
1. 如果把上线换为20万元,分成的份数乘5,应该就是份数最多的情况。同时,这20万元不可有重复。但我实际操作时发现这种方法不可取。因为无法做到不重复满足20万元刚好成立的情况。
如果把上线换为20万元,分成的份数乘5,应该就是份数最多的情况。同时,这20万元不可有重复。但我实际操作时发现这种方法不可取。因为无法做到不重复满足20万元刚好成立的情况。
但我发现在用电脑自带的计算器计算时,最多到8,就会超出100万元的界限,所以我们可以硬算出来答案,只需要设计最多8个系数。
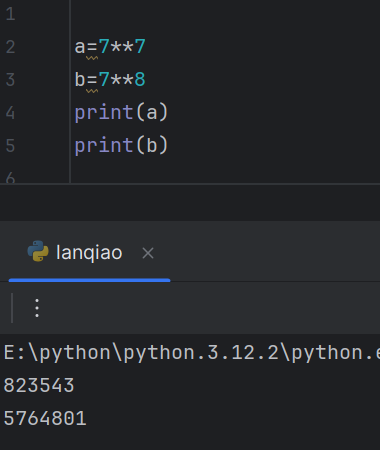
所以我们可以直接暴力:
count=0
list1=[]
max=0
for i1 in range(0,6):for i2 in range(0, 6):for i3 in range(0, 6):for i4 in range(0, 6):for i5 in range(0, 6):for i6 in range(0, 6):for i7 in range(0, 6):for i8 in range(0, 6):if i1*1+i2*7+i3*(7**2)+i4*(7**3)+i5*(7**4)+i6*(7**5)+i7*(7**6)+i8*(7**7)==1000000:count=i1+i2+i3+i4+i5+i6+i7+i8list1.append(count)if count>max:max = countprint(max)我看了题解,有大佬提出:将100万转化为7进制,刚好一一对应,这里不要被最大值迷惑了,进制转化结果唯一。至于为什么不会出现第六份,我也不太清楚。
# 解题思路:将100万转换为7进制数,数位之位即份数
total_amount = 1000000
sum_of_digits = 0
while total_amount > 0:remainder = total_amount % 7total_amount = total_amount // 7sum_of_digits += remainder
print(sum_of_digits)2.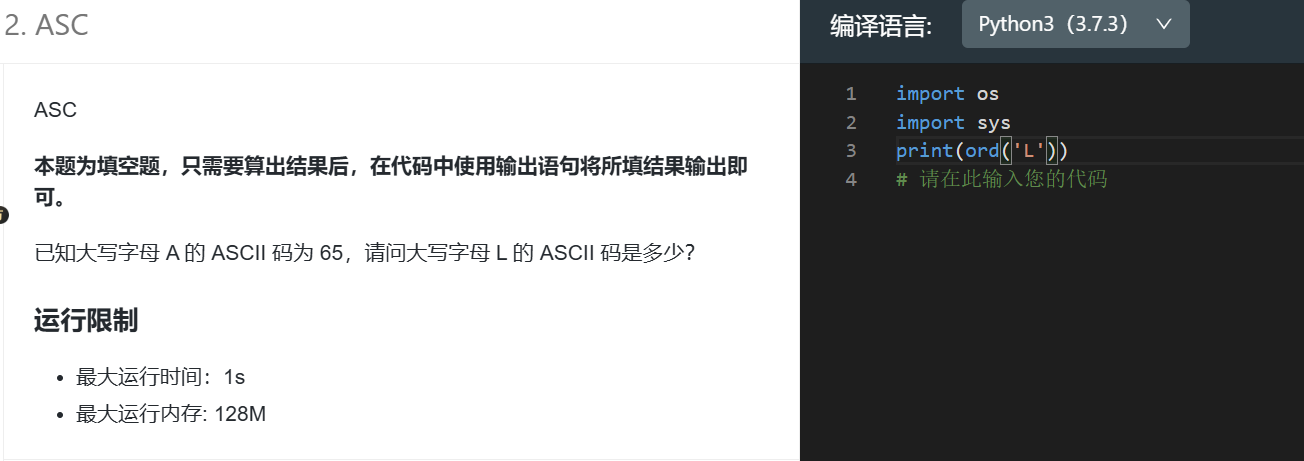
最先开始没有想起ord(),于是排列字母数出来的。在考场上面忘记字母排序也不要紧,打开EXCEL表格,竖列是字母排序。
ord() 函数是 chr() 函数(对于8位的ASCII字符串)或 unichr() 函数(对于Unicode对象)的配对函数,它以一个字符(长度为1的字符串)作为参数,返回对应的 ASCII 数值,或者 Unicode 数值,如果所给的 Unicode 字符超出了你的 Python 定义范围,则会引发一个 TypeError 的异常。
chr() 用一个范围在 range(256)内的(就是0~255)整数作参数,返回一个对应的字符。
print (chr(0x30), chr(0x31), chr(0x61) ) # 十六进制
#0 1 a
print (chr(48), chr(49), chr(97) ) # 十进制
#0 1 a
print(4+19+21*20)这里外围4刀,行数19刀,边缘21*20,加起来即可。刚开始我用列算的,中间加的21刀,我想这样边缘数会少一点,但其实边缘数没有差别,先开行还是列不影响边缘数的值,所以第二次裁行。这里也可以找规律,440-1+4,算出来也是一样的。
3.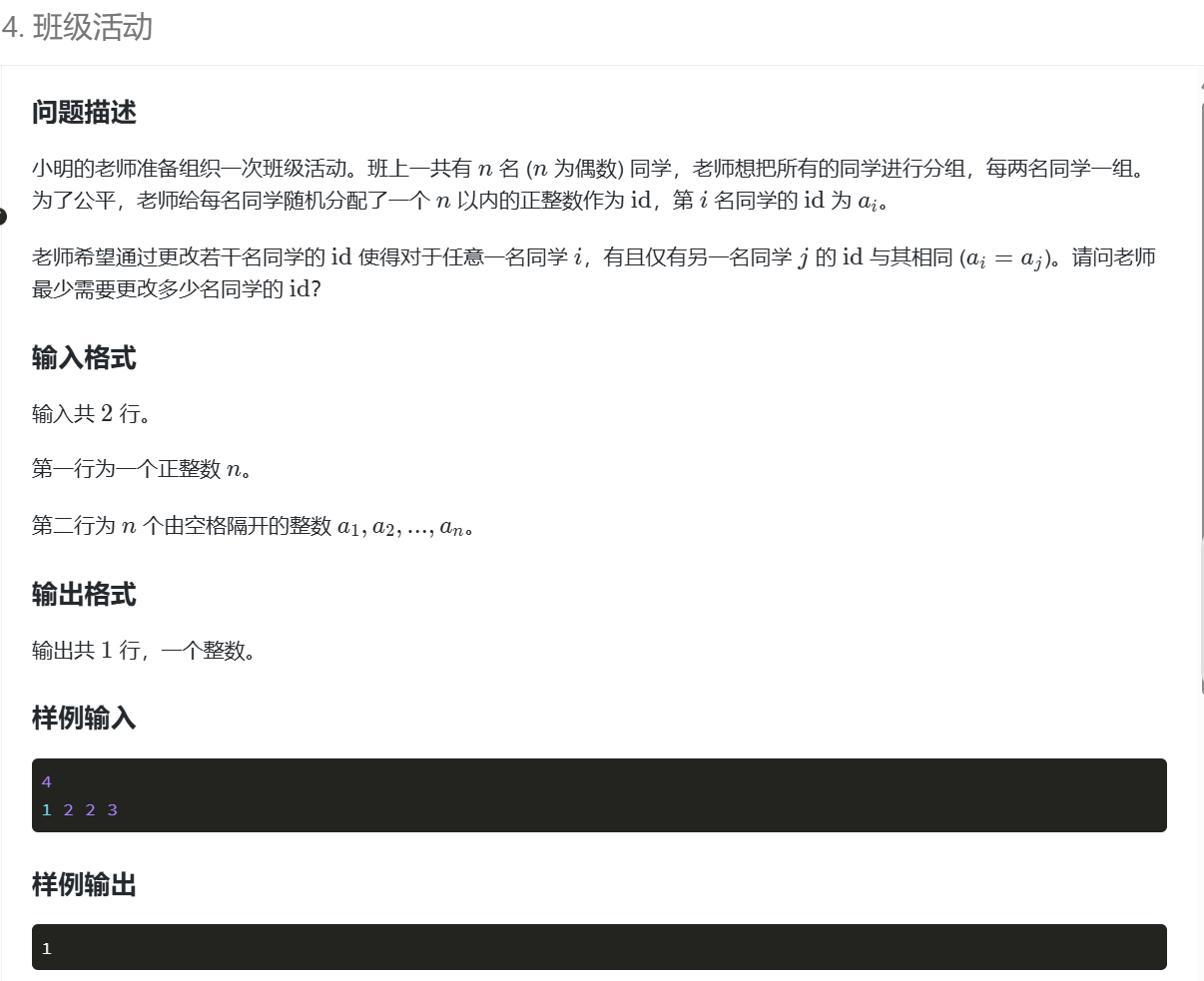
n=int(input())
a=list(map(int,input().split()))
cnt={}
for i in range(n):if a[i] not in cnt:cnt[a[i]]=0cnt[a[i]]+=1
c1=0;c2=0
for k,v in cnt.items():if v>2:c2+=(v-2)if v==1:c1+=1
if c2>=c1:print(c2)
else:print(c2+(c1-c2)//2)我没写出这道题,看的题解。
-
这段代码遍历列表for k, v in cnt.items():if v > 2:c2 += (v - 2)if v == 1:c1 += 1a,统计每个id的出现次数,并存储在字典cnt中。- 如果
a[i]不在cnt中,则将其初始化为 0。 - 然后,将
a[i]的计数加 1。
- 如果
-
初始化两个计数器for k, v in cnt.items():if v > 2:c2 += (v - 2)if v == 1:c1 += 1c1和c2。c1用于统计出现次数为 1 的id数量(即完全未配对的id)。c2用于统计出现次数超过 2 的id的“多余”次数(即v-2,表示超出两个配对所需的部分)。
-
遍历字典if c2 >= c1:print(c2) else:print(c2 + (c1 - c2) // 2)cnt的键值对。- 如果某个
id的出现次数v大于 2,则将其“多余”次数(v-2)加到c2上。 - 如果某个
id的出现次数v等于 1,则将c1加 1。
- 如果某个
-
如果if c2 >= c1:print(c2) else:print(c2 + (c1 - c2) // 2)c2大于或等于c1,则输出c2。这意味着如果有足够的“多余”id来配对所有未配对的id,则不需要额外的更改(但这里的逻辑并不完全正确,因为c2的计算方式并不能直接用于配对未配对的id)。 - 否则,输出
c2 + (c1 - c2) // 2。这部分试图处理当“多余”id不足以配对所有未配对的id时的情况。
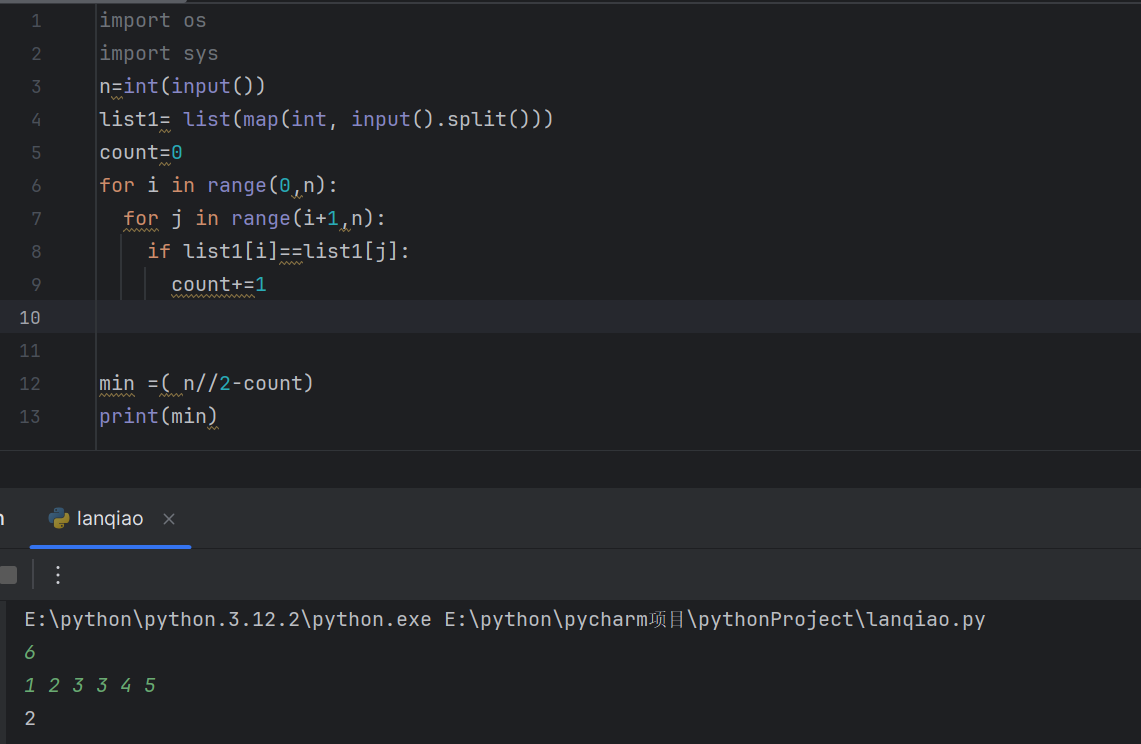
之前一直不成功,后来发现是输入里有空格没去,所以造成等于空格的情况出现。这个代码在我自己检测时可以正常出结果,但是没有通过蓝桥的测试。难道是因为超时吗?检测时显示解题耗时818分钟。这确实太长了。
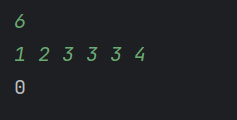 我发现在某个数出现超过1的奇数次时会出现问题,所以这个代码在结构上有问题。
我发现在某个数出现超过1的奇数次时会出现问题,所以这个代码在结构上有问题。
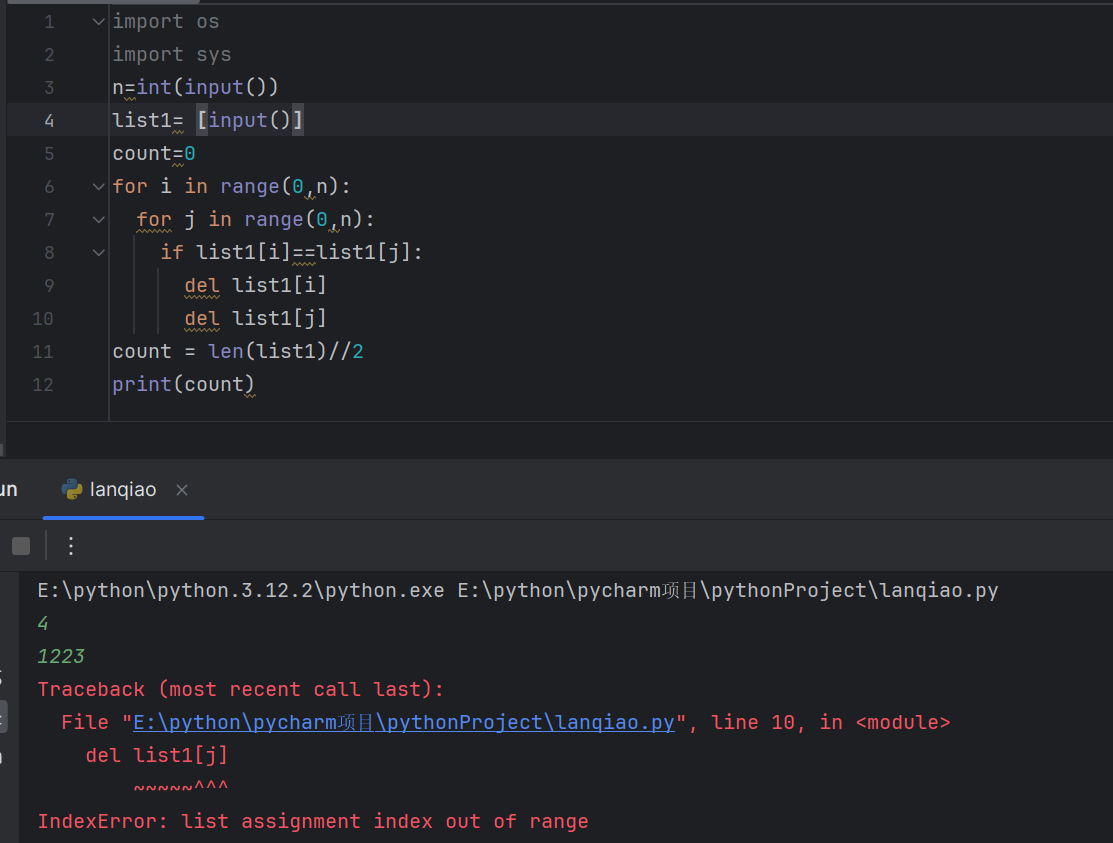
这是我第一次的代码,好像在列表删除某个数之后,其他位置也会发生变化,所以出现错误
5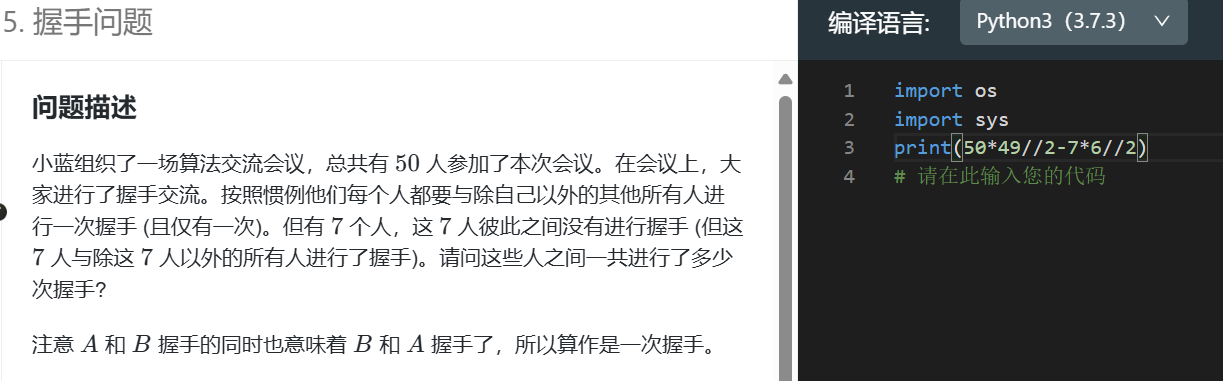
这道题很简单,两个握手次数相减即可。
n= int(input())
count=0def count1(n):position = 1 # 从个位开始,个位是奇数位(1-based index for explanation)while n > 0:digit = n % 10if position % 2 == 1: # 奇数位if digit % 2 == 0: # 奇数位上的数字应该是奇数return Falseelse: # 偶数位if digit % 2 != 0: # 偶数位上的数字应该是偶数return Falsen//= 10position += 1return True
for i in range(1,n+1):if count1(i):count+=1
print(count)
- 使用
position变量来跟踪当前位是奇数位还是偶数位(从个位开始,个位视为奇数位)。 - 逐位检查数字,如果奇数位上的数字不是奇数,或者偶数位上的数字不是偶数,则返回
False。 - 如果所有位都满足条件,则返回
True。
这道题我刚开始想暴力
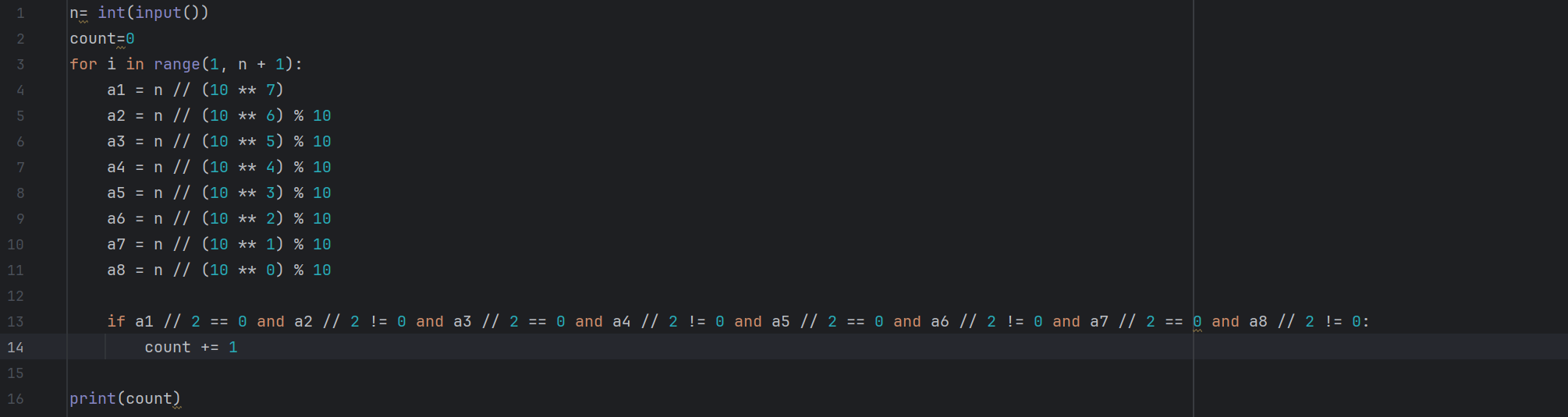
但我突然发现在位数不足,高位为0时这个式字不成立。
题解也有简单的解决方案:
import os
import sys
n = int(input())
m = 0 #计数
for i in range(1, n + 1):#检索所有的数,因为从1开始,所以循环这么写,不懂的补一补#i自身循环判断是否符合要求,一直除以10向下取整,最后就会为零while i > 0: if i % 2 != 0: #判断个位奇偶i = i // 10 #向下取整就到十位了else:break #不符合要求结束循环i最终没有到达0if i % 2 == 0: #判断十位i = i // 10 #除以10else:breakif i == 0:#符合题目要求的i最后都会为零,我们就计1个数m += 1
print(m)# 请在此输入您的代码











