
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
import torchvision.datasets as datasets
import torchvision.transforms as transformsimport matplotlib.pyplot as pltfrom model import LeNetdef test_data_process():# 数据处理transform = transforms.Compose([transforms.Resize(28), transforms.ToTensor()])# 测试数据集test_dataset = datasets.FashionMNIST(root="./data",train=False, # 是否作为训练集download=True, # 是否需要下载transform=transform) # 怎么做变化# 数据集的加载test_loader = torch.utils.data.DataLoader(test_dataset, batch_size=1, shuffle=True, num_workers=0)return test_loaderdef model_test(model, test_loader):# 指定设备device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")# 模型放置在设备中,在返回给模型model = model.to(device)# 初始化参数test_corrects = 0.0 # 测试一个样本,总计多少个样本是正确的test_num = 0 # 累计测试样例的数量with torch.no_grad():# 模型设置为验证模式model.eval()for batch_size, (images, labels) in enumerate(test_loader):if batch_size % 1000:print("Batch size is {}".format(batch_size))print("images shape: {}".format(images.shape))print("labels shape: {}".format(labels.item()))# 将数据和标签放置在设备中images, labels = images.to(device), labels.to(device)# 将数据放置在模型中进行前向传播output = model(images)# 从输出结果中获取最大值pred_label = output.argmax(dim=1)# 累计测试集中的正样本数test_corrects += torch.sum(pred_label == labels)# 更新模型训练了多少数据test_num += images.size(0)# 计算准确率test_accuracy = test_corrects.double().item() / test_numreturn test_accuracydef show_image(tensor):plt.imshow(tensor.squeeze().numpy(), cmap='gray')plt.show()假定数据集有6万张图片,并且都是彩色图片
test_dataset = datasets.FashionMNIST(root="./data",
train=False, # 是否作为训练集
download=True, # 是否需要下载
transform=transform) # 怎么做变化test_loader = torch.utils.data.DataLoader(test_dataset, batch_size=64, shuffle=True, num_workers=0)
你使用 DataLoader 来加载数据集,并设置了 batch_size=64 和 shuffle=True。这意味着:
- Batch Size: 每个批次包含 64 张图片。
- Shuffle: 在每个 epoch 开始时,数据会被打乱。
- Num Workers: 设置为 0,意味着数据加载将在主进程中进行(而不是使用额外的进程)。
你有 60,000 张图片,那么总共有:
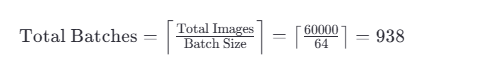
6万张图片,每64张为一捆数据。共计938捆,最后一捆不足64张。
with torch.no_grad():# 模型设置为验证模式model.eval()for batch_index, (images, labels) in enumerate(test_loader):- with torch.no_grad():表示如下的代码不要梯度
for batch_index, (images, labels) in enumerate(test_loader):- batch_index是从第0捆,一直会遍历到第938捆数据。
- 第0捆中,
- images的和标签的尺寸分别是:
images shape: torch.Size([64, 3, 28, 28])
labels shape: torch.Size([64])
[64, 3, 28, 28]表示有64张图片,每张图片有RGB,3个通道;图像的宽和高分别是28*28;
获取第3张图像
image_tensor = images[2]
print("图片的格式:{}".format(image_tensor.shape))图片的格式:torch.Size([3, 28, 28])
获取第3张图像的标签
third_image_label = labels[2].item()labels[2]是一个张量,item()之后才能获取到张量中的值。
显示一张图片
image_tensor = images[3] # [1, 3, 28, 28]plt.imshow(image_tensor.squeeze().numpy(), cmap='gray')
plt.show()如果图片是3通道的
import matplotlib.pyplot as plt# 创建一个形状为 [1, 3, 28, 28] 的张量
tensor = torch.randn(1, 3, 28, 28)# 使用 squeeze() 移除所有长度为1的维度
squeezed_tensor = tensor.squeeze()# 将张量转换为 NumPy 数组
numpy_array = squeezed_tensor.numpy()# 显示图像
plt.imshow(numpy_array.transpose(1, 2, 0)) # 需要调整通道顺序以适应 Matplotlib
plt.show()如果图片是单通道的
import matplotlib.pyplot as plt# 创建一个形状为 [1, 1, 28, 28] 的张量
tensor = torch.randn(1, 1, 28, 28)# 使用 squeeze() 移除所有长度为1的维度
squeezed_tensor = tensor.squeeze()# 将张量转换为 NumPy 数组
numpy_array = squeezed_tensor.numpy()# 显示图像
plt.imshow(numpy_array, cmap='gray')
plt.show()











