
LLMs基础学习(七)DeepSeek专题(1)
文章目录
- LLMs基础学习(七)DeepSeek专题(1)
- DeepSeek 相关资料
- 官方资料与基础文档
- 实践指南和技术解析
- 热启动与冷启动
- **热启动(主流)**
- **为什么更常用?**
- **典型场景**:
- **冷启动(少数场景)**
- **何时会用到?**
- **缺点**:
- **对比总结**
- 行业趋势
- DeepSeek 相关模型训练流程总结
- DeepSeek - R1 和 DeepSeek - R1 - Zero 的区别
- DeepSeek - R1 - Zero 通过纯强化学习(RL)实现推理能力的突破
- 训练 DeepSeek - R1 中引入数千条样本进行冷启动
- 关于 AIME(美国数学邀请赛)的相关信息
- CoT 思维链
- 冷启动数据相关内容解读
- DeepSeek 技术发展时间表
图片和视频链接:https://www.bilibili.com/video/BV1gR9gYsEHY?spm_id_from=333.788.player.switch&vd_source=57e4865932ea6c6918a09b65d319a99a
DeepSeek-R1 满血版 深度推理思考,适合复杂问题
DeepSeek-V3 最新版 全新升级代码和创作能力
DeepSeek 相关资料
- 补充信息提到 ChatGPT 需上万张 NVIDIA A100 显卡,国内主要玩家有百度、字节、腾讯、阿里、商汤、幻方。
| 时间 | 事件 |
|---|---|
| 2019 年 | 布局集卡 |
| 2020 年 | 投入 10 亿手握万卡 |
| 2022 年 3 月 | GPT 3.5 发布 |
| 2024 年 5 月 | V2 发布、GPT 4.0 发布 |
| 2024 年 7 月 | Llama - 3.1 发布 |
| 2024 年底 | V3 发布 |
| 2025 年 1 月 31 号 | R1 登录 nvidia 官网 |
官方资料与基础文档
- DeepSeek 官方渠道 【★★★】
- 官网与模型仓库:可访问 DeepSeek 官方网站获取最新产品信息,通过 Hugging Face 仓库下载模型权重和配置。
- 开源代码与论文
- GitHub 开源代码库:DeepSeek 官方代码、DeepSeek - R1 官方代码;
- 技术论文:《DeepSeek - R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning》 。
- 官方提示词库【★★★★★】:提供多种场景的提示词示例,用于优化模型交互效果,即 DeepSeek 提示词库。
实践指南和技术解析
- 清华大学关于 DeepSeek 资料完整版【★★★★★】:由清华大学新闻与传播学院新媒体研究中心元宇宙文化实验室出品,对 DeepSeek 进行全面介绍,包括基础信息、应用场景和使用方法等,帮助学习者快速了解 DeepSeek - R1 并掌握应用技巧。
- 北京大学关于 DeepSeek 资料完整版【★★★】 (此处仅列出标题,无具体内容)
- 偏应用内容:【飞行社】Deepseek 学习手册 (持续更新 ing…) (仅标题,无更多介绍)
- 偏技术内容
- 张俊林关于 DeepSeek 一系列分享:链接为https://zhuanlan.zhihu.com/p/19969128139
- 清华刘知远教授解读 DeepSeek:链接为https://mp.weixin.qq.com/s/JuaXH1RAm9mHaxRIUTRC6mg
热启动与冷启动
热启动(主流)
为什么更常用?
- 预训练模型(Pretrained Models)的普及:
- 大多数深度学习任务(尤其是NLP、CV)基于预训练模型(如BERT、ResNet、GPT),直接加载已有参数进行微调(Fine-tuning),属于典型的热启动。
- 优势:节省计算资源、避免从头训练、利用大规模数据学到的通用特征。
- 迁移学习(Transfer Learning)的成熟:
- 热启动本质是迁移学习的核心思想(复用已有知识),而冷启动需要从随机初始化开始,效果和效率通常更差。
- 实际场景需求:
- 工业界任务通常要求快速迭代,冷启动的训练成本(时间/算力)难以承受。
典型场景:
- 微调BERT完成文本分类。
- 用预训练的ResNet做医学图像分割。
冷启动(少数场景)
何时会用到?
- 研究新领域/新架构:
- 当模型结构或任务与现有预训练模型无关时(如全新神经网络设计),必须冷启动。
- 例子:训练一个全新的Transformer变体(无预训练参数可用)。
- 数据分布差异极大:
- 如果目标数据与预训练数据分布完全不同(如非自然图像、小众语言),冷启动可能更优。
- 避免预训练偏差:
- 某些场景需完全从数据中学习,避免预训练模型的潜在偏差(如伦理敏感任务)。
缺点:
- 需要大量数据和算力。
- 训练不稳定(梯度爆炸/消失风险更高)。
对比总结
| 维度 | 热启动 | 冷启动 |
|---|---|---|
| 使用频率 | 主流(90%+场景) | 少数(研究/特殊需求) |
| 依赖条件 | 需相关预训练模型 | 无需预训练,随机初始化 |
| 数据需求 | 少量标注数据即可微调 | 需大量数据从头训练 |
| 计算成本 | 低(GPU小时级) | 高(GPU天/周级) |
| 典型工具 | Hugging Face、TorchVision | 自定义架构 |
行业趋势
- 热启动的统治地位:随着大模型(LLMs)和多模态基座模型(如GPT-4、Stable Diffusion)的普及,热启动已成为绝对主流。
- 冷启动的 niche 场景:仅在学术研究或垂直领域(如量子化学、新型硬件适配)中可能出现。
建议:
- 优先尝试热启动(除非任务极度特殊),利用开源预训练模型加速开发。
- 冷启动更适合探索性研究,但需准备好算力和数据支持。
如果需要具体任务(如CV/NLP)的冷热启动选择案例,可以进一步讨论!
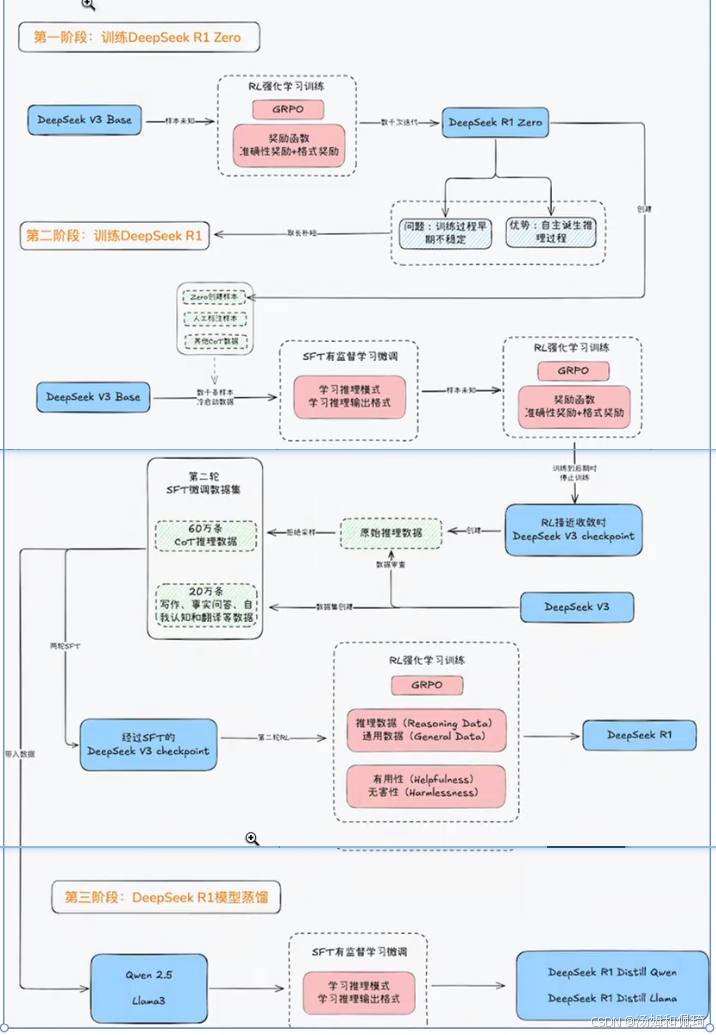
DeepSeek 相关模型训练流程总结
- 第一阶段:训练 DeepSeek R1 Zero
- 方法:引入 DeepSeek V3 Base ,采用强化学习(RL)进行训练。使用 GRPO(群体相对策略优化)调整奖励函数 ,探索不同的序列化行为模式。
- 结果:训练出 DeepSeek R1 Zero 。问题在于训练过程早期不稳定;优势是模型能自主诞生推理过程。比如在数学推理任务中,模型开始尝试自己寻找解题步骤,而非简单依赖预设规则,但在训练初期,可能会出现推理过程混乱、结果反复波动的情况 。若用图表展示,可绘制一个折线图,横轴为训练轮次,纵轴为模型在数学推理任务上的准确率,能看到早期准确率波动较大。
- 第二阶段:训练 DeepSeek R1
- 方法:再次启用 DeepSeek V3 Base ,并进行进一步微调。通过两轮 SFT(有监督微调)调整学习模式,利用两轮 GRPO 进行强化学习,依据奖励函数进一步优化。
- 结果:得到 DeepSeek R1 ,相较于 R1 Zero ,在推理稳定性和多任务处理能力上有显著提升。例如在语言理解和生成任务中,R1 能够更准确、连贯地生成文本 。可以用柱状图对比 R1 Zero 和 R1 在语言生成任务上的得分,直观体现 R1 的提升。
- 第三阶段:DeepSeek R1 模型蒸馏
- 方法:运用蒸馏技术,从大模型中提取知识。
- 结果:产出蒸馏后的小尺寸模型,便于在资源受限的设备上部署,同时尽可能保留大模型的关键能力。 可以绘制一个资源占用(如内存、计算量等)对比的雷达图,展示蒸馏前后模型在不同资源维度上的变化。
DeepSeek - R1 和 DeepSeek - R1 - Zero 的区别
训练方式差异
| 模型 | 起始微调 | 强化学习轮次 | 微调特点 | 数据处理 |
|---|---|---|---|---|
| DeepSeek - R1 | 冷启动数据微调 | 两轮 | 增强型监督微调 | 人工标注、格式过滤 |
| DeepSeek - R1 - Zero | 无 | - | - | 两种奖励设定 |
主要功能差异
| 模型 | 推理成绩(AIME2024 等) | 适用场景 | 自我进化 | 开源许可 |
|---|---|---|---|---|
| DeepSeek - R1 | 79.8% 等,多任务优 | 高精度推理 | - | MIT 许可,支持蒸馏 |
| DeepSeek - R1 - Zero | 从 15.6% 升至 71.0% | 研究场景 | 训练中涌现反思 | MIT 许可,支持蒸馏 |
DeepSeek - R1 - Zero 通过纯强化学习(RL)实现推理能力的突破
- 纯强化学习训练范式:传统大语言模型(LLM)训练通常先依靠监督微调(SFT)获得基础能力,再通过 RL 优化性能。而 DeepSeek - R1 - Zero 完全跳过 SFT 阶段,仅依靠 RL 进行训练。这一实验表明,仅通过 RL 就能直接激励模型在数学、编程等任务中发展出强大的推理能力,例如生成思维链(Chain - of - Thought, CoT)并自我验证。可以绘制一个流程图,展示传统训练范式和 R1 - Zero 训练范式的不同步骤。
- 创新的强化学习算法与奖励机制
- GRPO 算法:采用群体相对策略优化(Group Relative Policy Optimization, GRPO) ,通过比较一组输出的奖励来估计优势函数,避免了传统方法中需要单独训练评论模型(Critic)的复杂性,显著降低了计算资源需求。GRPO 算法每组采样 16 条输出,强制模型探索多路径,增加了模型探索不同策略的可能性。可以用示意图展示 GRPO 算法的采样过程和优势函数计算方式。
- 双奖励系统:设计了基于规则的奖励机制,包括准确性奖励(评估答案正确性,如数学题答案验证或代码编译测试 )和格式奖励(强制模型将推理过程置于特定标签,如 和 < /think > 之间,提升可读性 ) 。可以绘制一个简单的表格,对比两种奖励机制的触发条件和作用。
- 自我进化与 “顿悟时刻”:在 RL 训练过程中,DeepSeek - R1 - Zero 展现出自主进化的能力。例如在解决数学问题时,模型会主动延长推理时间、重新评估错误步骤,并探索新的解题策略,体现出类似人类 “顿悟” 的学习过程。可以用时间轴图表展示模型在训练过程中自我进化行为的出现节点和表现。
- 对传统训练范式的颠覆:DeepSeek - R1 - Zero 的成功挑战了 “监督数据依赖” 的固有模式,证明在无需人工标注的 SFT 数据的情况下,模型也能通过 RL 自主探索并优化推理路径。
训练 DeepSeek - R1 中引入数千条样本进行冷启动
- 原因:DeepSeek - R1 - Zero 存在可读性和语言混合问题,引入冷启动数据旨在解决这些问题。冷启动数据为 RL 训练提供高质量的初始策略,避免早期探索阶段的输出混乱;通过模板化输出(如 summary 模块)提升生成内容的用户友好性;减少 RL 训练所需的步数,加速收敛过程,例如实验表明冷启动后 AIME Pass@1 进一步提升至 79.8% 。 可以绘制一个对比图,展示冷启动前后模型在 AIME 任务上的 Pass@1 分数变化。
- 内容:冷启动数据包含数千条高质量的长思链(CoT)示例 。这些示例经过人工标注和格式过滤,使用和等标签 ,强制模型生成结构清晰、语言一致的内容。 可以展示一个示例数据的截图或示意图,体现标注和格式过滤的效果。
关于 AIME(美国数学邀请赛)的相关信息
-
定位与晋级:AIME(American Invitational Mathematics Examination)是美国数学竞赛体系中的重要组成部分,由美国数学协会(MAA)主办。通常在 AMC 10/12 之后举行,在 AMC 10 中排名前 2.5% 或 AMC 12 中前 5% 的学生可晋级 AIME。可以绘制一个美国数学竞赛体系的关系图,展示 AMC 和 AIME 的关联。
-
考试结构
- 题型:15 道填空题。
- 计分:每题 1 分,满分 15 分,不扣分。
- 时间:考试时长 3 小时,平均每题 12 分钟,注重深度思考。可以用一个简单的信息图表展示考试结构的关键信息。
-
选择 AIME 2024 作为核心评测任务的原因
- 高区分度:题目需多步推理且答案唯一,能够很好地衡量量化模型的逻辑推理能力。
- 跨语言可比性:数学符号体系通用,减少了语言偏差对评测结果的影响。
- 社区认可度:在评估 GPT - 4、Claude 等模型的推理能力上限方面被广泛应用,具有较高的权威性。可以用一个雷达图对比 AIME 与其他评测任务在不同评估维度上的表现。
-
评测指标含义
- Pass@1:单次生成答案的正确率,反映模型确定性推理能力,适用于轻量级场景(如实时交互) 。
- Cons@64:64 次生成中最高频答案的正确率,用于衡量输出稳定性,适用于高精度需求场景(如学术研究) 。可以绘制一个对比图,展示不同模型在 Pass@1 和 Cons@64 指标上的表现差异。
-
模型评测结果
模型 AIME 2024 pass@1 AIME 2024 cons@64 MATH - 500 pass@1 GPQA Diamond pass@1 LiveCodeBench pass@1 QwQ - 32B - Preview 50.0 60.0 90.6 54.5 41.9 DeepSeek - R1 - Zero - Qwen - 32B 47.0 60.0 91.6 55.0 40.2 DeepSeek - R1 - Distill - Qwen - 32B 72.6 83.3 94.3 62.1 57.2
CoT 思维链
在深度学习中,CoT 通常指 “Chain of Thought”,即思维链。CoT(思维链)就是把复杂问题拆成一连串中间步骤来解决,就像人思考问题时一步步推理一样。它能让模型回答问题更有条理,提高解决复杂问题的能力,还能让人明白模型是怎么得出答案的,增强对模型的理解和信任。
冷启动数据相关内容解读
这部分内容围绕冷启动数据展开,主要包含构造方法、人工标注及格式过滤的必要性、“总结” 模块提升可读性的原理三方面:
- 冷启动数据构造
- 种子问题收集:从数学竞赛(如 AIME ,美国数学邀请赛,在数学领域具有较高权威性和影响力,其题目对逻辑推理和数学思维要求高 )、编程题库(LeetCode ,知名编程练习和技术面试准备平台,题目类型丰富 )中挑选有代表性的题目。这些题目能为模型训练提供多样且具挑战性的任务,帮助模型学习不同领域解题思路和逻辑。
- 答案生成:借助 DeepSeek - R1 - Zero 生成初始 CoT(Chain of Thought,思维链 ),再人工修正逻辑错误并统一格式。因模型初始生成的 CoT 可能存在逻辑漏洞或表述不规范,人工干预确保数据准确性和规范性,为后续训练奠定良好基础。
- 模板化:强制使用和标签,并添加总结模块(如关键步骤:… )。通过模板化规范数据结构,使模型输出格式清晰,便于学习和遵循固定推理与表达模式。
- 人工标注和格式过滤原因
- 可读性保障:自动生成的 CoT 可能含无关内容或语言混杂,人工过滤去除干扰信息,让推理过程更清晰简洁,使模型学习优质、易懂的推理表达。
- 格式一致性:确保后续 RL(强化学习)训练中奖励信号稳定。若数据格式不统一,模型接收奖励反馈时易混乱,影响学习效果。格式过滤使模型输出符合规范,准确计算奖励,引导模型正确学习。
- “总结” 模块提升可读性方式
- 信息压缩:要求模型用 1 - 2 句话概括最终结论,如解为 x = 2,关键步骤:平方消去根号 。提炼推理关键信息,避免冗长表述,使核心内容一目了然,便于快速理解。
- 用户友好:用户可直接读总结,无需解析长 CoT,降低获取关键信息门槛,提升交互体验,在对信息获取效率要求高的场景优势明显。
- 奖励引导:总结清晰度通过规则化评分(如关键词覆盖率 )纳入奖励函数。激励模型注重总结模块生成质量,不断优化总结,使其更准确清晰呈现关键信息。人工评测显示带总结输出可读性评分提升 41%,有力证明其作用。
DeepSeek 技术发展时间表
这是 DeepSeek 系列模型技术创新的时间线表格,涵盖发布时间、技术创新、模型链接、paper 链接、核心点等信息:
- 2024 年 1 月 - DeepSeek MoE 架构
- 技术创新:采用 MoE(Mixture of Experts,混合专家架构 )。将模型部分层划分为多个专家网络,由门控网络依输入数据动态分配专家网络权重,提高模型处理复杂任务能力和表达能力,使模型能根据输入选择合适专家处理数据,增强灵活性和适应性。
- 模型链接:DeepSeek - MOE
- paper 链接:https://arxiv.org/pdf/2401.06066
- 核心点:图示展示架构示意图,呈现专家网络和门控网络协作方式,体现根据输入动态选择组合专家网络处理数据的过程。
- 2024 年 4 月 - Group Relative Policy Optimization(GRPO,群体相对策略优化)
- 技术创新:GRPO 算法用于优化模型策略。通过比较一组输出奖励估计优势函数,避免传统方法单独训练评论模型的复杂性,降低计算资源需求,提升训练效率和稳定性。
- 模型链接:DeepSeek - Math
- paper 链接:https://arxiv.org/pdf/2402.03300
- 核心点:图示说明算法原理和流程,展示在模型训练中如何通过比较奖励优化策略。
- 2024 年 6 月 - Multi - Head Latent Attention(MLA,多头隐式注意力)
- 技术创新:MLA(多头隐式注意力 )机制改进注意力计算方式,更有效捕捉输入数据长距离依赖关系,提升模型对上下文信息理解和处理能力,在处理长文本等任务时能更好把握全局语义。
- 模型链接:DeepSeek - V2
- paper 链接:https://arxiv.org/pdf/2405.04434
- 核心点:图示展示结构和工作原理,如不同头注意力计算及信息综合处理过程。
- 2024 年 12 月 - Multi - Token Prediction(MTP,多令牌预测)
- 技术创新:MTP(多令牌预测 )技术使模型一次可预测多个令牌,提高生成效率,加快文本生成等任务输出速度,且可能改善生成文本连贯性和逻辑性。
- 模型链接:DeepSeek - V3
- paper 链接:https://arxiv.org/pdf/2412.19437
- 核心点:图示呈现预测过程和机制,展示模型实现多令牌预测及对生成过程的影响。
- 2025 年 1 月 - DeepSeek - R1 - Zero
- 技术创新:通过强化学习显著提升模型推理能力,R1 - Zero 在 AIME 2024 等推理基准测试中达 OpenAI - o1 - 0912 水平 。该模型完全基于强化学习训练,跳过监督微调阶段,探索独特推理能力提升路径。
- 模型链接:DeepSeek - R1 - Zero
- paper 链接:https://arxiv.org/pdf/2501.12948
- 核心点:展示模型训练和推理过程图示,体现强化学习应用方式及推理能力提升机制。
- 2025 年 1 月 - DeepSeek - R1
- 技术创新:采用冷启动 - 强化学习(推理场景) - SFT(有监督微调) - 强化学习(全场景)四阶段训练,R1 模型达 OpenAI - o1 - 1217 水平 。多阶段训练结合不同方法优势,全面提升模型性能。
- 模型链接:DeepSeek - R1
- paper 链接:https://arxiv.org/pdf/2501.12948
- 核心点:图示呈现四阶段训练流程和各阶段作用,展示模型逐步优化提升过程。
- 2025 年 - DeepSeek - R1 - Distill(以 distill - qwen - 32b 为例)
- 技术创新:将 R1 推理能力蒸馏到小的稠密模型,通过模型蒸馏技术,在保持推理能力前提下减小模型规模,便于在资源受限设备上部署应用,降低模型部署硬件要求。
- 模型链接:DeepSeek - R1 - Distill(以 distill - qwen - 32b 为例)
- paper 链接:https://arxiv.org/pdf/2501.12948
- 核心点:图示说明模型蒸馏过程,包括从 R1 模型提取知识迁移到小模型的方式,以及蒸馏后小模型性能优势。
| 发布时间 | 技术创新 | 模型链接 | paper 链接 | 核心点 |
|---|---|---|---|---|
| 2024 年 1 月 | DeepSeek MoE 架构 | DeepSeek - MOE | https://arxiv.org/pdf/2401.06066 | 多专家网络协作,动态处理数据 |
| 2024 年 4 月 | GRPO | DeepSeek - Math | https://arxiv.org/pdf/2402.03300 | 优化模型策略,降计算资源需求 |
| 2024 年 6 月 | MLA | DeepSeek - V2 | https://arxiv.org/pdf/2405.04434 | 改进注意力,捕捉长距依赖 |
| 2024 年 12 月 | MTP | DeepSeek - V3 | https://arxiv.org/pdf/2412.19437 | 多令牌预测,提生成效率 |
| 2025 年 1 月 | 强化学习提升推理(R1 - Zero) | DeepSeek - R1 - Zero | https://arxiv.org/pdf/2501.12948 | 强化学习,提推理能力 |
| 2025 年 1 月 | 四阶段训练(R1) | DeepSeek - R1 | https://arxiv.org/pdf/2501.12948 | 多阶段训练,全面提升性能 |
| 2025 年 1 月 | 模型蒸馏(R1 - Distill) | DeepSeek - R1 - Distill | https://arxiv.org/pdf/2501.12948 | 知识迁移,缩小模型规模 |
接下来会对涉及到的技术项进行一一学习。












