"]["p"])
print("ROUGE-1 r:", scores[0]["rouge-1"]["r"])
print("ROUGE-1 f:", scores[0]["rouge-1"]["f"])
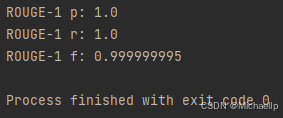
如何根据 Rouge 指标进行优化
1.优化Prompt
提示词工程就是研究如何构建和调整提示词,从而让大语言模型实现各种符合用户预期的任务的过程。利用one-shot和few-shot引导大模型给出正确答案。
2.微调
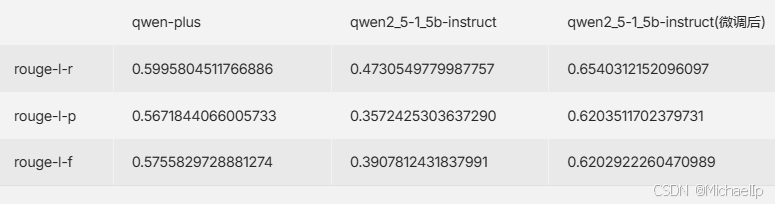
qwen2_5-1_5b-instruct 是比 qwen-plus反应更快的模型,当准确率相对较低,当如果针对具体业务微调后,Rouge分数比qwen-plus高,反应还是原来那样快。
3.Enrich补全需求
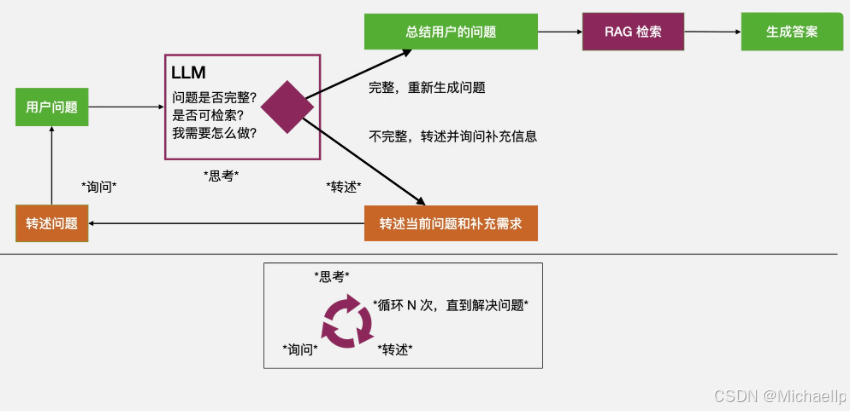
一种理想的通过多轮对话补全需求的方案。该设想是通过大模型多次主动与用户沟通,不断收集信息,完善对用户真实意图的理解,补全执行用户需求所需的各项参数。如下图所示。
2. RAG自动化测试
Ragas是现在评估RAG系统的非常标准化的工具。
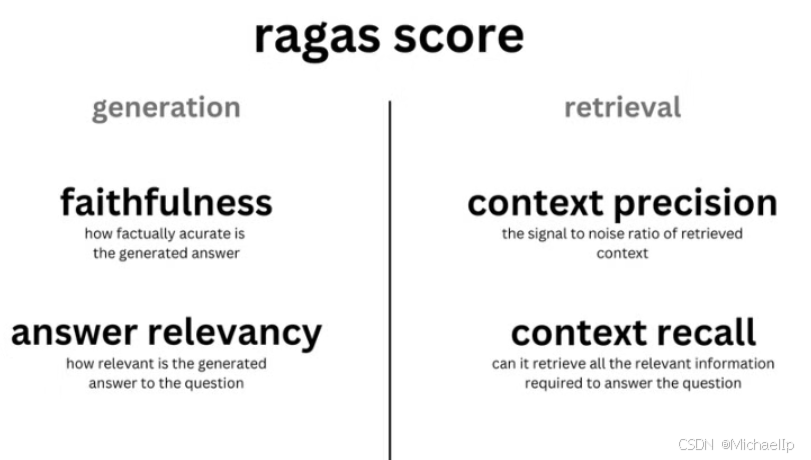
Ragas 默认提供了多项指标,可以用来全链路评测应用的问答质量。比如:
整体回答质量的评估:
Answer Correctness,用于评估 RAG 应用生成答案的准确度。
生成环节的评估:
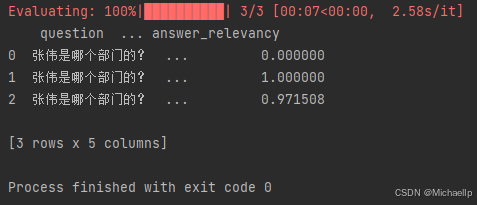
Answer Relevancy,用于评估 RAG 应用生成的答案是否与问题相关。
Faithfulness,用于评估 RAG 应用生成的答案和检索到的参考资料的事实一致性。
召回阶段的评估:
Context Precision,用于评估 contexts 中与准确答案相关的条目是否排名靠前、占比高(信噪比)。
Context Recall,用于评估有多少相关参考资料被检索到,越高的得分意味着更少的相关参考资料被遗漏。
评估前你需要准备三种数据:
- question,输入给 RAG 应用的问题
- answer,RAG 应用给出的答案
- ground_truth,你预先知道的正确的答案
为了方便演示,我会为你提供“不知道”、“幻觉”、“正确回答”三种回答
安装Ragas
pip install ragas==0.2.6
pip show ragas
了解整体回答 Answer Correctness 的计算过程
Answer correctness 的得分由生成答案(answer)和正确答案(ground truth)的语义相似度和事实准确度计算得出。
1.语义相似度
语义相似度是通过文本向量模型(Text Embedding Model)计算 answer 和 ground truth 的文本向量,然后计算两个文本向量的余弦相似度。
2.事实准确度
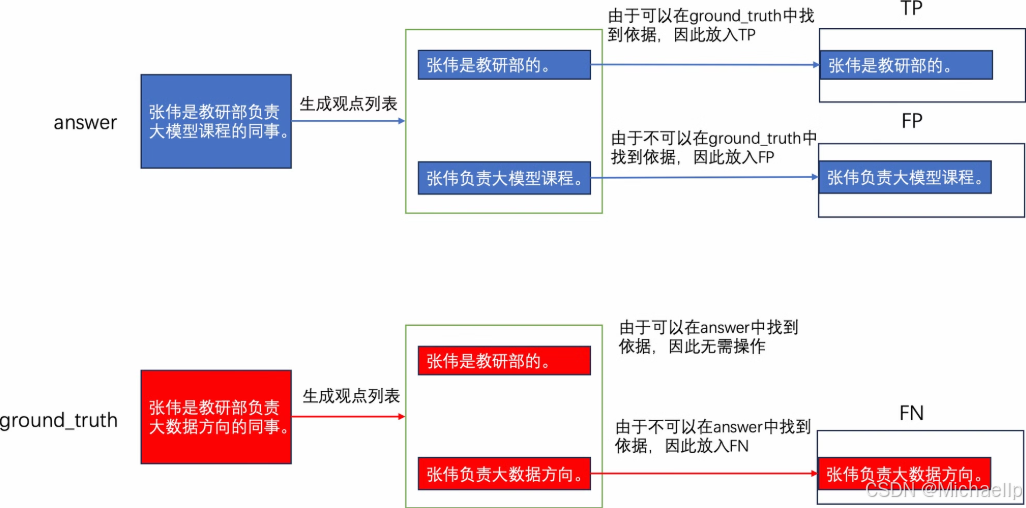
生成观点列表:
用大模型分别提取 answer 和 ground_truth 的观点。
例如:
answer: [“张伟是教研部的”, “张伟负责大模型课程”]
ground_truth: [“张伟是教研部的”, “张伟负责大数据方向”]
匹配观点:
TP (True Positive): answer 和 ground_truth 匹配的观点。
例如: “张伟是教研部的”
FP (False Positive): answer 有但 ground_truth 没有的观点。
例如: “张伟负责大模型课程”
FN (False Negative): ground_truth 有但 answer 没有的观点。
例如: “张伟负责大数据方向”
计算 F1 分数:F1 = TP / (TP + 0.5 * (FP + FN)) 如果 TP > 0,否则 F1 = 0
例如:TP = 1, FP = 1, FN = 1 F1 = 1 / (1 + 0.5 * (1 + 1)) = 0.5
分数汇总
得到语义相似度和事实准确度的分数后,对两者加权求和,即可得到最终的 Answer Correctness 的分数。
Answer Correctness 的得分 = 0.25 * 语义相似度得分 + 0.75 * 事实准确度得分
相关代码
from langchain_community.llms.tongyi import Tongyi
from langchain_community.embeddings import DashScopeEmbeddings
from datasets import Dataset # ragas评估工具及相关指标
from ragas import evaluate
from ragas.metrics import faithfulness,answer_relevancy,context_recall,context_precision,answer_correctnessfrom config.load_key import load_key
load_key()# =============== 准备示例数据 ===============
data_samples = {'question': [ # 测试问题列表'张伟是哪个部门的?','张伟是哪个部门的?','张伟是哪个部门的?'],'answer': [ # 系统生成的不同答案,用于评估答案质量'根据提供的信息,没有提到张伟所在的部门。如果您能提供更多关于张伟的信息,我可能能够帮助您找到答案。','张伟是人事部门的','张伟是教研部的'],'ground_truth':[ # 标准答案,用于对比评估'张伟是教研部的成员','张伟是教研部的成员','张伟是教研部的成员'],'contexts' : [['提供⾏政管理与协调⽀持,优化⾏政⼯作流程。 ', '绩效管理部 韩杉 李⻜ I902 041 ⼈⼒资源'],['李凯 教研部主任 ', '牛顿发现了万有引力'],['牛顿发现了万有引力', '张伟 教研部工程师,他最近在负责课程研发'],]
}# =============== 创建数据集 ===============
# 将字典格式数据转换为Dataset对象,便于评估使用
dataset = Dataset.from_dict(data_samples)# =============== 进行评估 ===============
score = evaluate(dataset = dataset, # 要评估的数据集metrics=[answer_correctness], # 使用answer_correctness指标评估答案的正确性# 使用通义千问plus模型作为评估模型llm=Tongyi(model_name="qwen-plus"),# 使用DashScope的文本向量化模型进行文本编码embeddings=DashScopeEmbeddings(model="text-embedding-v3")
)# 将评估结果转换为pandas数据框并打印
print(score.to_pandas())把上面代码中metrics替换成下面的ragas评估指标
ragas评估指标说明:
- answer_correctness: 评估答案的正确性
- context_recall: 评估上下文的召回率
- context_precision: 评估上下文的精确度
- faithfulness: 评估答案与上下文的一致性
- answer_relevancy: 评估答案与问题的相关性
当metrics=[answer_correctness]
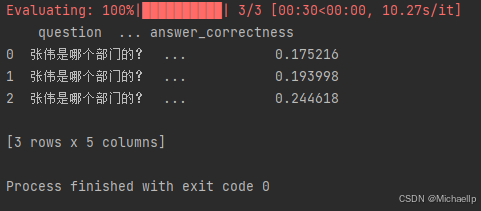
当metrics=[answer_correctness]
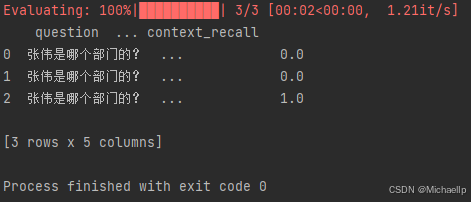
当metrics=[context_precision]
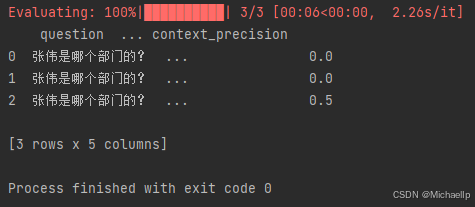
当metrics=[faithfulness]
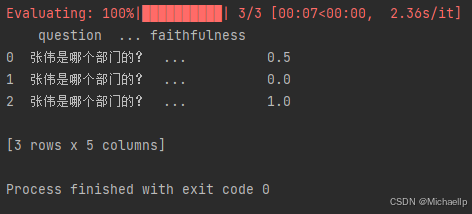
当metrics=[answer_relevancy]
如何根据 Ragas 指标进行优化
做评测的最终目的不是为了拿到分数,而是根据这些分数确定优化的方向。上面代码展示了answer correctness、context recall、context precision三个指标的概念与计算方法,当观察到某几个指标的分数较低时,应该制定相应的优化措施。
Context Recall
context recall指标评测的是RAG应用在检索阶段的表现。如果该指标得分较低,可以尝试从以下方面进行优化:
1.检查知识库:如果你发现某些测试样本缺少相关知识,则需要对知识库进行补充。
2.更换embedding模型
MTEB——海量文本嵌入基准测试(MassiveTextEmbeddingBenchmark),下面是英文和中文Embedding 排行榜(截至 2025/01/01)
https://huggingface.co/spaces/mteb/leaderboard
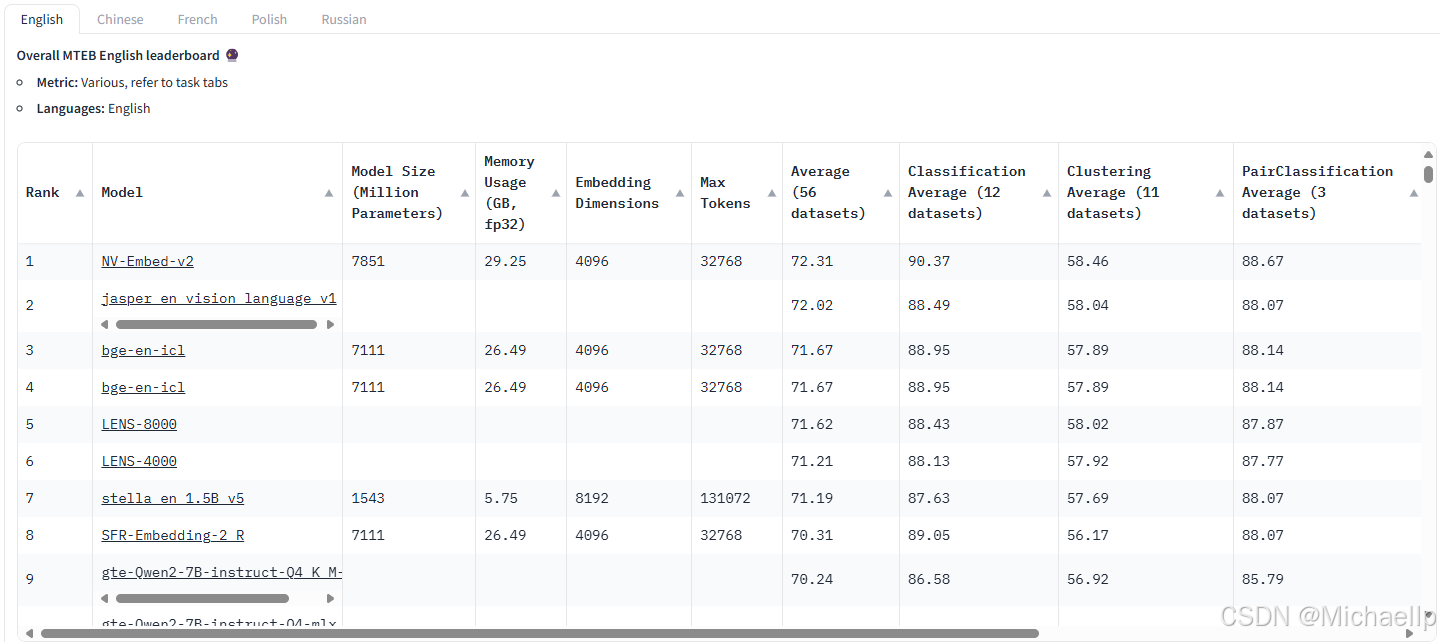
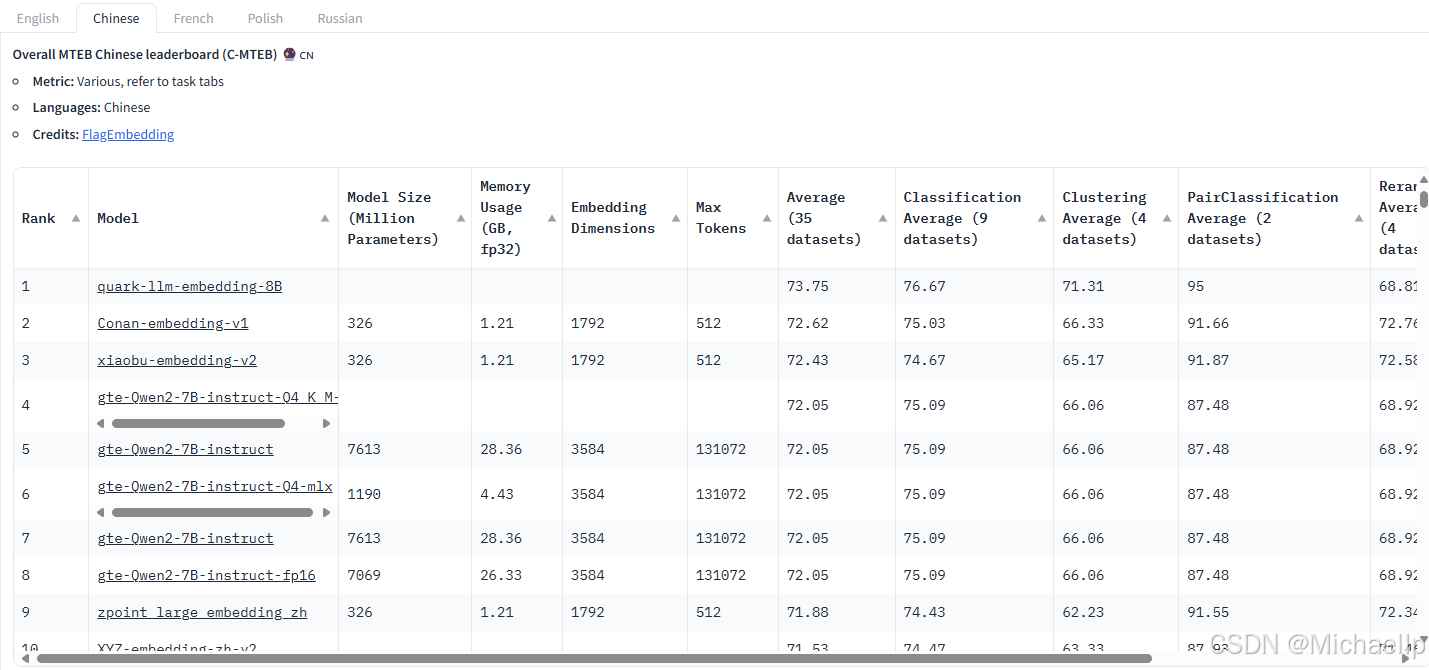
3.query改写

Context Precision
与context recall一样,context precision指标评测的也是RAG应用在检索阶段的表现,但是更注重相关的文本段是否具有靠前的排名。如果该指标得分较低,你可以尝试context recall中的优化措施,并且可以尝试在检索阶段加入rerank(重排序),来提升相关文本段的排名。
Answer Correctness
answer correctness指标评测的是RAG系统整体的综合指标。如果该指标得分较低,而前两项分数较高,说明RAG系统在检索阶段表现良好,但是生成阶段出了问题。你可以尝试前边教程学到的方法,如优化prompt、调整大模型生成的超参数(如temperature)等,你也可以更换性能更加强劲的大模型,甚至对大模型进行微调等方法来提升生成答案的准确度。










 "python爬虫篇(项目案列讲解-爬取小说)")
——无语义的布局标签和字符实体 "HTML(7)——无语义的布局标签和字符实体")
