
Easysearch 1.10 版本在 IK 词典部分增加了字段级别词典的功能。
字段级别词典的功能支持用户对不同的字段设置不同的分词词库,用户既可以完全使用自己的词库,也支持在 ik 默认的词库上增加自定义的词库内容。
在整体使用上,ik 自定义词库的设计是比较灵活的,用户不仅可以通过分词器设置,自由的应用到各个字段。存储词典的方式也从固定文件和远程连接修改成了读取本地集群中默认的词库索引,减少了自定义词库的配置成本。当然,这个词库索引也可以由用户自定义,只要能和默认的词库索引保持一样的结构就好。
好了,现在让我们具体看一下 ik 字段级别词典的使用方法吧。
词库存储位置
默认的词库索引是 .analysis_ik 索引,IK 插件自动初始化的 .analysis_ik 索引。
用户可以自定义使用某个索引替代 .analysis_ik(设置参数下面会提及),但是要保持和 .analysis_ik 一个的 mapping 结构和使用同一个 pipeline。
.analysis_ik 词库需要存储的格式如下:
POST .analysis_ik/_doc
{"dict_key": "test_dic","dict_type": "main_dicts","dict_content": "dict_content": """中华人民共和国
中文万岁
秋水共长天"""
}
主要使用字段
- dict_content:词典内容字段。各个词典以换行符分隔。
- dict_key:自定义词典名。对应自定义词典中设置的 dict_key。
- dict_type:字典类型,可选 “main_dicts”, “stopwords_dicts”, “quantifier_dicts” 三个值。其中任意 dict_key 的"main_dicts"必须存在。
如何使用自定义词库
自定义词库的生效主要通过自定义 tokenizer 进行设置。
PUT my-index-000001
{"settings": {"analysis": {"analyzer": {"my_custom_analyzer": {"type": "custom","tokenizer": "my_tokenizer"}},"tokenizer": {"my_tokenizer": {"type": "ik_max_word","custom_dict_enable": true,"load_default_dicts":true,"lowcase_enable": true,"dict_key": "test_dic","dict_index":"custom_index"}}}},"mappings": {"properties": {"test_ik": {"type": "text","analyzer": "my_custom_analyzer"}}}
}
其中
- custom_dict_enable:布尔值,默认 false,true 则可以定制词典读取路径,否则 load_default_dicts / dict_key / dict_index 均失效。
- load_default_dicts:布尔值,默认 true,定制的词典是否包含默认的词典库。
- lowcase_enable:布尔值,默认为 true,是否大小写敏感,false 则保留原来文本的大小写。
- dict_key:string。对应词库索引中的 dict_key 字段内容。如果词典名不匹配,则会装载错误或者直接报错 。
- dict_index: string。词库索引名称,默认是 .analysis_ik。可以自定义,但是要保持和 mapping 结构以及 pipeline 一致。
词库内容怎么更新
词库现阶段只接受追加内容,没有删除词库数据的功能。如果在同一条数据上进行修改则也被视为追加。暂时不建议对词库内容进行删除或者修改,可能会造成节点间词库的混乱**。**
词库的追加内容是能自动被程序探测的,这个主要依赖于 .analysis_ik 的时间戳字段和 pipeline 执行。
# 词典索引写入需要的默认时间戳 pipeline
GET _ingest/pipeline/ik_dicts_default_date_pipeline
{"ik_dicts_default_date_pipeline": {"processors": [{"set": {"field": "upload_dicts_timestamp","value": "{{_ingest.timestamp}}","override": true}}]}
}# 词典索引的结构
GET .analysis.ik
{".analysis.ik": {"aliases": {},"mappings": {"properties": {"dict_content": {"type": "text","analyzer": "custom_analyzer"},"dict_key": {"type": "keyword"},"dict_type": {"type": "keyword"},"upload_dicts_timestamp": {"type": "date"}}},"settings": {"index": {"number_of_shards": "1","provided_name": ".analysis.ik","default_pipeline": "ik_dicts_default_date_pipeline","creation_date": "1738910858601","analysis": {"analyzer": {"custom_analyzer": {"type": "custom","tokenizer": "pattern_tokenizer"}},"tokenizer": {"pattern_tokenizer": {"pattern": "\n","type": "pattern"}}},"number_of_replicas": "1","uuid": "bmBY_qf3TpW_Qyw_1tOq2Q","version": {"created": "1090199"}}}}
}
这里 ik_dicts_default_date_pipeline 会对每一条写入词库的数据赋予当前 upload_dicts_timestamp 时间戳。ik 会记录当前词库的最大时间戳,然后每分钟都会去查询一次词库索引现有的最大时间戳。如果查到词库索引的最大的时间戳大于上次记录到的时间戳,则对这段时间内的词库内容都进行加载。
代码样例
测试词典数据
POST .analysis_ik/_doc
{"dict_key": "test_dic","dict_type": "main_dicts","dict_content": """中华人民共和国中文万岁秋水共长天"""
}
测试索引
PUT my-index-000001
{"settings": {"analysis": {"analyzer": {"my_custom_analyzer": {"type": "custom","tokenizer": "my_tokenizer"}},"tokenizer": {"my_tokenizer": {"type": "ik_max_word","custom_dict_enable": true,"load_default_dicts":false,"lowcase_enable": true,"dict_key": "test_dic"}}}},"mappings": {"properties": {"test_ik": {"type": "text","analyzer": "my_custom_analyzer"}}}
}
分词测试
POST my-index-000001/_analyze
{"field": "test_ik","text": ["中华人民共和国 中文万岁 秋水共长天"]
}
# 返回结果
{"tokens": [{"token": "中华人民共和国","start_offset": 0,"end_offset": 7,"type": "CN_WORD","position": 0},{"token": "中文万岁","start_offset": 8,"end_offset": 12,"type": "CN_WORD","position": 1},{"token": "万","start_offset": 10,"end_offset": 11,"type": "TYPE_CNUM","position": 2},{"token": "岁","start_offset": 11,"end_offset": 12,"type": "CN_CHAR","position": 3},{"token": "秋水共长天","start_offset": 13,"end_offset": 18,"type": "CN_WORD","position": 4}]
}
测试未加载的词典
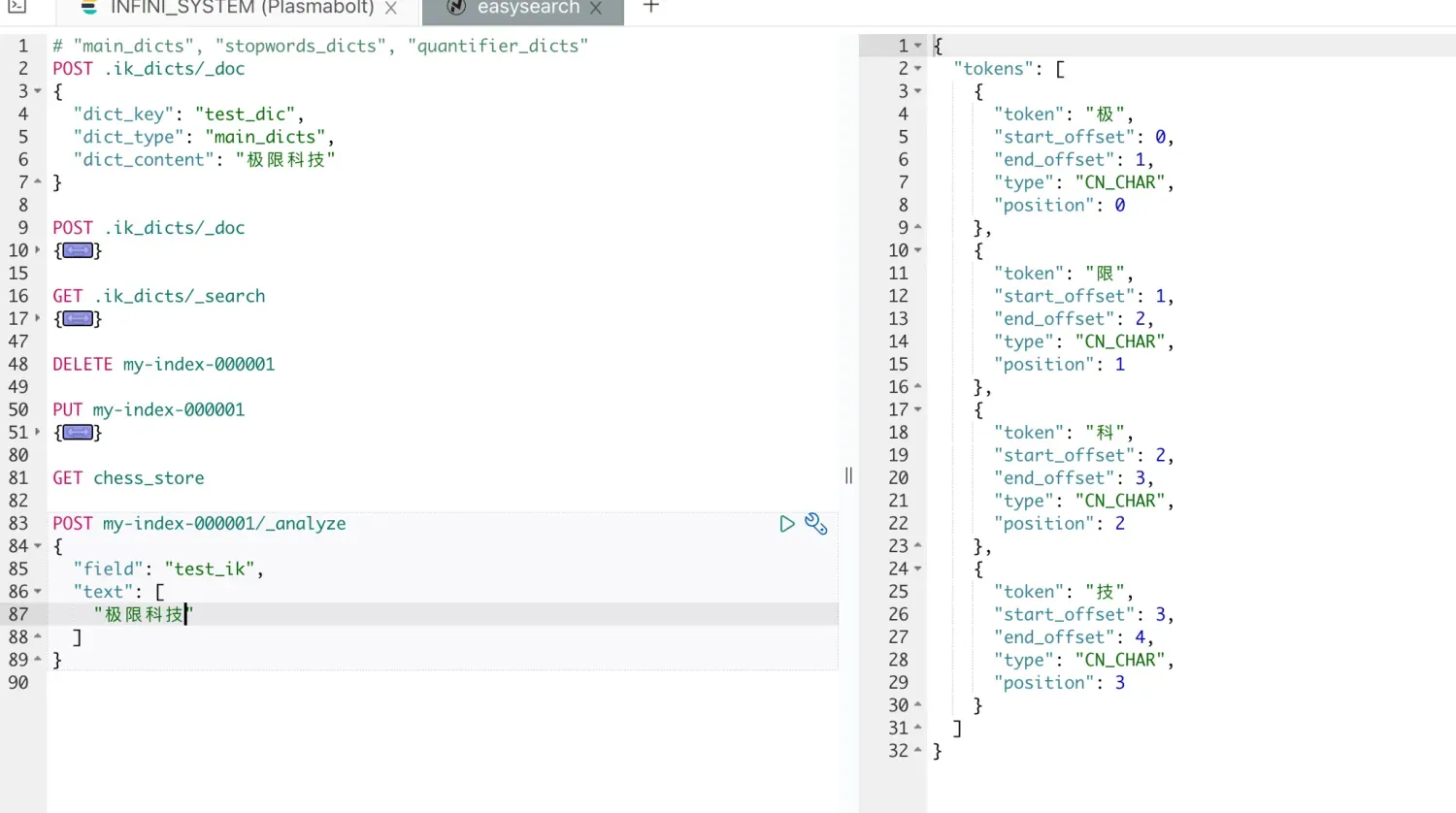
追加词典数据
POST .analysis_ik/_doc
{"dict_key": "test_dic","dict_type": "main_dicts","dict_content": "极限科技"
}
测试新加载的词典
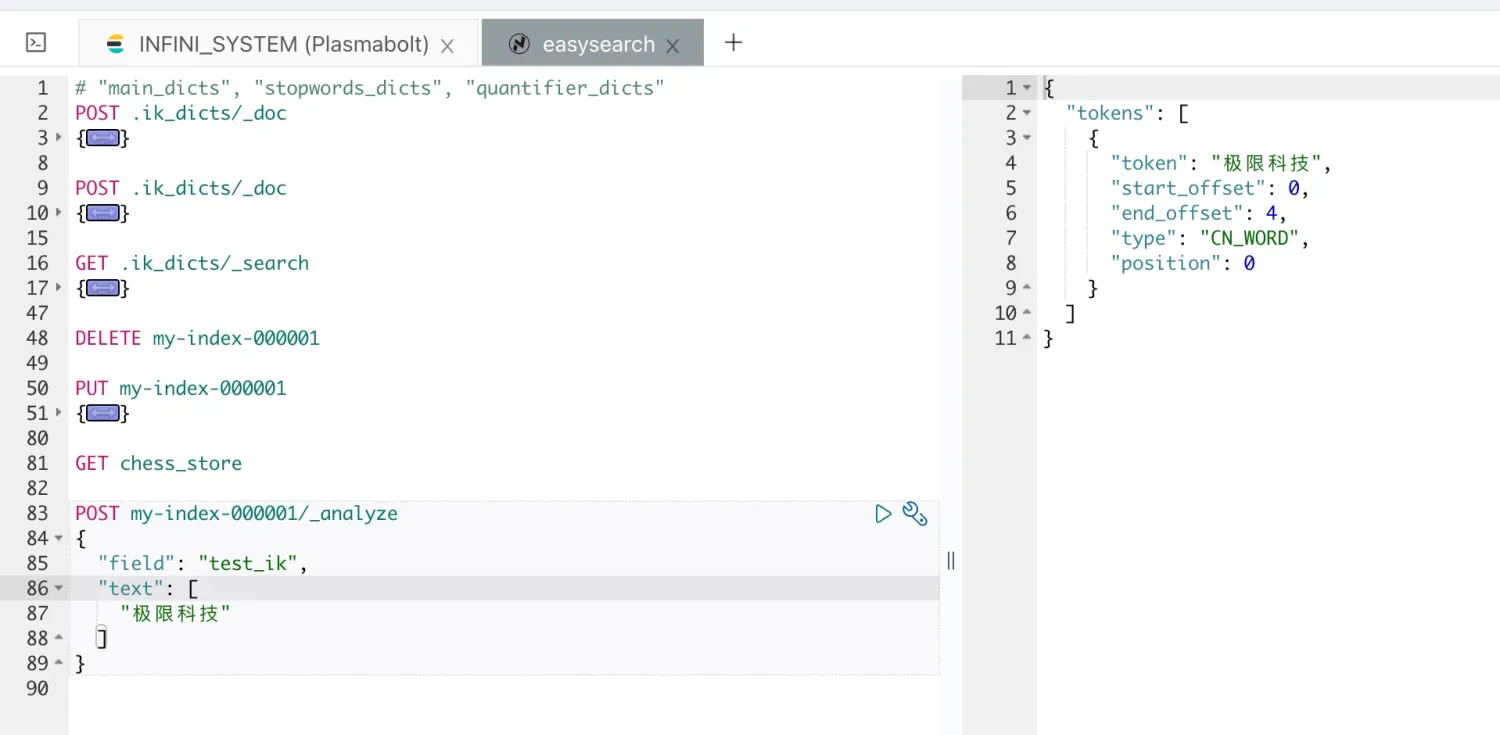
好了,以上就是 ik 字段级别词典的主要功能,具体内容欢迎大家使用。
关于 Easysearch

INFINI Easysearch 是一个分布式的搜索型数据库,实现非结构化数据检索、全文检索、向量检索、地理位置信息查询、组合索引查询、多语种支持、聚合分析等。Easysearch 可以完美替代 Elasticsearch,同时添加和完善多项企业级功能。Easysearch 助您拥有简洁、高效、易用的搜索体验。
官网文档:https://infinilabs.cn/docs/latest/easysearch
作者:金多安,极限科技(INFINI Labs)搜索运维专家,Elastic 认证专家,搜索客社区日报责任编辑。一直从事与搜索运维相关的工作,日常会去挖掘 ES / Lucene 方向的搜索技术原理,保持搜索相关技术发展的关注。












