
一.概念
索引下推(Index Pushdown)MySQL5.6添加的,是一种优化技术,用于在查询执行时将部分计算移动到存储引擎层,从而减少数据传输和计算的开销(减少回表查询次数),提高查询性能。
在传统的查询执行过程中,数据库会首先从磁盘读取数据页,然后将数据加载到内存中进行过滤和计算,最后返回结果。而索引下推技术可以利用存储引擎的索引结构,将查询条件移动到存储引擎层进行计算,从而减少了磁盘和内存之间的数据传输,提高了查询效率。
例如,假设有一个包含10万条记录的表,需要查询出年龄大于30岁的用户信息。如果没有使用索引下推,数据库需要将全部10万条记录加载到内存中,再进行过滤和计算。而如果使用索引下推,数据库可以先利用索引结构找到年龄大于30岁的记录,然后只加载符合条件的数据页,从而减少了数据传输和计算的开销。
索引下推技术可以在很多场景下提高查询性能,特别是在大数据量和复杂查询条件的情况下。但是需要注意的是,索引下推并不适用于所有类型的查询,需要根据具体情况进行优化和测试。
二.索引优化的原理
MySQL的大体框架
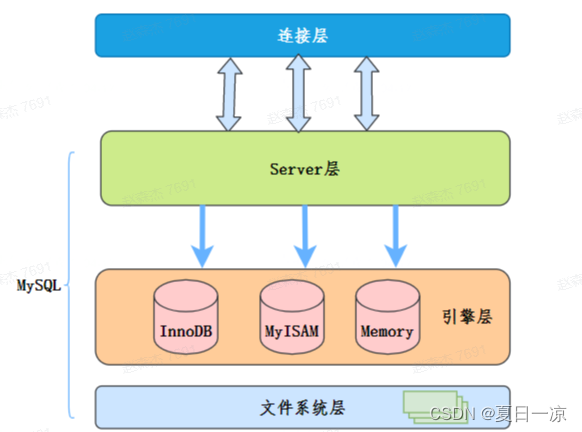
MySQL服务层负责SQL语法解析、生成执行计划等,并调用存储引擎层去执行数据的存储和检索。
索引下推的下推其实就是指将部分上层(服务层)负责的事情,交给了下层(引擎层)去处理。
流程:
1. 没有使用ICP的情况下,MySQL的查询:
- 存储引擎读取索引记录;
- 根据索引中的主键值,定位并读取完整的行记录;
- 存储引擎把记录交给Server层去检测该记录是否满足WHERE条件。
2. 使用ICP的情况下,查询过程: - 存储引擎读取索引记录(不是完整的行记录);
- 判断WHERE条件部分能否用索引中的列来做检查,条件不满足,则处理下一行索引记录;
- 条件满足,使用索引中的主键去定位并读取完整的行记录(就是所谓的回表);
- 存储引擎把记录交给Server层,Server层检测该记录是否满足WHERE条件的其余部分。
三.实例理解
创建联合索引(name, age)
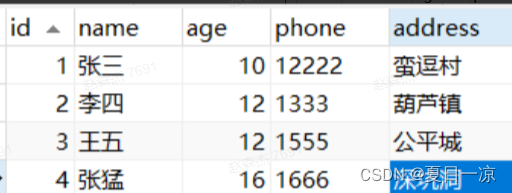
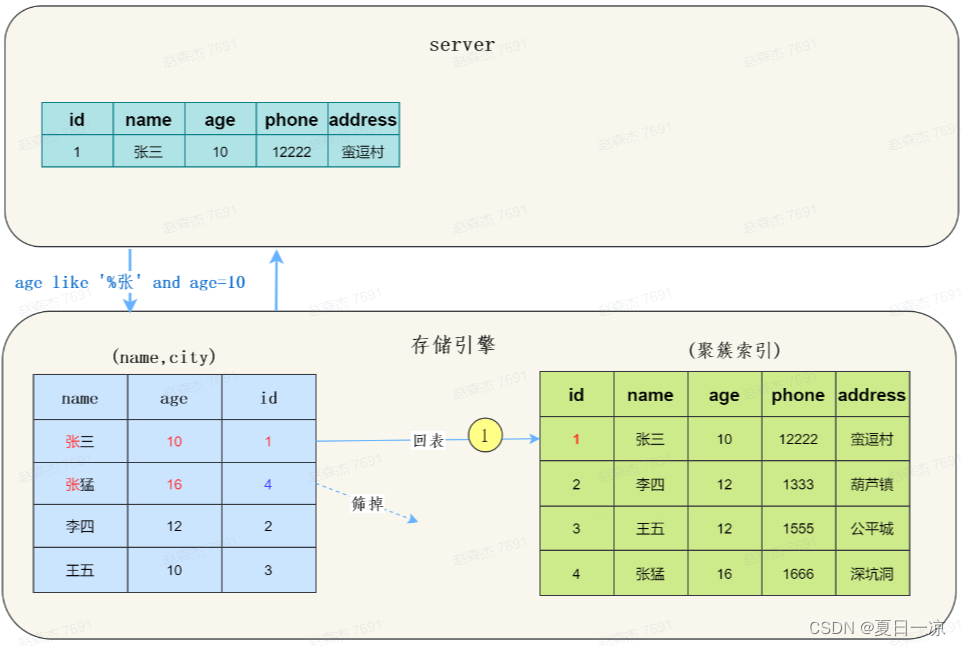
如果现在有一个需求:检索出表中名字第一个字是“张”,而且年龄是10岁的所有用户
select * from tuser where name like '张%' and age=10;
索引最左前缀原则
索引的最左前缀原则是指,如果一个复合索引包含多个列,那么在查询时只有使用到了该索引的最左边的前缀列,才能够利用该索引进行查询。
例如,如果有一个复合索引包含三个列(A,B,C),那么只有在查询条件中使用到了该索引的最左边的前缀列A时,才能够利用该索引进行查询。如果查询条件只使用了B或C列,那么该索引就不能被利用。
这是因为,复合索引的存储结构是按照索引列的顺序进行排序的。如果查询条件只涉及到索引的前缀列,那么数据库可以利用索引的顺序进行查找,从而提高查询效率。但如果查询条件涉及到了索引的后续列,那么就需要扫描整个索引才能找到符合条件的记录,这会导致查询效率下降。
因此,在设计索引时,需要根据实际情况来选择索引列的顺序,以便最大程度地利用索引的最左前缀原则。同时,也需要注意避免创建过多的索引,因为索引的创建和维护也会带来一定的开销。
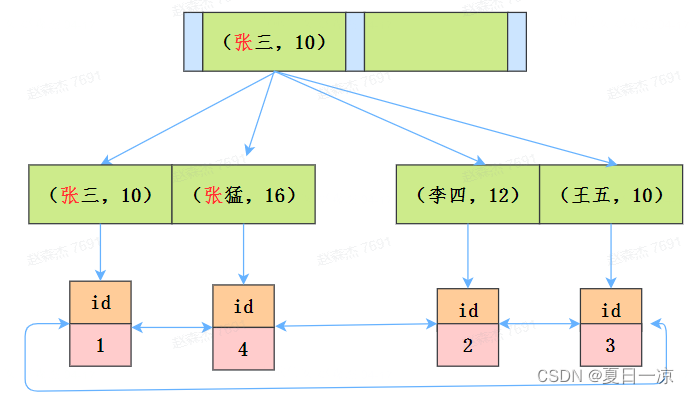
通过最左前缀原则,只能通过“张”找到的第一个满足条件的记录id为1
没有ICP的情况下
在MySQL 5.6之前,存储引擎根据通过联合索引找到name like ‘张%’ 的主键id(1、4),逐一进行回表扫描,去聚簇索引找到完整的行记录,server层再对数据根据age=10进行筛选。
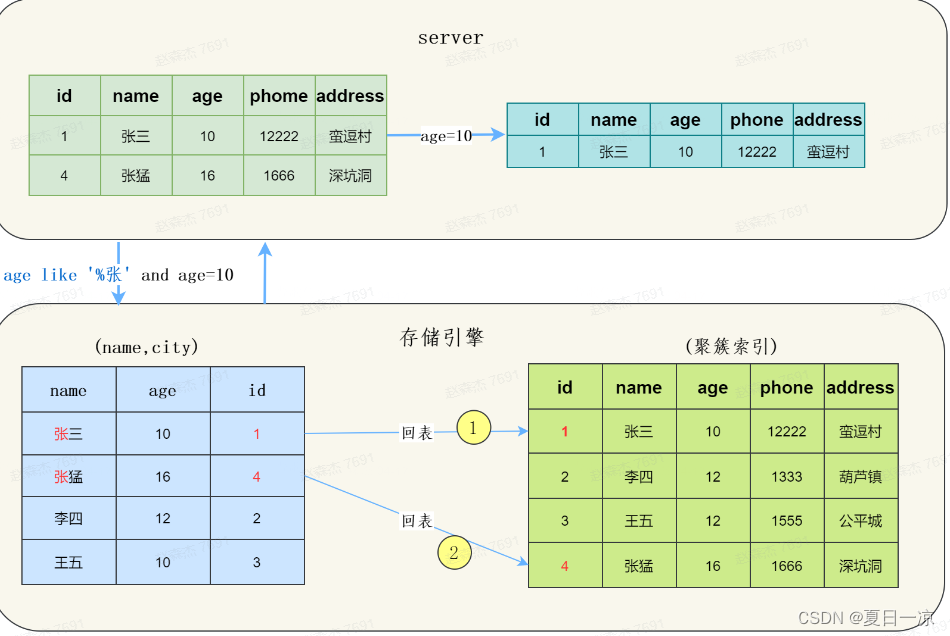
使用ICP
而MySQL 5.6 以后, 存储引擎根据(name,age)联合索引,找到name like ‘张%’,由于联合索引中包含age列,所以存储引擎直接再联合索引里按照age=10过滤。按照过滤后的数据再一一进行回表扫描。









 "Jenkins配置(插件/角色/凭证)")


