
【GPT入门】第31课 ollama运行私有化部署的模型、代码调用与调试
- 1. 官网下载ollama
- 2. 运行模型
- 3. OllamaLLM模型代码运行
- 4 langchain OpenAI模型本机调用与远程调用
- 5. 模型的调试
1. 官网下载ollama
https://ollama.com/ 官网下载,不断下一步安装就行,如果C盘比较少,建议变更模型安装路径。
2. 运行模型
如果模型不存在,就自动下载。
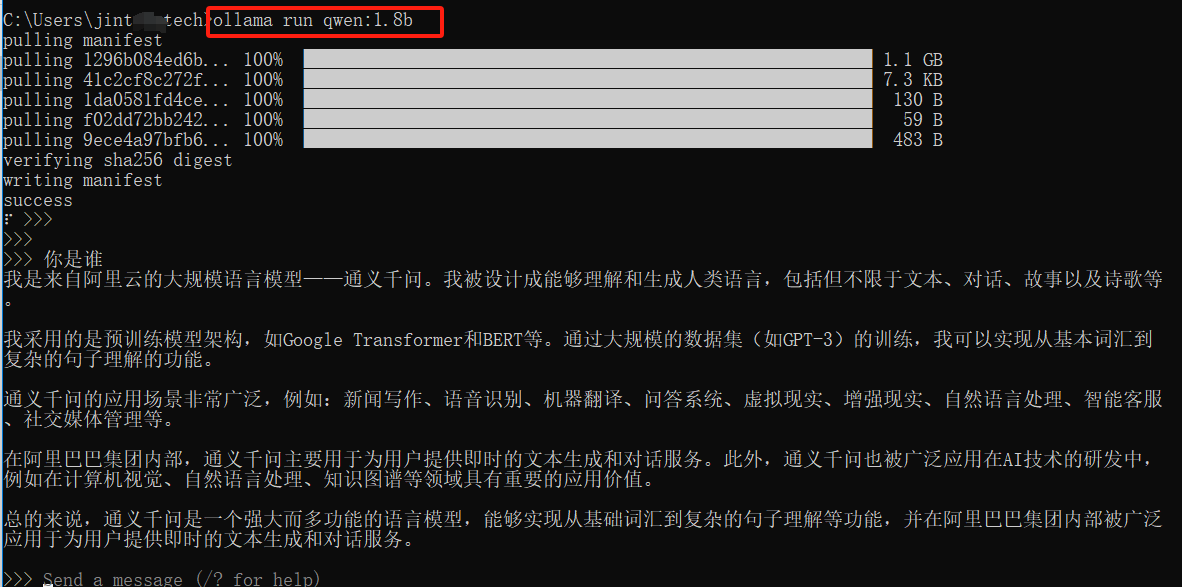
检查磁盘大小:
C:\Users\jintech>ollama list
NAME ID SIZE MODIFIED
qwen:1.8b b6e8ec2e7126 1.1 GB 4 minutes ago

C:\Users\jintech>ollama cp qwen:1.8b gpt-4:latest
copied ‘qwen:1.8b’ to ‘gpt-4:latest’
C:\Users\jintech>ollama list
NAME ID SIZE MODIFIED
gpt-4:latest b6e8ec2e7126 1.1 GB 11 seconds ago
gpt-3.5-turbo:latest b6e8ec2e7126 1.1 GB 2 minutes ago
qwen:1.8b b6e8ec2e7126 1.1 GB 13 minutes ago
检查磁盘大小:发现,大小不变。
3. OllamaLLM模型代码运行
# from langchain_community.llms import Ollama 过期
from langchain_ollama import OllamaLLM
# llm = OllamaLLM(model="qwen:1.8b")
llm = OllamaLLM(model="gpt-4")
print(llm.invoke("你是谁?"))
print(llm.predict("你是谁?"))
4 langchain OpenAI模型本机调用与远程调用
# from langchain_community.llms import Ollama
from langchain_ollama import ChatOllama
from langchain_openai import ChatOpenAI
# llm = OllamaLLM(model="qwen:1.8b")
llm = ChatOllama(model="gpt-4")
print(llm.invoke("你是谁?"))llm = ChatOpenAI(api_key="EMPTY",base_url="http://localhost:11434/v1"
)
print("chatopenai:", llm.invoke("什么是大模型?"))
5. 模型的调试
from langchain_ollama import OllamaLLM
from langchain.globals import set_debug
set_debug(True)
llm = OllamaLLM(model="gpt-4")
print(llm.invoke("你是谁?"))C:\ProgramData\anaconda3\envs\gptLearning\python.exe "E:\workspace\gptLearning\gptLearning\ls10\06 ollama\03.debug.py"
[llm/start] [llm:OllamaLLM] Entering LLM run with input:
{"prompts": ["你是谁?"]
}
[llm/end] [llm:OllamaLLM] [10.40s] Exiting LLM run with output:
{"generations": [[{"text": "我是来自阿里云的大规模语言模型——通义千问。通义千问能够理解和生成多种自然语言,如中文、英文等,并且具有强大的知识图谱构建能力,能够从海量的文本数据中挖掘出有价值的知识,从而帮助用户更加有效地完成任务和获取信息。\n\n在使用通义千问时,您可以将其作为聊天机器人、知识图谱编辑器、内容创作助手等应用的主体功能。通过与各种应用场景的深度融合,通义千问不仅可以为用户提供丰富多样的语言服务和应用体验,还可以推动各应用场景之间的数据交换和知识共享,从而更好地服务于人类社会的发展和社会进步。","generation_info": {"model": "gpt-4","created_at": "2025-04-02T13:23:39.6653804Z","done": true,"done_reason": "stop","total_duration": 10395253300,"load_duration": 33002200,"prompt_eval_count": 11,"prompt_eval_duration": 507188000,"eval_count": 136,"eval_duration": 9854459900,"response": "","context": [151644,872,198,105043,100165,11319,151645,198,151644,77091,198,104198,101919,102661,99718,104197,100176,102064,104949,8545,31935,64559,99320,56007,1773,31935,64559,99320,56007,100006,115167,43959,101312,99795,102064,3837,29524,104811,5373,105205,49567,3837,103937,100629,104795,100032,28029,101454,104004,99788,3837,100006,45181,112300,9370,108704,20074,15946,102541,20221,111185,107232,3837,101982,100364,20002,101896,107980,60548,88802,33108,45912,27369,1773,198,198,18493,37029,31935,64559,99320,56007,13343,3837,107952,105278,100622,105292,104354,5373,100032,28029,101454,57019,31548,5373,43815,104223,110498,49567,99892,9370,101273,98380,1773,67338,57218,100646,116541,9370,112077,3837,31935,64559,99320,56007,111601,17714,110782,100733,42140,100535,102064,47874,33108,99892,101904,3837,104468,101890,99200,116541,104186,20074,106198,33108,100032,101203,3837,101982,105344,112281,103971,99328,103949,106640,101300,1773]},"type": "Generation"}]],"llm_output": null,"run": null,"type": "LLMResult"
}
我是来自阿里云的大规模语言模型——通义千问。通义千问能够理解和生成多种自然语言,如中文、英文等,并且具有强大的知识图谱构建能力,能够从海量的文本数据中挖掘出有价值的知识,从而帮助用户更加有效地完成任务和获取信息。在使用通义千问时,您可以将其作为聊天机器人、知识图谱编辑器、内容创作助手等应用的主体功能。通过与各种应用场景的深度融合,通义千问不仅可以为用户提供丰富多样的语言服务和应用体验,还可以推动各应用场景之间的数据交换和知识共享,从而更好地服务于人类社会的发展和社会进步。Process finished with exit code 0





_web前端开发设计_荆州百度推广_百度一下首页手机版)





