
项目的克隆
打开yolov5官网(GitHub - ultralytics/yolov5 at v5.0),下载yolov5的项目:
环境的安装(免额外安装CUDA和cudnn)
打开anaconda的终端,创建新的名为yolov5的环境(python选择3.8版本):
conda create -n yolov5 python=3.8

执行如下命令,激活这个环境:
conda activate yolov5

打开pytorch的官网,选择自己显卡对应的pytorch版本(我的显卡为GTX1650,这里选择1.8.0pytorch版本):
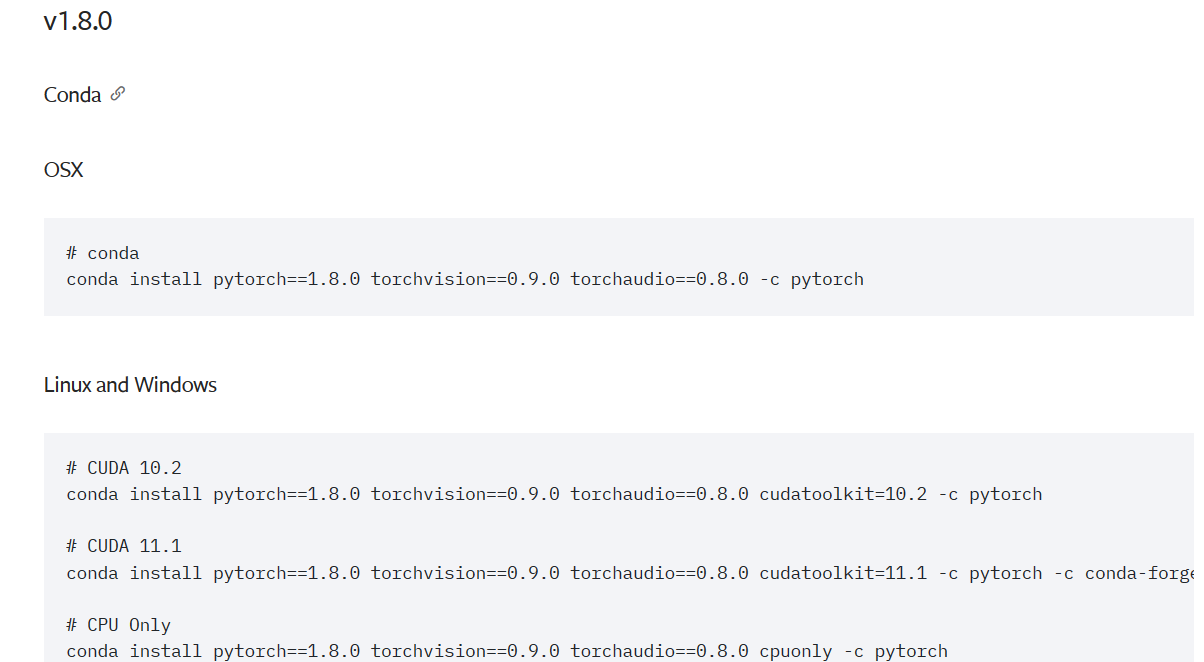
选择CUDA版本(这里我选择10.2),复制命令到anaconda终端执行:

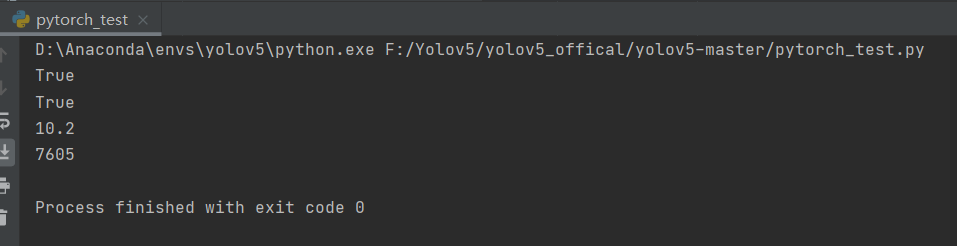
至此pytorch环境安装完成,接下来验证CUDA和cudnn版本,打开Ptcharm,执行如下代码:
import torch
print(torch.cuda.is_available())
print(torch.backends.cudnn.is_available())
print(torch.cuda_version)
print(torch.backends.cudnn.version())
输出如下结果表示安装成功:
利用labelimg标注数据集:
labelimg的安装:
打开cmd命令控制台,输入如下的命令下载labelimg相关的依赖:
pip install labelimg -i https://pypi.tuna.tsinghua.edu.cn/simple
数据准备:
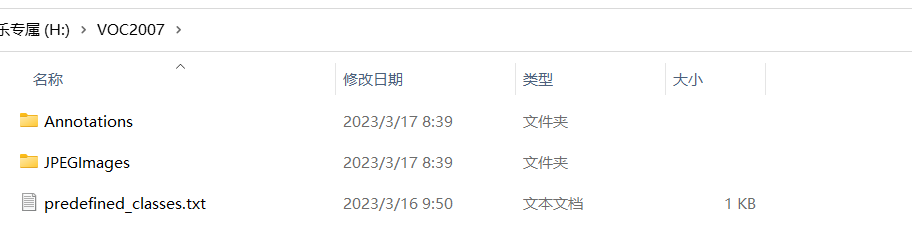
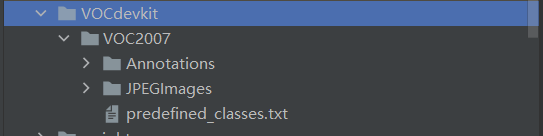
新建一个名为VOC2007的文件夹,在里面创建一个名为JPEGImages的文件夹存放需要打标签的图片文件;再创建一个名为Annotations的文件夹存放标注的标签文件;最后创建一个名为 predefined_classes.txt 的txt文件来存放所要标注的类别名称:
进入到刚刚创建的VOC2007路径,执行cmd命令:

输入如下的命令打开labelimg并初始化predefined_classes.txt里面定义的类:
labelimg JPEGImages predefined_classes.txt
打开view设置,勾选如下选项(建议勾选):
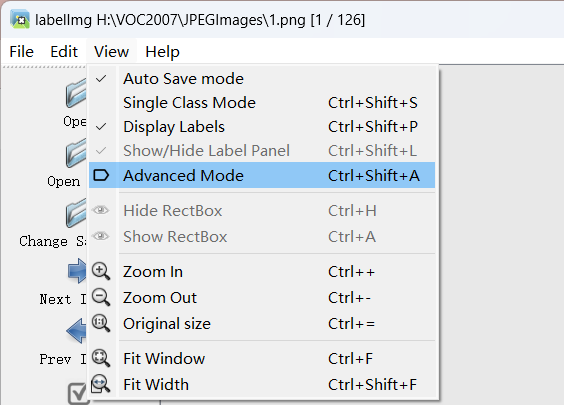
标注数据:
按下快捷键W调出标注十字架,选择需要标注的对象区域,并定义自己要标注的类别:
打完标签后的图片会在Annotations 文件夹下生成对应的xml文件:
数据集格式转化及训练集和验证集划分
利用pycharm打开从yolov5官网下载的yolov5项目,在该项目目录下创建名为VOCdevkit的文件夹,并将刚才的VOC2007文件夹放入:
在VOCdevkit的同级目录下创建新的python文件,执行如下代码:
(注:classes里面必须正确填写xml里面已经标注好的类这里为classes = [“fanbingbing”, “jiangwen”, “liangjiahui”, “liuyifei”, “zhangziyi”, “zhoujielun”])
import xml.etree.ElementTree as ET
import pickle
import os
from os import listdir, getcwd
from os.path import join
import random
from shutil import copyfileclasses = ["fanbingbing", "jiangwen", "liangjiahui", "liuyifei", "zhangziyi", "zhoujielun"]
# classes=["ball"]TRAIN_RATIO = 80def clear_hidden_files(path):dir_list = os.listdir(path)for i in dir_list:abspath = os.path.join(os.path.abspath(path), i)if os.path.isfile(abspath):if i.startswith("._"):os.remove(abspath)else:clear_hidden_files(abspath)def convert(size, box):dw = 1. / size[0]dh = 1. / size[1]x = (box[0] + box[1]) / 2.0y = (box[2] + box[3]) / 2.0w = box[1] - box[0]h = box[3] - box[2]x = x * dww = w * dwy = y * dhh = h * dhreturn (x, y, w, h)def convert_annotation(image_id):in_file = open("F:/Yolov5/yolov5_offical/yolov5-master/VOCdevkit/VOC2007/Annotations/%s.xml" % image_id)out_file = open('F:/Yolov5/yolov5_offical/yolov5-master/VOCdevkit/VOC2007/YOLOLabels/%s.txt' % image_id, 'w')tree = ET.parse(in_file)root = tree.getroot()size = root.find('size')w = int(size.find('width').text)h = int(size.find('height').text)for obj in root.iter('object'):difficult = obj.find('difficult').textcls = obj.find('name').textif cls not in classes or int(difficult) == 1:continuecls_id = classes.index(cls)xmlbox = obj.find('bndbox')b = (float(xmlbox.find('xmin').text), float(xmlbox.find('xmax').text), float(xmlbox.find('ymin').text),float(xmlbox.find('ymax').text))bb = convert((w, h), b)out_file.write(str(cls_id) + " " + " ".join([str(a) for a in bb]) + '\n')in_file.close()out_file.close()wd = os.getcwd()
wd = os.getcwd()
data_base_dir = os.path.join(wd, "F:/Yolov5/yolov5_offical/yolov5-master/VOCdevkit/")
if not os.path.isdir(data_base_dir):os.mkdir(data_base_dir)
work_sapce_dir = os.path.join(data_base_dir, "VOC2007/")
if not os.path.isdir(work_sapce_dir):os.mkdir(work_sapce_dir)
annotation_dir = os.path.join(work_sapce_dir, "Annotations/")
if not os.path.isdir(annotation_dir):os.mkdir(annotation_dir)
clear_hidden_files(annotation_dir)
image_dir = os.path.join(work_sapce_dir, "JPEGImages/")
if not os.path.isdir(image_dir):os.mkdir(image_dir)
clear_hidden_files(image_dir)
yolo_labels_dir = os.path.join(work_sapce_dir, "YOLOLabels/")
if not os.path.isdir(yolo_labels_dir):os.mkdir(yolo_labels_dir)
clear_hidden_files(yolo_labels_dir)
yolov5_images_dir = os.path.join(data_base_dir, "images/")
if not os.path.isdir(yolov5_images_dir):os.mkdir(yolov5_images_dir)
clear_hidden_files(yolov5_images_dir)
yolov5_labels_dir = os.path.join(data_base_dir, "labels/")
if not os.path.isdir(yolov5_labels_dir):os.mkdir(yolov5_labels_dir)
clear_hidden_files(yolov5_labels_dir)
yolov5_images_train_dir = os.path.join(yolov5_images_dir, "train/")
if not os.path.isdir(yolov5_images_train_dir):os.mkdir(yolov5_images_train_dir)
clear_hidden_files(yolov5_images_train_dir)
yolov5_images_test_dir = os.path.join(yolov5_images_dir, "val/")
if not os.path.isdir(yolov5_images_test_dir):os.mkdir(yolov5_images_test_dir)
clear_hidden_files(yolov5_images_test_dir)
yolov5_labels_train_dir = os.path.join(yolov5_labels_dir, "train/")
if not os.path.isdir(yolov5_labels_train_dir):os.mkdir(yolov5_labels_train_dir)
clear_hidden_files(yolov5_labels_train_dir)
yolov5_labels_test_dir = os.path.join(yolov5_labels_dir, "val/")
if not os.path.isdir(yolov5_labels_test_dir):os.mkdir(yolov5_labels_test_dir)
clear_hidden_files(yolov5_labels_test_dir)train_file = open(os.path.join(wd, "yolov5_train.txt"), 'w')
test_file = open(os.path.join(wd, "yolov5_val.txt"), 'w')
train_file.close()
test_file.close()
train_file = open(os.path.join(wd, "yolov5_train.txt"), 'a')
test_file = open(os.path.join(wd, "yolov5_val.txt"), 'a')
list_imgs = os.listdir(image_dir) # list image files
prob = random.randint(1, 100)
print("Probability: %d" % prob)
for i in range(0, len(list_imgs)):path = os.path.join(image_dir, list_imgs[i])if os.path.isfile(path):image_path = image_dir + list_imgs[i]voc_path = list_imgs[i](nameWithoutExtention, extention) = os.path.splitext(os.path.basename(image_path))(voc_nameWithoutExtention, voc_extention) = os.path.splitext(os.path.basename(voc_path))annotation_name = nameWithoutExtention + '.xml'annotation_path = os.path.join(annotation_dir, annotation_name)label_name = nameWithoutExtention + '.txt'label_path = os.path.join(yolo_labels_dir, label_name)prob = random.randint(1, 100)print("Probability: %d" % prob)if (prob < TRAIN_RATIO): # train datasetif os.path.exists(annotation_path):train_file.write(image_path + '\n')convert_annotation(nameWithoutExtention) # convert labelcopyfile(image_path, yolov5_images_train_dir + voc_path)copyfile(label_path, yolov5_labels_train_dir + label_name)else: # test datasetif os.path.exists(annotation_path):test_file.write(image_path + '\n')convert_annotation(nameWithoutExtention) # convert labelcopyfile(image_path, yolov5_images_test_dir + voc_path)copyfile(label_path, yolov5_labels_test_dir + label_name)
train_file.close()
test_file.close()
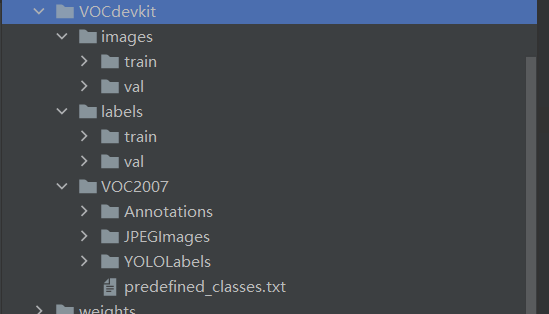
代码执行完成后目录结构如下:
下载预训练权重:
打开这个网址下载预训练权重,这里选择yolov5s.pt。
训练模型
修改数据配置文件:
找到data目录下的voc.yaml文件,将该文件复制一份,重命名为people.yaml:
打开people.yaml,修改相关参数(train,val,nc):

修改模型配置文件:
找到models目录下的yolov5s.yaml文件,将该文件复制一份,重命名为yolov5s_people.yaml:
打开yolov5_people.yaml,修改相关参数(nc):

训练模型:
打开train.py,修改如下参数:
weights:权重的路径
cfg:yolov5s_people.yaml路径
data:people.yaml路径
epochs:训练的轮数
batch-size:每次输入图片数量(根据自己电脑情况修改)
workers:最大工作核心数(根据自己电脑情况修改)




运行train.py函数训练自己的模型。
tensorbord查看参数
打开pycharm的命令控制终端,运行如下命令:
tensorboard --logdir=runs/train
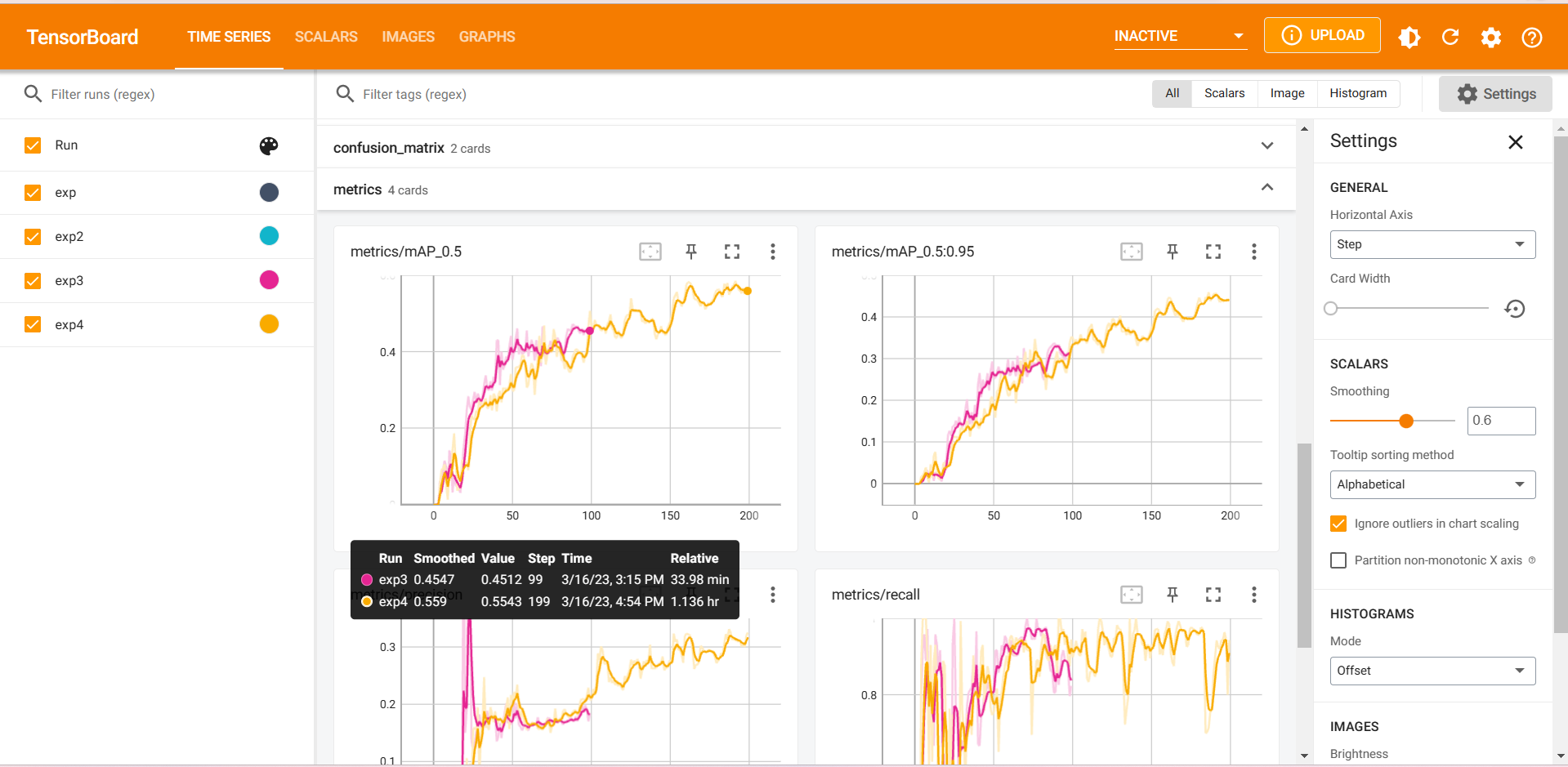
推理测试
模型训练完成后,会在主目录下产生一个名为runs的文件夹,在runs/train/exp/weights目录下会产生两个权重文件,一个是最后一轮的权重文件,一个是最好的权重文件。
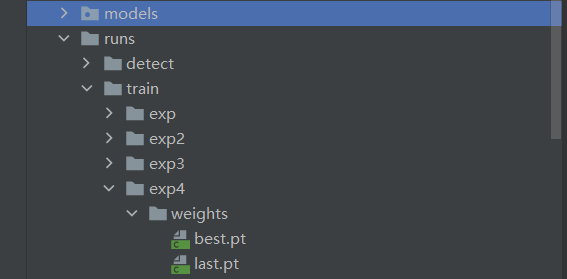
打开detect.py文件,修改相关参数:
weights:权重路径(这里选择best.pt)
source:测试数据路径,可以是图片/视频,也可以是’0’(电脑自带摄像头)

执行detect.py进行测试,测试结果会保存在runs/detect/exp目录下。
源码地址:https://github.com/Sakura-jie/yolov5-master.git
(注:由于模型训练轮数以及数据集较少等原因,本项目中模型准确率较低,建议增加训练轮数以及数据集大小以获得更高准确率)









 "Yolov5——训练目标检测模型详解(含完整源码)")


