1 if
最让人耳熟能详的语句应当是 if 语句。可有零个或多个 elif 部分,else 部分也是可选的。关键字 'elif' 是 'else if' 的缩写,用于避免过多的缩进。if ... elif ... elif ... 序列可以当作其它语言中 switch 或 case 语句的替代品。
x = int(input("请输入一个数字: "))
if x < 0:x = 0print('将输入的值设置为0')
elif x == 0:print('Zero')
elif x == 1:print('Single')
else:print('More')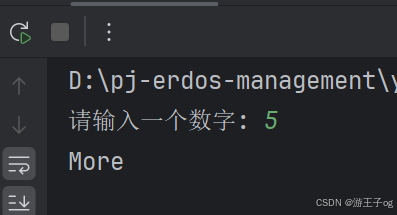
2 for
2.1 基本用法
Python 的 for 语句与 C 或 Pascal 中的不同。Python 的 for 语句不迭代算术递增数值,或是给予用户定义迭代步骤和结束条件的能力,而是在列表或字符串等任意序列的元素上迭代,按它们在序列中出现的顺序。 例如:
words = ['cat', 'window', 'defenestrate']
for w in words:print(w, len(w))很难正确地在迭代多项集的同时修改多项集的内容。更简单的方法是迭代多项集的副本或者创建新的多项集:
# 创建示例多项集
users = {'Hans': 'active', 'Éléonore': 'inactive', '景太郎': 'active'}# 策略:迭代一个副本
for user, status in users.copy().items():if status == 'inactive':del users[user]# 策略:创建一个新多项集
active_users = {}
for user, status in users.items():if status == 'active':active_users[user] = status2.2 range() 函数
内置函数 range() 用于生成等差数列,生成的序列绝不会包括给定的终止值;range(10) 生成 10 个值——长度为 10 的序列的所有合法索引。range 可以不从 0 开始,且可以按给定的步长递增(即使是负数步长)
for i in range(5):print(i)print(list(range(5, 10)))
print(list(range(0, 10, 3)))
print(list(range(-10, -100, -30)))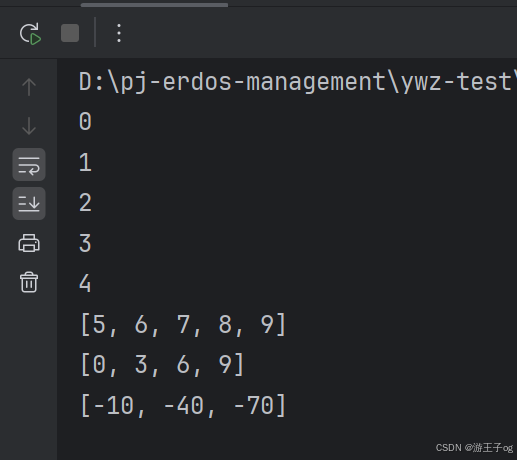
要按索引迭代序列,可以组合使用 range() 和 len(),不过大多数情况下 enumerate() 函数很方便, enumerate() 返回一个枚举对象。iterable 必须是一个序列,或 iterator,或其他支持迭代的对象。 enumerate() 返回的迭代器的 __next__() 方法返回一个元组,里面包含一个计数值(从 start 开始,默认为 0)和通过迭代 iterable 获得的值。
a = ['Mary', 'had', 'a', 'little', 'lamb']
for i in range(len(a)):print(i, a[i])print(list(enumerate(a)))
print(list(enumerate(a, start=1)))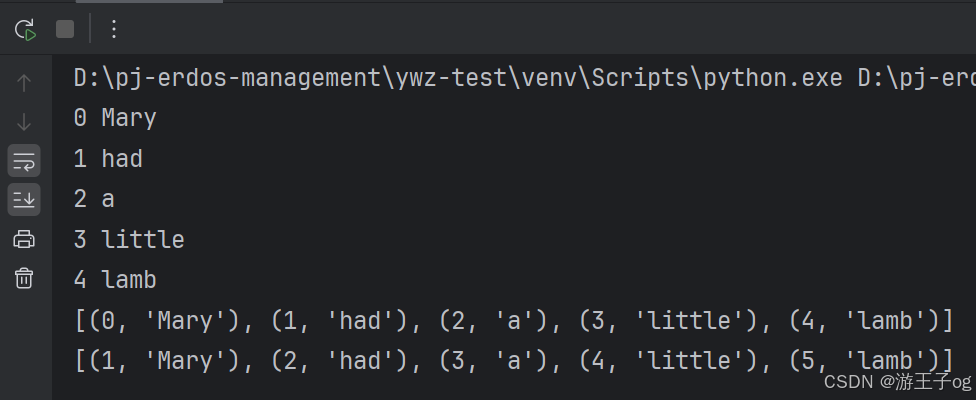
range() 返回的对象在很多方面和列表的行为一样,但其实它和列表不一样。该对象只有在被迭代时才一个一个地返回所期望的列表项,并没有真正生成过一个含有全部项的列表,从而节省了空间。这种对象称为可迭代对象 iterable,适合作为需要获取一系列值的函数或程序构件的参数。for 语句就是这样的程序构件;以可迭代对象作为参数的函数例如 sum():
# 1+2+3 ... + 10 结果为45
print(sum(range(10)))之后我们会看到更多返回可迭代对象,或以可迭代对象作为参数的函数。
2.3 break 和 continue
break break语句将跳出最近的一层 for 或 while 循环,continue 语句将继续执行循环的下一次迭代:
for n in range(2, 10):for x in range(2, n):if n % x == 0:print(f"{n} == {x} * {n//x}")breakfor num in range(2, 10):if num % 2 == 0:print(f"找到一个偶数 {num}")continueprint(f"找到一个奇数 {num}")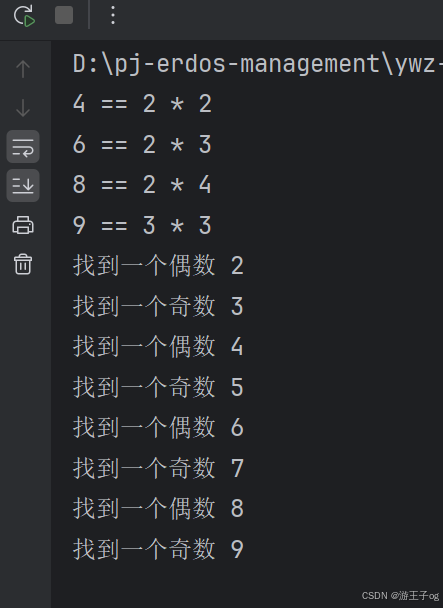
2.4 循环的 else 子句
在 for 或 while 循环中 break 语句可能对应一个 else 子句。 如果循环在未执行 break 的情况下结束,else 子句将会执行。在 for 循环中,else 子句会在循环结束其他最后一次迭代之后,即未执行 break 的情况下被执行。在 while 循环中,它会在循环条件变为假值后执行。在这两类循环中,当在循环被 break 终结时 else 子句 不会 被执行。 当然,其他提前结束循环的方式,如 return 或是引发异常,也会跳过 else 子句的执行。下面的搜索质数的 for 循环就是一个例子:
for n in range(2, 10):for x in range(2, n):if n % x == 0:print(n, '==', x, '*', n//x)breakelse:# 循环到底未找到一个因数print(n, '是个质数')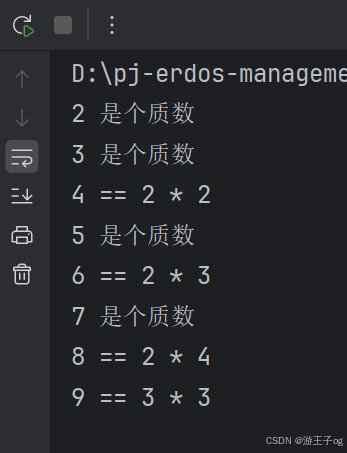
仔细看:其中 else 子句属于 for 循环,而 不属于 if 语句。分析 else 子句的一种方式是想象它对应于循环内的 if。 当循环执行时,它将运行一系列的 if/if/if/else。 if 位于循环内部,会出现多次。 当出现条件为真的情况时,将发生 break。 如果条件一直不为真,则循环外的 else 子句将被执行。
当配合循环使用时,else 子句更像是 try 语句的 else 子句而不像 if 语句的相应子句:一个 try 语句的 else 子句会在未发生异常时运行,而一个循环的 else 子句会在未发生 break 时运行。
3 pass
pass语句不执行任何动作。语法上需要一个语句,但程序毋需执行任何动作时,可以使用该语句。 这常用于创建一个最小的类,还可用作函数或条件语句体的占位符,让你保持在更抽象的层次进行思考。pass 会被默默地忽略:
class MyEmptyClass:passdef initlog(*args):pass # 记得实现这个!4 match
4.1 基本用法
match 语句接受一个表达式并把它的值与一个或多个 case 块给出的一系列模式进行比较。这表面上像 C、Java 或 JavaScript(以及许多其他程序设计语言)中的 switch 语句,但其实它更像 Rust 或 Haskell 中的模式匹配。只有第一个匹配的模式会被执行,并且它还可以提取值的组成部分(序列的元素或对象的属性)赋给变量。最简单的形式是将一个主语值与一个或多个字面值进行比较:
# 定义函数
def http_error(status):match status:case 400:return "Bad request"case 404:return "Not found"case _:return "互联网有点问题"print(http_error(400))
print(http_error(403))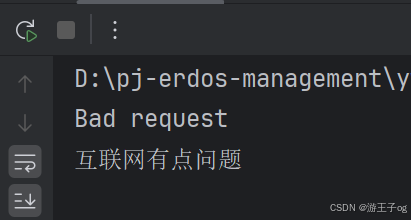
注意最后一个代码块:当没有其他case 匹配成功时,“变量名” _ 被作为 通配符 并必定会匹配成功。你可以用 | (“或”)将多个字面值组合到一个模式中:
case 401 | 403 | 404:return "Not allowed"4.2 映射模式
形如解包赋值的模式可被用于绑定变量,如果用类组织数据,可以用“类名后接一个参数列表”这种很像构造器的形式,把属性捕获到变量里:
class Point:def __init__(self, x, y):self.x = xself.y = ydef where_is(point):match point:case Point(x=0, y=0):print("原点")case Point(x=0, y=y):print(f"Y={y}")case Point(x=x, y=0):print(f"X={x}")case _:print("其他")where_is(Point(0, 0))
where_is(Point(10,0))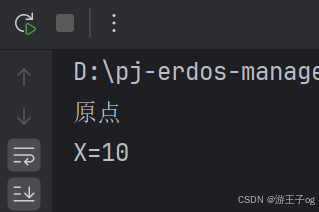
4.3 序列模式
一些内置类(如 dataclass)为属性提供了一个顺序,此时,可以使用位置参数。自定义类可通过在类中设置特殊属性 __match_args__,为属性指定其在模式中对应的位置。若设为 ("x", "y"),则以下模式相互等价(且都把属性 y 绑定到变量 var):
Point(1, var)
Point(1, y=var)
Point(x=1, y=var)
Point(y=var, x=1) 通过将其视为赋值语句等号左边的一种扩展形式,来理解各个变量被设为何值。match 语句只会为单一的名称(如上面的 var)赋值,而不会赋值给带点号的名称(如 foo.bar)、属性名(如上面的 x= 和 y=)和类名(是通过其后的 "(...)" 来识别的,如上面的 Point)。模式可以任意嵌套。举例来说,如果我们有一个由 Point 组成的列表,且 Point 添加了 __match_args__ 时,我们可以这样来匹配它:
class Point:__match_args__ = ('x', 'y')def __init__(self, x, y):self.x = xself.y = ydef where_is(points):match points:case []:print("No points")case [Point(0, 0)]:print("原点")case [Point(x, y)]:print(f"单点 {x}, {y}")case [Point(0, y1), Point(0, y2)]:print(f"两个在Y轴上 {y1}, {y2}")case _:print("其他的事物")where_is([])
where_is([Point(0, 1), Point(0, 2)])
我们可以为模式添加 if 作为守卫子句。如果守卫子句的值为假,那么 match 会继续尝试匹配下一个 case 块。注意是先将值捕获,再对守卫子句求值:
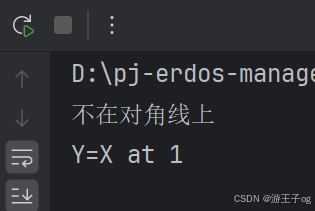
class Point:__match_args__ = ('x', 'y')def __init__(self, x, y):self.x = xself.y = ydef where_is(point):match point:case Point(x, y) if x == y:print(f"Y=X at {x}")case Point(x, y):print(f"不在对角线上")where_is(Point(1, 2))
where_is(Point(1, 1))
该语句的一些其它关键特性:
-
与解包赋值类似,元组和列表模式具有完全相同的含义并且实际上都能匹配任意序列,区别是它们不能匹配迭代器或字符串。
-
序列模式支持扩展解包:
[x, y, *rest]和(x, y, *rest)和相应的解包赋值做的事是一样的。接在*后的名称也可以为_,所以(x, y, *_)匹配含至少两项的序列,而不必绑定剩余的项。
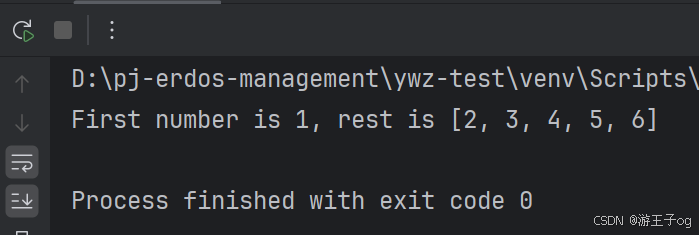
ints = [1, 2, 3, 4, 5, 6]match ints:case [1, 2]:print("只有1,2的列表")case [1, *rest]:print("First number is 1, rest is", rest)
-
映射模式:
{"bandwidth": b, "latency": l}从字典中捕获"bandwidth"和"latency"的值。额外的键会被忽略。
-
使用
as关键字可以捕获子模式:case (Point(x1, y1), Point(x2, y2) as p2): ... 将把输入中的第二个元素捕获为p2(只要输入是包含两个点的序列) -
大多数字面值是按相等性比较的,但是单例对象
True、False和None则是按 id 比较的。
4.4 具名常量(枚举)
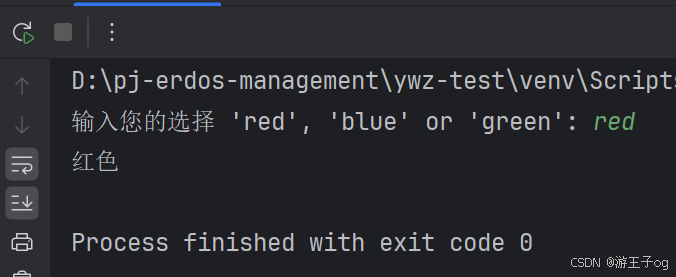
模式可以使用具名常量。它们必须作为带点号的名称出现,以防止它们被解释为用于捕获的变量:
from enum import Enumclass Color(Enum):RED = 'red'GREEN = 'green'BLUE = 'blue'color = Color(input("输入您的选择 'red', 'blue' or 'green': "))match color:case Color.RED:print("红色")case Color.GREEN:print("绿的")case Color.BLUE:print("蓝色")