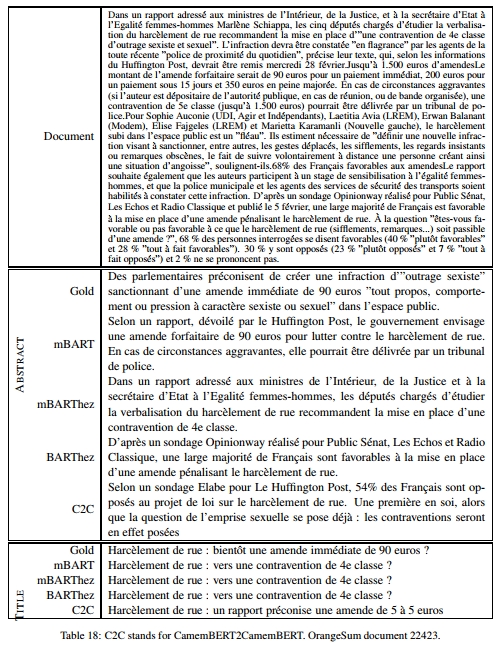
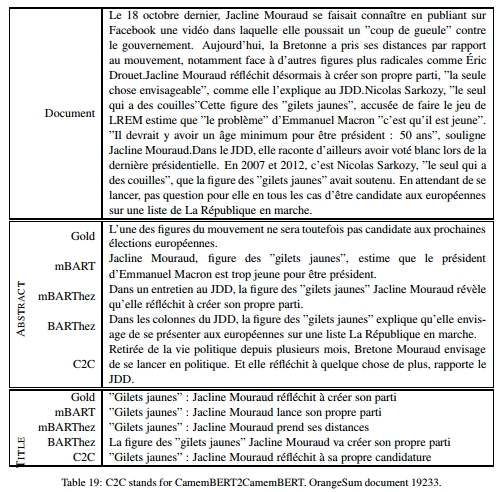
摘要
归纳迁移学习已经席卷了整个自然语言处理(NLP)领域,像BERT和BART这样的模型在无数自然语言理解(NLU)任务中创造了新的技术标杆。然而,大多数可用的模型和研究都是针对英语进行的。在这项工作中,我们引入了BARThez,这是第一个大规模预训练的法语序列到序列(seq2seq)模型。基于BART,BARThez特别适合生成任务。我们在FLUE基准测试中的五个判别任务以及我们为此研究创建的新摘要数据集OrangeSum中的两个生成任务上对BARThez进行了评估。我们展示了BARThez与基于BERT的最先进法语语言模型(如CamemBERT和FlauBERT)相比具有很强的竞争力。我们还在BARThez的语料库上继续预训练了一个多语言BART模型,并展示了我们得到的模型mBARThez显著提升了BARThez的生成性能。代码、数据和模型均已公开提供。
1 引言
归纳迁移学习,即通过在大规模数据上预训练的模型来解决任务,彻底改变了计算机视觉领域(Krizhevsky等,2012)。在自然语言处理(NLP)中,尽管标注数据稀缺,但原始文本几乎是无限的且易于获取。因此,从纯文本中学习良好表示的能力可以极大地提升自然语言理解的整体水平。
基于Transformer架构(Vaswani等,2017)的模型,如GPT(Radford等,2018)和BERT(Devlin等,2018),在大量原始数据和数百个GPU的训练下,为每个NLU任务设定了新的技术标杆。此外,全球用户可以通过微调这些公开的预训练模型来轻松受益于这些改进,从而节省大量的时间、资源和能源,相比从头训练模型。
BART(Lewis等,2019)结合了类似BERT的双向编码器和类似GPT的前向解码器,并通过更通用的掩码语言建模目标预训练了这一序列到序列(seq2seq)架构。由于BART不仅预训练了编码器,还预训练了解码器,因此在涉及文本生成的任务中表现出色。
尽管上述努力取得了巨大进展,但大多数研究和资源都集中在英语上,尽管有一些显著的例外。本文通过贡献BARThez1,部分解决了这一局限性。BARThez是第一个针对法语预训练的seq2seq模型,基于BART,并在我们为适应BART特定扰动方案而调整的过去研究中的大规模法语单语语料库上进行了预训练。与现有的基于BERT的法语语言模型(如CamemBERT(Martin等,2019)和FlauBERT(Le等,2019))不同,BARThez特别适合生成任务。我们在FLUE基准测试中的五个情感分析、释义识别和自然语言推理任务以及我们为此研究创建的新法语摘要数据集OrangeSum中的两个生成任务上对BARThez进行了评估。我们展示了BARThez与CamemBERT、FlauBERT和mBART相比具有很强的竞争力。我们还在BARThez的语料库上继续预训练了一个已经预训练的多语言BART模型。我们得到的模型mBARThez显著提升了BARThez在生成任务上的性能。
我们的贡献如下:
- 我们公开发布了第一个专为法语设计的大规模预训练seq2seq模型BARThez,该模型具有1.65亿个参数,并在128个GPU上训练了60小时,使用了101GB的文本数据。我们在五个判别任务和两个生成任务上对BARThez进行了评估,包括自动和人工评估,并展示了BARThez与当前技术水平的竞争力。
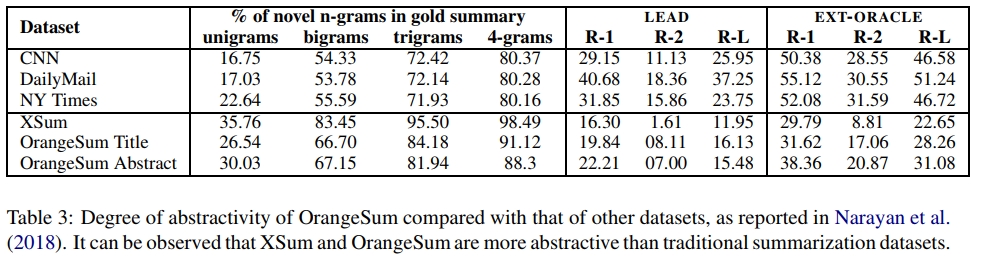
- 为了解决现有FLUE基准测试中生成任务的不足,我们创建了一个新的法语摘要数据集OrangeSum,并公开发布2。我们在本文中对该数据集进行了分析。OrangeSum比传统的摘要数据集更具抽象性,可以被视为法语版的XSum(Narayan等,2018)。
- 我们在BARThez的语料库上继续预训练了一个多语言BART模型,并展示了我们得到的模型mBARThez在生成任务上显著提升了BARThez的性能。
- 我们公开发布了我们的代码和模型3。我们的模型还被集成到了广受欢迎的Hugging Face Transformers库4中。因此,它们可以轻松地在标准、工业强度的框架中分发和部署用于研究或生产。它们还拥有自己的API,并可以在线进行交互式测试。
2 相关工作
无标签学习通过自监督学习5实现,在这种设置中,系统学会从输入的其他部分预测输入的一部分。在实践中,从未标注的数据中创建一个或多个监督任务,模型通过自定义目标学习解决这些任务。
NLP中一些最早且最著名的自监督表示学习方法包括word2vec(Mikolov等,2013)、GloVe(Pennington等,2014)和FastText(Bojanowski等,2017)。尽管这些方法是重大进步,但它们生成的是静态表示,这是一个主要限制,因为单词的含义取决于其使用的独特上下文。
深度预训练语言模型。ELMo(Peters等,2018)通过提取和组合预训练的深度双向LSTM语言模型的内部状态,提供了第一个上下文嵌入。除了词嵌入和softmax层外,前向和后向RNN具有不同的参数。ELMo的作者展示了学习到的表示可以极大地转移到下游架构中,以解决各种监督NLU任务。
Howard和Ruder(2018)提出了ULMFiT,这是一种用于文本分类的通用迁移学习方法,其中语言模型在大规模通用数据集上预训练,在特定数据集上微调,最后通过在下游任务上从头训练的分类层进行增强。
Radford等(2018)利用Transformer架构(Vaswani等,2017)开发了OpenAI GPT,该架构优于并概念上比循环神经网络更简单。更准确地说,他们预训练了一个从左到右的Transformer解码器作为通用语言模型,并通过应用不同的输入变换在12个语言理解任务上进行了微调。
BERT(Devlin等,2018)结合了上述所有模型的思想,并引入了双向预训练,通过在11个NLU任务上以较大优势设定了新的技术标杆,彻底改变了NLP领域。更准确地说,BERT使用了一个双向Transformer编码器,并采用了掩码语言模型目标,使学习到的表示能够捕捉左右上下文,而不仅仅是左上下文。BERT的巨大规模(多达24个Transformer块)也在性能中发挥了作用。
Radford等(2019)展示了GPT-2(一个参数数量比GPT多一个数量级的版本)表明,只要具有非常大的容量,通用语言模型可以在许多特定NLU任务上实现合理的性能,而无需任何微调,即实现零样本迁移。这证明了语言建模目标对归纳迁移学习的基本性质和重要性。
Liu等(2019)在RoBERTa中展示了通过优化超参数和训练程序可以提高BERT的性能。关于BERT为何以及如何如此有效的研究现在已成为一个专门的研究领域,称为BERTology(Rogers等,2020)。
语言。继BERT在英语中的成功后,一些BERT模型在其他语言中进行了预训练和评估。例如,阿拉伯语(Antoun等)、荷兰语(de Vries等,2019;Delobelle等,2020)、法语(Martin等,2019;Le等,2019)、意大利语(Polignano等,2019)、葡萄牙语(Souza等,2019)、俄语(Kuratov和Arkhipov,2019)和西班牙语(Ca˜nete等,2020)。
除了上述单语模型外,还提出了多语言模型,特别是mBERT(Devlin等,2018)、XLM(Lample和Conneau,2019)和XLM-R(Conneau等,2019)。
抽象摘要。抽象摘要是一项重要且具有挑战性的任务,需要多样化和复杂的自然语言理解和生成能力。一个好的摘要模型需要具备良好的阅读、理解和写作能力。
GPT-2可以用于摘要生成,通过从给定的起始种子中采样一定数量的标记。然而,尽管生成的文本语法正确且流畅,但摘要性能仅略优于随机抽取基线。
作为一个双向编码器,BERT不能像GPT-2那样直接用于语言生成。此外,BERT生成的是单句表示,而对于摘要,需要对多句和段落表示进行推理。Liu和Lapata(2019)提出了一种克服这些挑战的方法。在输入级别,他们引入了特殊标记来编码单个句子、区间段嵌入,并使用了比BERT更多的位置嵌入。然后,他们将预训练的BERT编码器与随机初始化的基于Transformer的解码器结合,并使用不同的优化器和学习率联合训练这两个模型。
BART和mBART。BART(Lewis等,2019)是一种去噪自编码器,通过联合预训练一个双向编码器(如BERT)和一个前向解码器(如GPT)来学习重建被破坏的输入序列。编码器和解码器都是Transformer。由于不仅编码器而且解码器都进行了预训练,BART在应用于文本生成任务时特别有效。
Liu等(2020)在25种不同语言上预训练了一个多语言BART(mBART)。他们展示了这种多语言预训练在各种机器翻译任务中带来了显著的性能提升。MASS(Song等,2019)是另一个多语言预训练的序列到序列模型,它学习预测输入序列中的掩码片段。MASS与BART的主要区别在于,前者仅预测句子的掩码部分,而后者学习重建整个被破坏的句子。这一区别使得MASS在判别任务中效果较差,因为只有掩码片段被输入到解码器中(Lewis等,2019)。ProphetNet(Yan等,2020)也采用了编码器-解码器结构,并引入了一种新的学习目标,称为未来n-gram预测。该目标通过学习在给定先前上下文的情况下预测下一个n-gram(而不是单字)来减少对局部相关性的过拟合。
3 BARThez
我们的模型基于BART(Lewis等,2019),一种去噪自编码器。它由一个双向编码器和一个从左到右的自回归解码器组成。
3.1 架构
我们使用BASE架构,包含6个编码器层和6个解码器层。由于资源限制,我们没有选择LARGE架构。我们的BASE架构在编码器和解码器中使用768个隐藏维度和12个注意力头。总共有大约1.65亿个参数。与普通的seq2seq Transformer(Vaswani等,2017)相比,该架构有两个区别。第一个是使用GeLU激活层而不是ReLU,第二个是在编码器和解码器顶部添加了一个归一化层,遵循Liu等(2020)的做法。这些额外的层有助于在使用FP16精度时稳定训练。
3.2 词汇表
为了生成我们的词汇表,我们使用SentencePiece(Kudo和Richardson,2018)实现字节对编码(BPE)(Sennrich等,2015)。我们不进行任何预分词,并将词汇表的大小固定为50K个子词。SentencePiece模型在预训练语料库的10GB随机样本上进行训练。我们将字符覆盖率固定为99.95%。
3.3 自监督学习
我们使用与BART相同的预训练方法。即,BARThez学习重建被破坏的输入。更准确地说,输入文本通过噪声函数进行扰动,模型必须通过最小化预测文本和原始文本之间的交叉熵来预测它。形式上,给定一组文档 X 1 , X 2 , . . . , X n {X1, X2, ..., Xn} X1,X2,...,Xn和一个噪声函数n,我们的目标是找到最小化以下目标的参数 θ \theta θ:
L θ = − ∑ i log P ( X i ∣ n ( X i ) ; θ ) L_\theta=-\sum_i\log P(X_i|n(X_i);\theta) Lθ=−i∑logP(Xi∣n(Xi);θ)
在噪声函数n中应用了两种不同类型的噪声。
首先,我们使用文本填充方案,其中采样若干文本片段并用一个[MASK]特殊标记替换。片段长度从泊松分布中采样( λ = 3.5 \lambda=3.5 λ=3.5),并且30%的文本被掩码。
第二种扰动方案是句子重排,其中将输入文档视为句子列表并进行随机打乱。
需要注意的是,我们遵循Lewis等(2019)的做法,他们证明了文本填充和句子重排都是获得最佳结果的必要条件。
3.4 预训练语料库
我们创建了一个适用于3.3节中描述的两种扰动方案的FlauBERT语料库(Le等,2019)版本。实际上,在原始的FlauBERT语料库中,每个句子被视为一个独立实例,而在我们的案例中,我们需要实例对应于完整的文档。
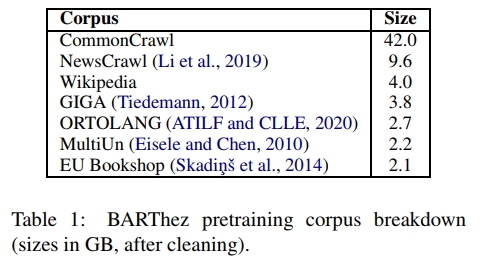
除此之外,BARThez的语料库与FlauBERT的语料库相似。它主要由CommonCrawl的法语部分、NewsCrawl、维基百科以及其他较小的语料库组成,这些语料库列在表1中。为了清理语料库中的噪声样本,我们使用了Le等(2019)提供的脚本6。需要注意的是,我们禁用了Moses分词器,因为我们使用了不需要任何预分词的SentencePiece。语料库的总大小在SentencePiece分词之前为66GB,分词之后为101GB。
3.5 训练细节
我们在128个NVIDIA V100 GPU上预训练了BARThez。我们将每个GPU的批量大小固定为6000个标记,更新频率为2,每次更新大约处理22k个文档。我们使用Adam优化器(Kingma和Ba,2014),参数设置为 ϵ = 1 0 − 6 , β 1 = 0.9 \epsilon=10^{-6},\beta_{1}=0.9 ϵ=10−6,β1=0.9, β 2 = 0.999 \beta_2=0.999 β2=0.999,学习率从 6.1 0 − 4 6.10^{-4} 6.10−4开始,并随着训练步数线性递减。我们使用了总训练步数的6%作为预热期。预训练持续了大约60小时,允许对整个语料库进行20次遍历。在前12个epoch中,我们将dropout固定为0.1,在第12到16个epoch中将其降低到0.05,最后在第16到20个epoch中将其设置为0。所有实验均使用Fairseq库(Ott等,2019)进行。
4 mBARThez
mBART(Liu等,2020)是一个多语言BART模型。它采用LARGE架构,编码器和解码器各有12层,隐藏向量大小为1024,注意力头数为16。它在包含1369GB原始文本的多语言语料库上训练了超过2.5周,使用了256个NVIDIA V100 GPU。多语言语料库涵盖了25种不同语言,包括56GB的法语文本。在原论文中,作者评估了mBART在机器翻译任务上的表现。然而,mBART也可以用于单语言任务。
我们在BARThez的语料库(见3.4节)上继续预训练了预训练的mBART,使用了128个NVIDIA V100 GPU,持续了约30小时,允许对BARThez的语料库进行4次遍历。这可以被视为语言自适应预训练的一个实例,比领域自适应预训练(Gururangan等,2020)更进一步。初始学习率设置为0.0001,并线性递减至零。我们将得到的模型称为mBARThez。
需要注意的是,由于mBART是多语言的,它使用的词汇表中包含非拉丁字符的标记。我们从mBARThez的所有嵌入层中删除了这些标记,将其参数数量从610M减少到458M。
5 OrangeSum
基于BART的模型特别适合生成任务,但遗憾的是,FLUE(Le等,2019)——法语的GLUE等效版本——仅包含判别任务7(Wang等,2018)。
因此,我们决定创建一个生成任务。我们选择了单文档抽象摘要生成任务,因为它是一个生成任务,同时也要求模型对其输入进行良好的编码。换句话说,模型要生成好的摘要,需要具备良好的阅读、理解和写作能力,这使得抽象摘要生成成为NLP中最核心和最具挑战性的评估任务之一。
动机:我们的策略是创建一个法语版的XSum数据集(Narayan等,2018)。与历史摘要数据集(如CNN、DailyMail和NY Times,由Hermann等(2015)引入)不同,这些数据集倾向于抽取式策略,而XSum要求模型表现出高度的抽象性才能表现良好。XSum是通过从BBC网站抓取文章及其单句摘要创建的,其中单句摘要不是吸引人的标题,而是捕捉文章的核心内容。
数据收集:我们采用了类似的策略,抓取了“Orange Actu”网站8。Orange S.A.是一家大型法国跨国电信公司,拥有2.66亿全球客户。我们抓取的页面涵盖了从2011年2月到2020年9月近十年的时间。它们属于五个主要类别:法国、世界、政治、汽车和社会9。社会类别本身又分为8个子类别:健康、环境、人物、文化、媒体、高科技、奇闻(法语中的“insolite”)和其他。
每篇文章都有一个单句标题以及一个非常简短的摘要,两者均由文章作者专业撰写。我们从每个页面中提取了这两个字段,从而创建了两个摘要任务:OrangeSum标题和OrangeSum摘要。这两个任务的金标准摘要平均长度分别为11.42和32.12个单词(见表2)。
需要注意的是,与XSum类似,OrangeSum中的标题往往不是吸引人的标题,而是传达文章的核心内容。摘要也是如此。
后处理:作为后处理步骤,我们删除了所有空文章以及标题少于5个单词的文章。对于OrangeSum摘要,我们删除了摘要中新词比例最高的10%的文章,因为我们观察到这些摘要往往是引言而非真正的摘要。这对应的新词比例阈值为57%。
对于OrangeSum标题和OrangeSum摘要,我们分别留出了1500对数据进行测试,1500对数据进行验证,并使用其余所有数据进行训练。我们公开了该数据集10。
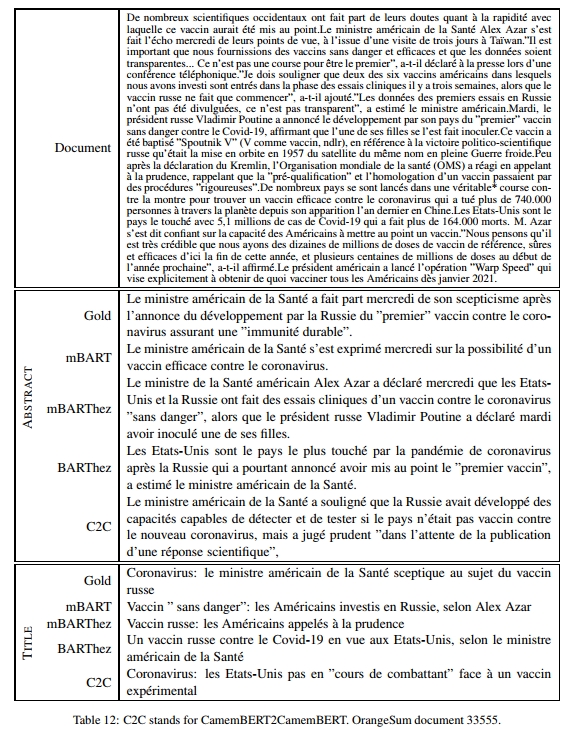
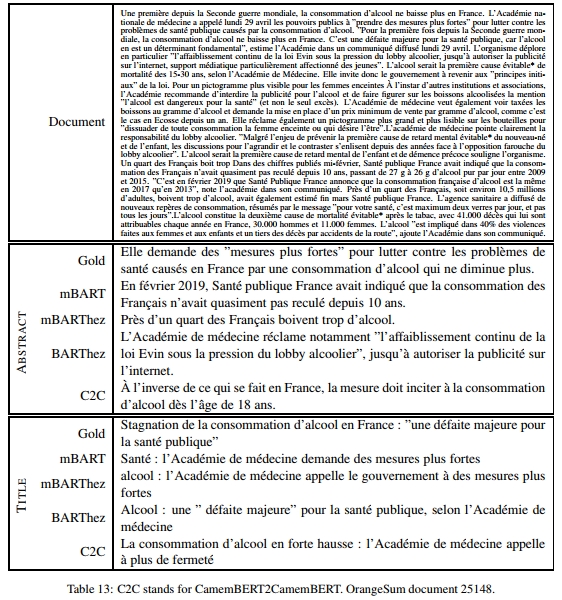
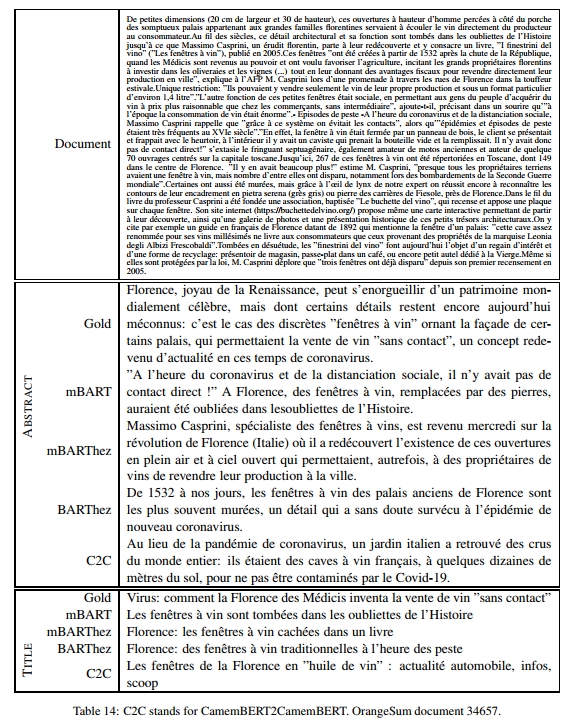
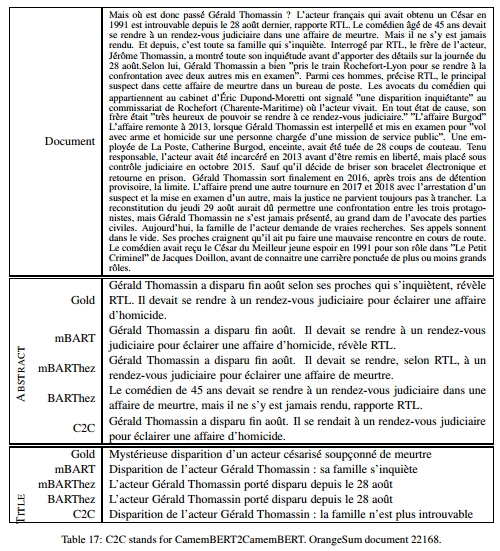
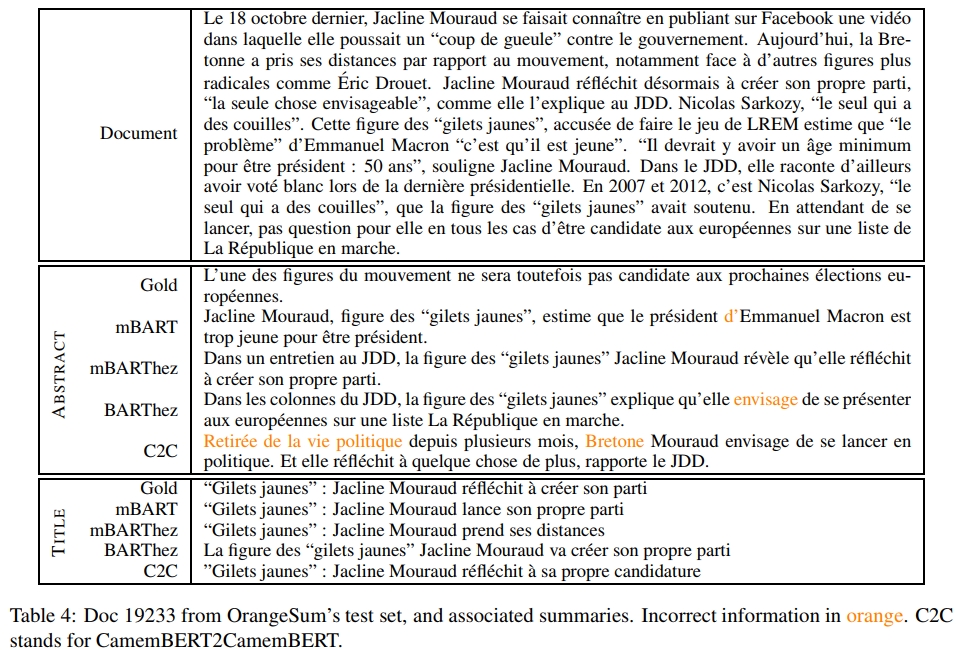
表4提供了一个文档及其摘要的示例。更多示例见附录。
分析:表2将OrangeSum与XSum以及著名的CNN、DailyMail和NY Times数据集进行了比较。我们可以看到,OrangeSum的两个数据集在统计数据上与XSum非常相似,但规模比XSum小一个数量级。然而,OrangeSum的规模仍然允许有效的微调,正如我们在实验中所展示的那样。表3提供了经验证据,表明与传统的抽象摘要数据集相比,OrangeSum和XSum一样,对抽取式系统的偏见较小。OrangeSum摘要参考摘要中有30%的新词,OrangeSum标题中有26.5%的新词,而XSum中有35.7%,CNN中有17%,DailyMail中有17%,NY Times中有23%。这表明XSum和OrangeSum的摘要更具抽象性。这些观察结果也得到了以下事实的证实:两个抽取式基线LEAD和EXT-ORACLE在XSum和OrangeSum上的表现远不如在其他数据集上。
6 实验
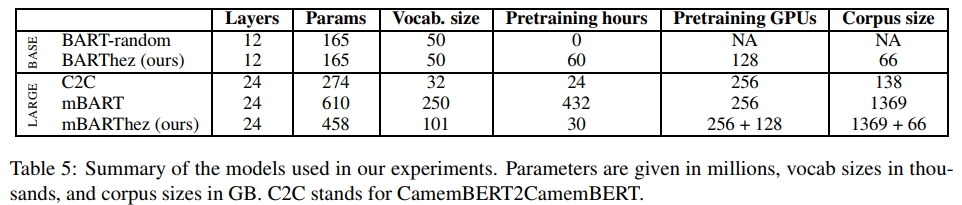
我们将BARThez和mBARThez与以下模型进行了比较,总结在表5中。
-
mBART:第4节中描述的多语言BART LARGE模型。
-
CamemBERT2CamemBERT(C2C):为了将CamemBERT应用于我们的生成任务,我们使用了Rothe等(2020)提出的BERT2BERT方法。更准确地说,我们微调了一个序列到序列模型,其编码器和解码器参数均使用CamemBERT LARGE的权重初始化。唯一随机初始化的权重是编码器-解码器注意力权重。
-
BART-random:作为额外的基线,我们训练了一个与BARThez具有相同架构和词汇表的模型,并在下游任务上从头开始训练。
6.1 摘要生成
所有预训练模型均微调了30个epoch,我们使用的学习率在6%的训练步数内预热到0.0001,然后线性递减到0。BART-random训练了60个epoch。我们选择与最佳验证分数相关的检查点来生成测试集摘要,使用束搜索,束大小为4。
我们通常报告ROUGE-1、ROUGE-2和ROUGE-L分数(Lin,2004),见表6。然而,由于ROUGE仅限于捕捉n-gram重叠,这在抽象摘要生成设置中不太适用,因此我们还报告了BERTScore分数。BERTScore(Zhang等,2019)是最近引入的一种指标,它利用候选句子和参考句子的上下文表示。
根据Narayan等(2018)的做法,我们在评估中包含了两个抽取式基线:LEAD和EXT-ORACLE。LEAD通过从文档中提取前n个句子来创建摘要。在我们的案例中,我们设置 n = 1 n=1 n=1。第二个基线EXT-ORACLE从文档中提取一组最大化特定分数的句子。在我们的案例中,我们提取了最大化ROUGE-L的一个句子。
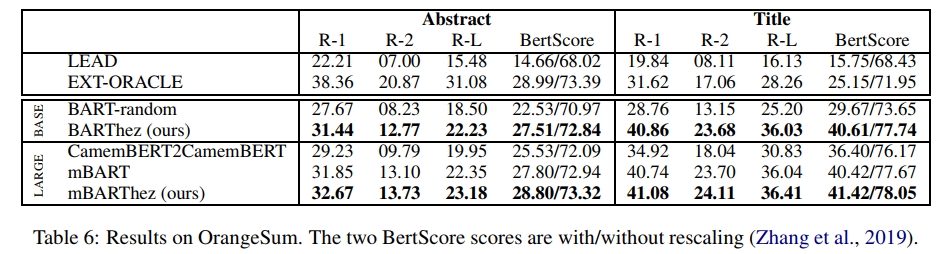
定量结果:表6比较了在摘要生成任务上微调的模型的表现。尽管参数数量是mBART的四分之一,BARThez在ROUGE和BERTScore方面与mBART相当。mBARThez显著优于BARThez和mBART,并在所有指标上达到了最佳性能。这突显了在微调之前将多语言预训练模型适应特定语言的重要性(语言自适应预训练)。这也表明,当进行适当的适应时,利用多语言模型执行单语言下游任务可能是有优势的,可能是因为可以学习到一些跨语言的特征和模式。最后,所有基于BART的模型都显著优于CamemBERT2CamemBERT。
人工评估:为了验证我们的积极定量结果,我们进行了一项由11名法语母语者参与的人工评估研究。根据Narayan等(2018)的做法,我们使用了最佳-最差缩放法(Louviere等,2015)。在这种方法中,两个不同系统的摘要及其输入文档被呈现给人类评估者,评估者必须决定哪个摘要更好。我们要求评估者基于三个标准进行判断:准确性(摘要是否包含准确的事实?)、信息量(摘要是否捕捉了文档中的重要信息?)和流畅性(摘要是否以良好的法语书写?)。
我们在分析中包括了BARThez、mBARThez、mBART和C2C模型,以及金标准摘要。我们从OrangeSum摘要的测试集中随机抽取了14个文档,并为每个文档生成了所有可能的摘要对,共140对。每对摘要被随机分配给三个不同的评估者,总共产生了420个评估任务。模型的最终得分是其摘要被选为最佳的次数百分比减去被选为最差的次数百分比。得分见表9。mBARThez在定量结果中排名第一,但在人工评估中以更大的优势领先。有趣的是,BARThez在定量结果中与mBART相当,但在人工评估中显著优于mBART。需要注意的是,CamemBERT2CamemBERT的负分应与其他模型进行比较。也就是说,C2C的摘要被判断为更差的次数更多。

令人惊讶的是,BARThez和mBARThez的摘要经常被判断为比金标准摘要更好。我们假设,由于金标准摘要是由文章作者撰写的简短摘要,它们可能写得好,但包含文档中缺失的信息,例如日期。在这种情况下,评估者可能会认为这些信息不准确(例如,由于模型幻觉)并倾向于其他模型。
**定性结果 **
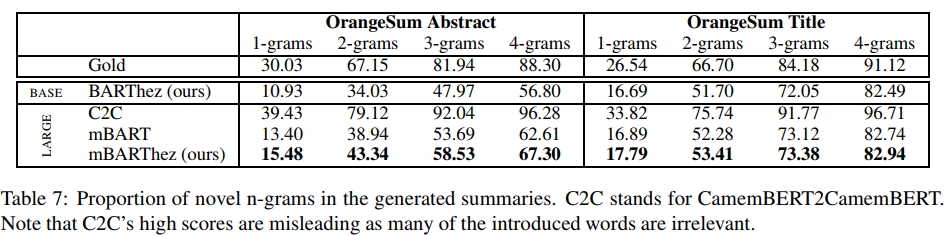
如表7所示,mBARThez比BARThez和mBART更具抽象性,这通过生成摘要中新n-gram的比例来衡量。例如,在摘要任务中,mBARThez的摘要中平均引入了15.48%的新词,而BARThez和mBART分别为10.93%和13.40%。有趣的是,尽管mBARThez的抽象性更高,但在衡量n-gram重叠的ROUGE指标上,它仍然在所有任务中排名第一。我们假设BARThez比mBART和mBARThez抽象性较低,是因为它基于BASE架构而非LARGE架构,因此参数数量是后者的四分之一。
最后,还需要注意的是,CamemBERT2CamemBERT(C2C)引入了许多新词,这起初可能被认为是好事。然而,它也经常重复自己(见表8),并且在ROUGE、BERTSum和人工评估得分上表现较低。手动观察发现,实际上C2C引入的许多新词是无关的(见附录中的摘要示例)。
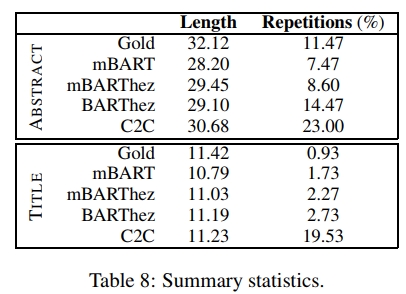
此外,与Rothe等(2020)类似,我们计算了摘要的长度以及至少有一个非停用词重复的摘要百分比。我们使用了系统和金标准摘要中出现频率最高的500个词作为停用词。从表8可以看出,无论是摘要任务还是标题任务,所有模型生成的摘要长度都非常接近金标准摘要的长度。
在重复方面,最接近金标准且冗余最少的模型是mBART和mBARThez。这在摘要任务中尤为明显,因为摘要任务的重复可能性更大。在这个任务中,mBART和mBARThez的重复率低于9%,而BARThez和C2C分别为14.5%和23%,金标准摘要的重复率为11.5%。C2C在标题任务中也比其他模型冗余得多,重复率为19.5%,远高于金标准。
6.2 判别任务
除了生成任务外,类似BART的模型还可以执行判别任务(Lewis等,2019)。在序列分类任务中,输入序列被同时输入编码器和解码器,序列中最后一个标记的表示通过在其上添加分类头来使用。当输入由多个句子组成时,这些句子用特殊标记分隔并拼接在一起。我们在FLUE基准测试11(Le等,2019)中的五个判别任务上评估了不同模型,FLUE是法语的GLUE等效版本(Wang等,2018)。
- CLS:跨语言情感分析数据集(Prettenhofer和Stein,2010)由亚马逊评论组成,任务是将其分类为正面或负面。它包含3个产品类别:书籍、DVD和音乐。训练集和测试集是平衡的,每个类别包含2000个示例。根据Le等(2019)的做法,我们使用20%的训练集作为验证集。
- PAWSX:跨语言对抗性释义识别数据集(Yang等,2019)包含句子对,任务是预测它们在语义上是否等价。训练集有49401个示例,开发集有1992个,测试集有1985个。
- XNLI:跨语言自然语言推理语料库(Conneau等,2018)包含句子对,任务是预测第一个句子(前提)是否蕴含第二个句子(假设)、与之矛盾,或既不蕴含也不矛盾(中性关系)。训练集有392702对,开发集有2490对,测试集有5010对。
训练细节:在所有实验中,我们微调模型10个epoch,学习率从 { 1 0 − 4 , 5.1 0 − 5 , 1 0 − 5 } \{10^{-4},5.10^{-5},10^{-5}\} {10−4,5.10−5,10−5}中选择,基于最佳验证分数。我们使用不同的随机种子重复每个实验3次,并报告平均值和标准差。
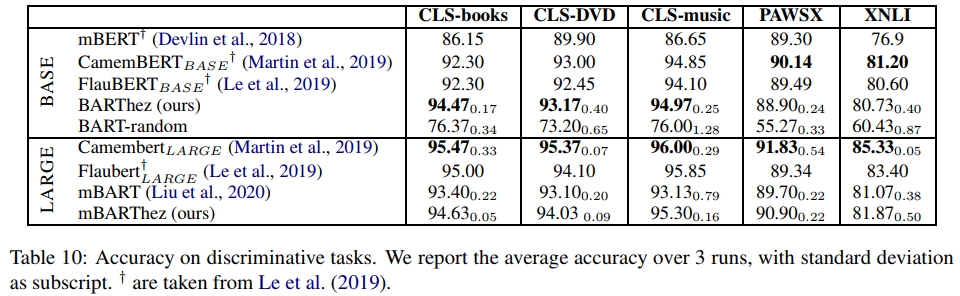
结果:表10报告了测试集的准确率。为了进行比较,我们还复制了Le等(2019)中报告的其他相关基于BERT的模型的结果。这些模型包括mBERT(Devlin等,2018)、CamemBERT(Martin等,2019)和FlauBERT(Le等,2019)。
在具有BASE架构的模型中,BARThez在三个情感分析任务中表现最佳,而在释义和推理任务中与CamemBERT和FlauBERT非常接近。在LARGE模型中,mBARThez在所有任务中均优于mBART,再次显示了语言自适应预训练的重要性。另一方面,CamemBERT和FlauBERT在大多数任务中优于mBARThez,这可能归因于CamemBERT和FlauBERT在单语法语语料库上训练了大约10倍的GPU小时数。然而,考虑到单语训练时间的巨大差异,mBARThez能够如此接近甚至有时超越FlauBERT(例如在PAWSX上领先1.56分)是值得注意的。
我们可以得出结论,BARThez和mBARThez在生成任务上的出色表现并未以判别任务性能下降为代价,这与BART论文(Lewis等,2019)中的结果一致。
7 结论
我们发布了BARThez和mBARThez,这是第一个针对法语的大规模预训练seq2seq模型,以及一个受XSum数据集启发的新法语摘要数据集。通过在摘要数据集上评估我们的模型,我们展示了:(1)BARThez与mBART表现相当,尽管其参数数量是后者的四分之一;(2)mBARThez通过在预训练中添加一个相对经济的语言自适应阶段,显著提升了mBART的性能。此外,我们在5个情感分析、释义和自然语言推理任务上评估了BARThez和mBARThez,并与最先进的基于BERT的法语语言模型(FlauBERT和CamemBERT)进行了比较,获得了非常有竞争力的结果。未来的一个有趣研究方向是进一步探索语言自适应预训练方法。
附录
在接下来的内容中,我们提供了从OrangeSum测试集中随机选择的10个文档的参考摘要和模型生成的摘要(摘要任务和标题任务)。