
首先需要说明的是,Spring只是解决了单例模式下属性依赖的循环问题,接下来的讨论也是针对单例Bean进行分析的。
【前置知识】
- Bean的生命周期
- AOP的创建代理对象机制
【解决方案】:依赖三级缓存机制
- 第零级:(辅助)创建中对象---->creatingObjects
- 第一级:单例对象池---> singletonObjects(源码)
- 存放的是成熟的Bean对象
- 第二级:临时代理对象池--->earlysingletonObjects(源码)
- 存放的是不完整的半成品对象
- 第三级:原始对象池--->singletonFactories(源码)
第零级:用来存储正在创建过程中的对象
第一级的单例对象池存储的是当前bean是否已经创建好并放入单例池中,如果已经有了,就可以直接从第一层中取出来使用即可。
第二级临时代理对象池是由于在创建Bean生命周期中,如果需要自动注入其他对象,则需要获取其代理对象,第二层临时代理对象池如果也没有找到,则可以断定发生了循环依赖。
第三级原始对象池,由于AOP创建代理对象需要用到原始对象及其信息,因此需要从第三级缓存池中获取相关信息。
一、从Bean生命周期开始分析
有三个Service对象,分别是AService、BService、CService;其中AService中有BService、CService两个属性;BService中有AService属性;CService中有AService属性。这样AService分别和BService、CService都形成了循环依赖。
【分析AService的生命周期流程】
- creatingObjects['aService'] 开始创建AService对象,并将状态标记为创建中
- 实例化 new AService() ----> 创建原始对象 ---> 加入原始对象池
- 填充bService属性
- 先去单例池中寻找
- 没找到,尝试创建BService对应Bean,并将状态标记 creatingObjects['bService']
- 这一步过后,会串行跳转到BService的生命周期中
- 填充cService属性
- 先去单例池中寻找
- 没找到,尝试创建CService对应Bean,并将状态标记 creatingObjects['cService']
- 这一步过后,会串行跳转到CService的生命周期中
- 填充其他属性
- 正常进行AOP创建代理对象的地方
- 判断先前有没有进行AOP
- 没有,由AOP插件进行AOP代理对象的创建(二三级缓存)
- 放入单例池
- 将完整的代理对象从临时代理对象池放入单例池
- 删除临时代理对象池中的对象
【分析BService的生命周期流程】
这块BService的创建是由AService填充属性时调起的
- 实例化 new BService() ---> 创建原始对象 ---> 加入原始对象池
- 填充aService属性
- 查找单例池。此时AService创建的生命周期流程还没走完,必然找不到的!!
- 没找到,查询临时代理对象池。由于AService创建是主动先手的,所以还没到正常AOP的执行步骤,因此此时也是没有临时代理对象的。
- 没找到,判断发生了循环依赖
- 提前进行AOP创建aService的代理对象,此时需要从原始对象池(三级缓存)中获取aService的相关信息
- 将aService临时代理对象存入临时代理对象池(二级缓存)
- 填充其他属性
- 正常进行AOP的地方以及其它初始化工作
- 放入单例池(从临时代理对象中拿出来,如果该对象不需要创建代理对象,则将原始对象放入,这一步AOP创建方法帮我们完成的)
其实有些地方描述的并不是太准确,只能大概传达Spring的意思。实际上Bean之间的创建流程是一致的,例如AService也会去判断循环依赖、创建代理对象之类的。只是为了体现整个流程,进行了一些调整。
二、问题分析:三级缓存的必要性
通过以上Bean创建流程的分析,衍生出几个问题,这为我们揭示了Spring为什么要采用三级缓存机制的原因。
第一级缓存:单例池的存在意义
问题一:对于单例bean的创建,Spring是怎么做的?
我们知道,Spring创建的Bean默认是单例的,所以在Bean创建的过程中,为了确保拿到的Bean对象始终如一,会将bean代理对象存入到单例池中。所以我们在填充其他Bean属性的时候,通常会先去查询单例池,即第一级缓存。
第二级缓存:临时代理对象池的存在意义
问题一:你为什么要叫它为临时代理对象池?
是这样的,对于一个正常没有循环依赖的Bean的创建流程来说,代理对象通常都是在填充属性之后才调用创建的。也就是我们前面分析的正常进行AOP的步骤。这个AOP创建出来的代理对象是完整的。
而相对的,在判断出现循环依赖后,Spring将AOP代理对象的创建提前了,这个时候的代理对象是不完整的,需要后续进行补充,所以我称它为临时代理对象。
问题二:为什么要有临时代理对象池?
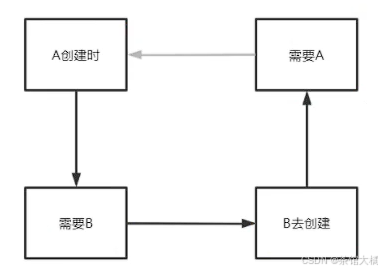
如果没有这个对象池会是怎样的呢?在只存在一级缓存,即单例池的情况下,当单例池中没有找到所需要的对象时,就会尝试创建该对象对应的Bean,从而又跳转到该对象的创建生命周期中,于是乎这个循环依赖的结就产生了。循环依赖闭环描述如下:
AService需要注入BService属性------>首先在单例池找不到------>尝试创建BService对象
------>进入到BService生命周期------>BService需要注入AService属性------>当前单例池没有AService属性------>尝试创建AService对象------>进入AService的生命周期......(循环)
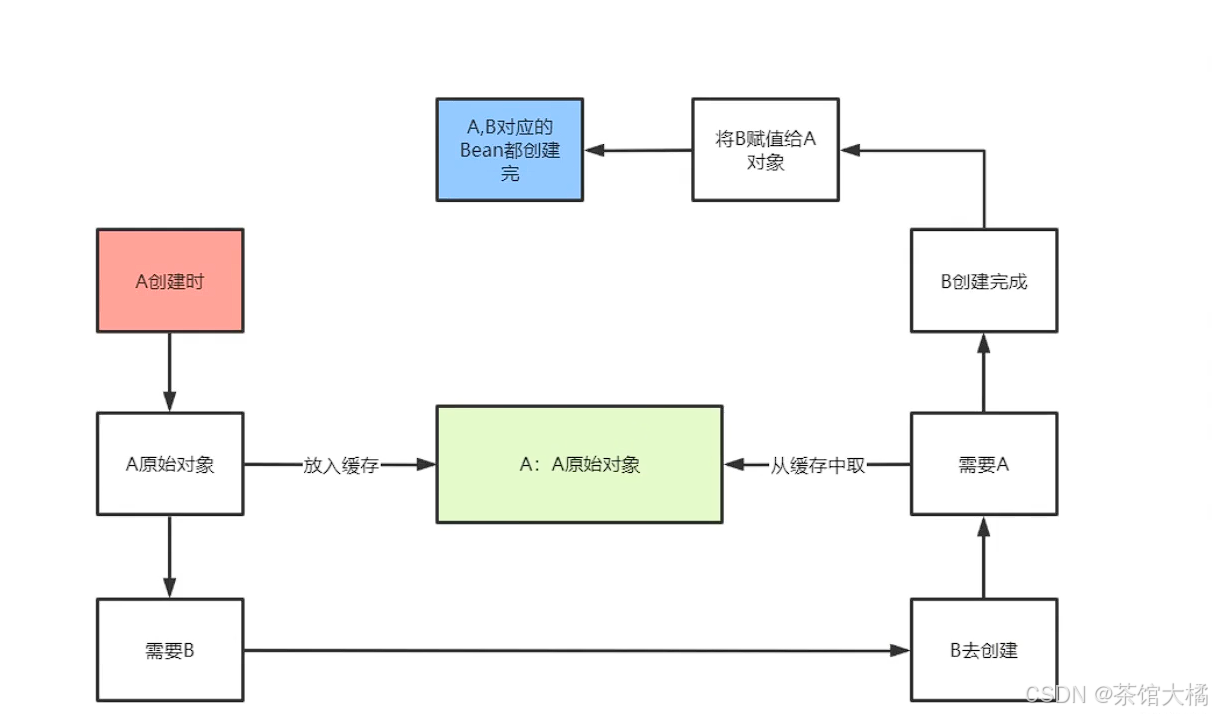
为了解决循环依赖问题,我们必须引入第二级缓存,只要曾经尝试创建过该对象,且该对象的创建生命周期没结束,就应该加入到该缓存中,这样依赖循环依赖的闭环就被打破了。加入二级缓存后的描述如下:
AService需要注入BService属性------>首先在单例池找不到------>查找二级缓存------>二级缓存找不到,尝试创建BService对象,并将BService对象加入到二级缓存------>进入到BService生命周期------>BService需要注入AService属性------>当前单例池没有AService属性------>查找二级缓存------>找到了,于是乎BService将该临时的AService代理对象注入,接着下一步自己的生命周期创建流程
问题三:为什么二级缓存的是代理对象而不是原始对象?
下图是最开始推导二级缓存的生命周期流程图,和最终的三级缓存还是有些区别的。看看就好。
其实二级缓存的缓存对象还真是原始对象。事实上二级缓存已经打破了单例Bean中的循环依赖了。但是因为我们本节讨论的是单例Bean创建过程解决的循环依赖问题。而单例Bean的创建是需要进行AOP生成代理对象的,最终也是以代理对象的形式存储到单例池中的。也就是说对于填充的aService、bService属性来说,都应该填充的是代理对象。
于是在二级缓存的选择上,我们选择临时存储单例Bean的代理对象,等到进行到后面的环节就可以直接将二级缓存中的对象转移到单例池中,从而完成了单例Bean的创建流程。
第三级缓存:原始对象池的存在意义
拿回这张图说事,二级缓存已经实现了打破循环依赖了,然而在单例Bean的创建中,我们需要用到代理对象,所以二级缓存的对象是代理对象。
问题:既然二级缓存可以打破循环依赖闭环,为何还要第三级缓存?
这里就要讲到AOP的创建代理对象流程了,实际上AOP的创建代理对象的过程中,需要传入原始对象、原始对象的Bean定义等相关信息。在发现循环依赖之后,Spring会提前进行AOP创建代理对象,这就需要人为提供创建代理对象的相关信息,如下图所示:
于是我们引入了三级缓存的概念,三级缓存即原始对象相关信息池,用于为AOP创建代理对象提供该对象的相关信息。具体的信息其实不仅仅是原始对象,还有Bean的定义、Bean的名字等等。所以三级缓存的Map中的Value还不是简单的原始对象,Spring使用了一个Lambda表达式作为三级缓存的Value(这个后面讲)。

三、数据结构分析:三级缓存各自的数据结构如何
参考源码:
// 一级缓存:单例池
// 采用ConcurrentHashMap保证线程安全
private final Map<String, Object> singletonObjects = new ConcurrentHashMap<String, Object>(256);// 三级缓存: 原始对象信息池
// 普通的HashMap
private final Map<String, ObjectFactory<?>> singletonFactories = new HashMap<String, ObjectFactory<?>>(16);// 二级缓存:临时的代理对象池
// 普通的HashMap
private final Map<String, Object> earlySingletonObjects = new HashMap<String, Object>(16);- 一级缓存:Map<BeanName,BeanProxy>
- 二级缓存:Map<BeanName,BeanProxyTemp>
- 三级缓存: Map<BeanName,LambdaDefine>
问题:为什么二级、三级缓存不用线程安全的ConcurrentHashMap
看源码就明白了,我们前面说过,创建Bean的最后,我们需要将二级缓存中的代理对象添加到单例池中,同时将二级缓存中的代理对象删除(确保同一时刻只有一个代理对象)
为了确保这两个操作的原子性。Spring在这里使用了synchronized同步代码块,用于确保操作原子性。所以在数据结构的选择上,用不上ConcurrentHashMap,而是选择性能更好的HashMap
四、源码分析:查看spring获取单例Bean的方法
org.springframework.beans.factory.support.DefaultSingletonBeanRegistry
/*** 这个方法就是spring用于获取单例Bean的方法,从中我们可以分析出三级缓存的原理* @param beanName* @param allowEarlyReference* @return*/@Nullableprotected Object getSingleton(String beanName, boolean allowEarlyReference) {// 第一步:从一级缓存中尝试获取Bean对象Object singletonObject = this.singletonObjects.get(beanName);// 如果一级缓存中没有,并且该Bean的状态正在创建中,则尝试从二级缓存中获取if (singletonObject == null && isSingletonCurrentlyInCreation(beanName)) {//第二步:使用同步代码块确保两个操作的原子性synchronized (this.singletonObjects) {//第三步: 尝试从二级缓存中获取Bean的代理对象singletonObject = this.earlySingletonObjects.get(beanName);// 如果二级缓存中也没有,并且该Bean允许提前进行AOP引用,则尝试从三级缓存中获取相关信息,进行AOPif (singletonObject == null && allowEarlyReference) {//第四步: 从三级缓存中获取Bean的工厂对象ObjectFactory<?> singletonFactory = this.singletonFactories.get(beanName);// 如果三级缓存中存在,则通过工厂对象获取Bean的代理对象,并将其放入二级缓存中if (singletonFactory != null) {// 第五步: 通过工厂对象获取Bean的代理对象singletonObject = singletonFactory.getObject();// 第六步: 将代理对象放入二级缓存中this.earlySingletonObjects.put(beanName, singletonObject);// 第七步: 从三级缓存中移除该Bean的工厂对象this.singletonFactories.remove(beanName);}}}}// 第八步: 返回获取到的Bean对象(可能是代理对象,或者原始对象)return singletonObject;}











