
参考资料:https://github.com/datawhalechina/happy-llm
3.1.1 BERT
BERT(Bidirectional Encoder Representations from Transformers)是由 Google 团队在 2018 年发布的预训练语言模型,标志着预训练+微调范式在自然语言处理(NLP)领域的广泛应用。BERT 在多个 NLP 任务上取得了 SOTA(State Of The Art)性能,推动了预训练模型的发展,直到 LLM(Large Language Models)的出现才逐渐被取代。
BERT 继承了 Transformer 的架构,并在此基础上进行了优化,同时引入了两个创新的预训练任务(MLM 和 NSP),以更好地捕捉双向语义关系。
(1)思想沿承
BERT 的核心思想包括:
-
Transformer 架构:
-
BERT 基于 Transformer 的 Encoder 部分,通过堆叠多层 Encoder Layer 来扩大模型参数,提升模型性能。
-
-
预训练+微调范式:
-
BERT 采用了预训练+微调的模式,先在海量无监督语料上进行预训练,再针对下游任务进行微调。
-
(2)模型架构——Encoder Only
BERT 的模型架构主要由以下部分组成:
-
Embedding 层:
-
将输入的 token 索引映射为嵌入向量。
-
-
位置编码(Positional Encoding):
-
使用可训练的相对位置编码,而不是 Transformer 的正余弦位置编码。
-
-
Encoder:
-
由多层 Encoder Layer 组成,每层包含多头自注意力和前馈神经网络。
-
-
分类头(Prediction Heads):
-
用于将 Encoder 的输出转换为特定任务的输出,例如分类任务的类别概率。
-

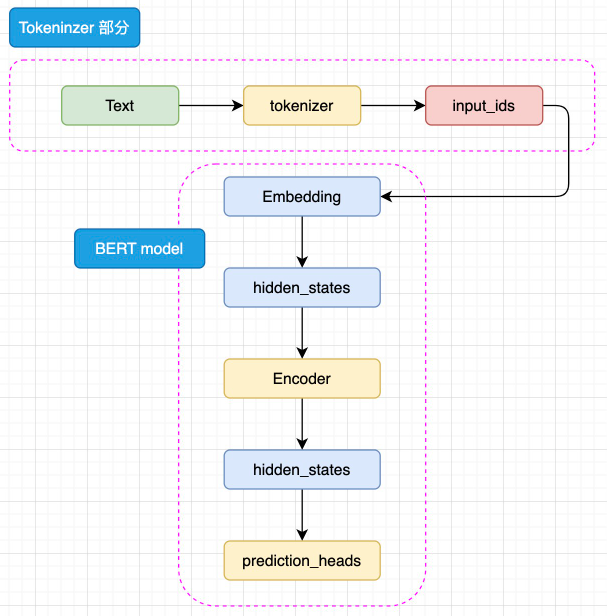
BERT 的模型架构如下:
-
输入文本序列经过分词器(tokenizer)转化为
input_ids。 -
input_ids进入 Embedding 层,转化为特定维度的hidden_states。 -
hidden_states经过 Encoder 块处理。 -
最终的
hidden_states通过分类头(prediction_heads)得到任务输出。
BERT 有两种规模的模型:
-
BERT-Base:12 层 Encoder Layer,768 维隐藏层,总参数量 110M。
-
BERT-Large:24 层 Encoder Layer,1024 维隐藏层,总参数量 340M。
(3)预训练任务——MLM + NSP
BERT 的创新之处在于其提出的两个预训练任务:
-
掩码语言模型(MLM,Masked Language Model):
-
随机遮蔽部分 token,要求模型根据上下文预测被遮蔽的 token。
-
通过这种方式,模型可以学习双向语义关系。
-
在预训练时,15% 的 token 被随机选择用于遮蔽,其中:
-
80% 的概率被遮蔽为
<MASK>。 -
10% 的概率被替换为任意一个 token。
-
10% 的概率保持不变。
-
-
这种策略消除了预训练和微调之间的不一致性,并迫使模型学习上下文信息。
-
-
下一句预测(NSP,Next Sentence Prediction):
-
判断两个句子是否是连续的上下文。
-
通过这种方式,模型可以学习句子之间的关系,适配句级 NLU 任务。
-
正样本是连续的句子对,负样本是随机打乱的句子对。
-
BERT 的预训练使用了 3.3B token 的语料,包括 800M 的 BooksCorpus 和 2500M 的英文维基百科语料。训练时,BERT 使用了 16 块 TPU(BERT-Base)和 64 块 TPU(BERT-Large),训练了 4 天。
(4)下游任务微调
BERT 的预训练-微调范式使得模型能够高效地迁移到各种下游任务:
-
输入格式:
-
每个输入文本序列的首部加入特殊 token
<CLS>,用于表示整句的状态。
-
-
微调策略:
-
在预训练模型的基础上,使用少量全监督数据进行微调。
-
对于不同任务,可以修改分类头(prediction_heads)以适配任务需求。
-
例如,文本分类任务可以直接使用
<CLS>对应的特征向量进行分类。
-
BERT 在多个 NLP 任务上取得了 SOTA 性能,成为 NLU 领域的霸主。即使在 LLM 时代,BERT 仍然在某些特定任务上表现出色,尤其是在标注数据丰富且强调高吞吐的任务中。
3.1.2 RoBERTa
RoBERTa 是 Facebook 发布的一个优化版的 BERT 模型,主要在以下几个方面进行了优化:
(1)去掉 NSP 预训练任务
-
背景:NSP(Next Sentence Prediction)任务被认为过于简单,可能对下游任务微调时没有明显益处,甚至可能带来负面效果。
-
实验:RoBERTa 设置了四个实验组,结果表明去掉 NSP 任务的组(特别是单文档的 MLM 组)在下游任务上表现更好。
-
改进:RoBERTa 去掉了 NSP,只使用 MLM(Masked Language Model)任务。
-
动态遮蔽:RoBERTa 将 Mask 操作放到了训练阶段,即动态遮蔽策略,使每个 Epoch 的训练数据 Mask 位置不一致,更高效且易于实现。
(2)更大规模的预训练数据和预训练步长
-
数据规模:RoBERTa 使用了 160GB 的无监督语料,包括 BookCorpus、英文维基百科、CC-NEWS、OPENWEBTEXT 和 STORIES,是 BERT 的 10 倍。
-
训练策略:
-
使用更大的 batch size(8K,对比 BERT 的 256)。
-
在 8K 的 batch size 下训练 31K Step,总训练 token 数与 BERT 一样是 3.3B,但模型性能更好。
-
一共训练了 500K Step(约合 66 个 Epoch)。
-
全部在 512 长度上进行训练,不再采用 BERT 的分阶段训练策略。
-
-
算力需求:训练一个 RoBERTa,Meta 使用了 1024 块 V100(32GB 显存)训练了一天。
(3)更大的 BPE 词表
-
背景:BERT 原始的 BPE 词表大小为 30K。
-
改进:RoBERTa 选择了 50K 大小的词表来优化模型的编码能力,提升模型对子词的处理能力。
RoBERTa 的影响
-
性能提升:通过上述优化,RoBERTa 在多个下游任务上取得了 SOTA 性能,一度成为 BERT 系模型中最热门的预训练模型。
-
预训练的重要性:RoBERTa 的成功证明了更大规模的预训练数据、更长的训练步长和更大的词表大小的重要性。
-
对后续模型的影响:这些优化策略为后续的 LLM(Large Language Models)的发展奠定了基础。
3.1.3 ALBERT
ALBERT(A Lite BERT)是基于 BERT 架构进行优化的模型,旨在通过减小模型参数量的同时保持甚至提升模型性能。ALBERT 通过优化模型结构和改进预训练任务,成功地以更小的参数量实现了超越 BERT 的性能。虽然 ALBERT 的一些改进思想没有被广泛采用,但其方法和新预训练任务 SOP 仍对 NLP 领域具有重要的参考意义。
ALBERT 的主要优化策略包括以下几个方面:
(1)优化一:将 Embedding 参数进行分解
BERT 等预训练模型具有庞大的参数量,BERT-large 拥有 24 层 Encoder Layer,1024 维隐藏层,总参数量达 340M。其中,Embedding 层的参数矩阵维度为 V×H,其中 V 为词表大小 30K,H 为隐藏层大小 768,导致 Embedding 层参数达到 23M。当隐藏层维度增加到 2048 时,Embedding 层参数会膨胀到 61M,极大增加了模型的计算开销。
ALBERT 对 Embedding 层的参数矩阵进行了分解,让 Embedding 层的输出维度和隐藏层维度解绑。具体方法是在 Embedding 层后面加入一个线性矩阵进行维度变换。ALBERT 设置 Embedding 层的输出维度为 128,然后通过一个 128×768 的线性矩阵将 Embedding 层的输出升维到隐藏层大小。这样,Embedding 层的参数从 V×H 降低到 V×E+E×H,当 E 远小于 H 时,该方法对 Embedding 层参数的优化效果显著。
(2)优化二:跨层进行参数共享
通过对 BERT 的参数进行分析,ALBERT 发现各个 Encoder 层的参数高度一致。因此,ALBERT 提出让各个 Encoder 层共享模型参数,以减少模型的参数量。
在具体实现上,ALBERT 仅初始化了一个 Encoder 层。在计算过程中,虽然仍然会进行 24 次计算,但每一次计算都是经过这一个 Encoder 层。这样,虽然是 24 层 Encoder 计算的模型,但只有一层 Encoder 参数,从而大大降低了模型参数量。ALBERT 通过实验证明,相较于 334M 参数量的 BERT,同样是 24 层 Encoder 但将隐藏层维度设为 2048 的 ALBERT(xlarge 版本)仅有 59M 参数量,但在具体效果上还优于 BERT。
然而,上述优化虽然显著减小了模型参数量并提高了模型效果,但也存在明显不足。尽管 ALBERT 的参数量远小于 BERT,但训练效率仅略微优于 BERT,因为在模型设置中,虽然各层共享权重,但计算时仍需通过 24 次 Encoder Layer 的计算,导致训练和推理速度较 BERT 更慢。这也是 ALBERT 最终未能取代 BERT 的一个重要原因。
(3)优化三:提出 SOP 预训练任务
类似于 RoBERTa,ALBERT 也认为 NSP(Next Sentence Prediction)任务过于简单,无法显著提升模型效果。但与 RoBERTa 直接去掉 NSP 不同,ALBERT 选择改进 NSP,增加其难度,以优化模型的预训练。
在传统的 NSP 任务中,正例由两个连续句子组成,负例则是从任意两篇文档中抽取出的句对,模型较容易判断正负例,无法很好地学习深度语义。ALBERT 提出的 SOP(Sentence Order Prediction)任务改进了这一点。SOP 任务的正例同样由两个连续句子组成,但负例是将这两个句子的顺序反过来。也就是说,模型不仅要拟合两个句子之间的关系,更要学习其顺序关系,从而大大提升了预训练的难度。
例如:
-
输入:
-
Sentence A:I love you.
-
Sentence B: Because you are wonderful.
-
-
输出:1(正样本)
-
输入:
-
Sentence A:Because you are wonderful.
-
Sentence B: I love you.
-
-
输出:0(负样本)
ALBERT 通过实验证明,SOP 预训练任务对模型效果有显著提升。使用 MLM + SOP 预训练的模型效果优于仅使用 MLM 预训练的模型,更优于使用 MLM + NSP 预训练的模型。
通过上述三点优化,ALBERT 成功地以更小的参数量实现了更强的性能。尽管其架构带来的训练和推理效率降低限制了模型的进一步发展,但打造更宽模型的思路仍为众多更强大的模型提供了参考价值。












