
搭建Transformer
- 0 前言
- 1 基本组件
- 1.1 多头注意力机制(MultiHeadedAttention)
- 1.1.1 代码
- 1.1.2 QKV注意力机制理解
- 1.1.3 缩放的理解(除以 d k \sqrt{d_k} dk)
- 1.1.4 多头理解
- 1.2 层归一化(LayerNorm)
- 1.2.1 代码
- 1.2.2 理解
- 1.3 嵌入层(Embeddings)
- 1.4 位置编码(Positional Encoding)
- 1.4.1 位置编码意义
- 1.4.2 位置编码的公式
- 1.4.3 代码
- 1.4.4 位置编码公式理解
- 2 部件
- 2.1 前馈网络(PositionwiseFeedForward)
- 2.1.1 代码
- 2.1.2 理解
- 2.2 编码器子层(EncoderLayer)
- 2.2.1 代码
- 2.3 编码器(Encoder)
- 2.3.1 代码
- 2.4 解码子层(DecodeLayer)
- 2.4.1 代码
- 2.4.2 理解
- 2.5 解码器(Decoder)
- 2.5.1 代码
- 2.6 生成器(Generation)
- 2.6.1 代码
- 2.6.2 理解
- 3 整体结构
- 3.1 零部件整合
- 3.2 模型制作函数
- 3.3 mask函数与mask机制
- 4 中间过程分析
- 4.1 测试代码
- 4.2 通过debug查看encoder和decoder的行为
- 4.2.1 EncoderLayer 中的 mask
- 4.2.2 Decoder的输入
- 4.2.3 Decoder中的自注意力机制
- 4.2.4 Decoder中的交叉注意力机制输入张量的维度
- 4.2.5 Decoder中的重复计算问题
- 5 总结
0 前言
上一篇文章我们介绍了Transfomer中涉及到的相关知识,主要是注意力机制,有了上一篇文章的基础以后,我们就可以来手动搭建 transformer 了,我们边写代码边讲解。本文的代码参考借鉴了哈佛大学的 《The Annotated Transformer》,但更加容易理解。
1 基本组件
我们讲各种组件时,先将相关的程序包导入:
import math
import torch
import torch.nn as nn
from torch.nn.functional import log_softmax
1.1 多头注意力机制(MultiHeadedAttention)
1.1.1 代码
class MultiHeadedAttention(nn.Module):def __init__(self, h, d_model, dropout=0.1):""":param h: 注意力的头数:param d_model: 模型的隐藏层维度,也是词嵌入向量的维度数:param dropout:"""super(MultiHeadedAttention, self).__init__()assert d_model % h == 0 # 确保 d_model 是 h 的整数倍self.d_k = d_model // h # 每个注意力头分到的向量维度self.h = hself.lin_Q = nn.Linear(d_model, d_model)self.lin_K = nn.Linear(d_model, d_model)self.lin_V = nn.Linear(d_model, d_model)self.lin_out = nn.Linear(d_model, d_model)self.attn = Noneself.dropout = nn.Dropout(p=dropout)def forward(self, query, key, value, mask=None):"""Args:query:维度为 (batch_size, seq_len, d_model)key:维度为 (batch_size, seq_len, d_model)value:维度为 (batch_size, seq_len, d_model)mask:维度为 (1, 1, seq_len) 或 (batch_size, seq_len, seq_len)Returns:"""if mask is not None:# 给mask添加一个维度,使其能在多头的矩阵中应用mask = mask.unsqueeze(1)# 获取batch_sizenbatches = query.size(0)# 对query、key、value进行线性变换,这里的线性变换不改变维度query, key, value = self.lin_Q(query), self.lin_K(key), self.lin_V(value)# 在自注意力机制中,传入的query, key, value 都是 x,这三个线性变换可以理解为解耦,使QKV有各自的参数# 在交叉注意力机制中,传入的query是y,key和value都是x,同样可以理解为解耦# 对query进行维度操作,将输入的向量映射到多头注意力机制中的不同子空间query = query.reshape(nbatches, -1, self.h, self.d_k).permute(0, 2, 1, 3)# query经过reshape后变为 (batch_size, seq_len, h, d_k),其中h表示头数,d_k表示每个头分到的向量维度# 经过permute维度重排后,query的维度变为 (batch_size, h, seq_len, d_k)# 假设query原来是 (4, 20, 512),那么第i句话、第j个词的输入就是一个维度为 (512, )的向量# 假设有8个注意力头,在query经过reshape后,该向量变成了(8, 64),这样就将输入的向量分散到了多头注意力机制中的不同子空间# 对key、value进行相同操作key = key.reshape(nbatches, -1, self.h, self.d_k).permute(0, 2, 1, 3)value = value.reshape(nbatches, -1, self.h, self.d_k).permute(0, 2, 1, 3)# 计算注意力x, self.attn = attention(query, key, value, mask, self.dropout)# 调整维度x = x.transpose(1, 2).contiguous().view(nbatches, -1, self.h * self.d_k)# 删除中间变量,节约内存/显存del querydel keydel valuereturn self.lin_out(x)
上面出现了一个名为attention的函数,其代码如下:
def attention(query, key, value, mask=None, dropout=None):"""注意力机制计算:param query: 维度为 (batch_size, h, seq_len, d_k):param key: 维度为 (batch_size, h, seq_len, d_k):param value: 维度为 (batch_size, h, seq_len, d_k):param mask: 维度为 (1, 1, 1, seq_len) 或 (batch_size, 1, seq_len, seq_len):param dropout: 传入的是nn.Dropout对象:return:"""# 获取每个注意力头的维度d_k = query.size(-1)# 计算对齐分数scores = torch.matmul(query, key.permute(0, 1, 3, 2)) / math.sqrt(d_k) # 通过缩放使scores的方差和query一致# query的维度为(batch_size, h, seq_len, d_k),key.permute(0, 1, 3, 2)后的维度为 (batch_size, h, d_k, seq_len)# 通过matmul计算对齐分数,即query和key的点乘,得到的维度为(batch_size, h, seq_len, seq_len)if mask is not None:# 将mask为0的地方置为-1e9,-1e9相当于负无穷大,为的是softmax后的值都为0scores = scores.masked_fill(mask == 0, -1e9) # 将mask为0的地方掩盖掉# 计算注意力权重p_attn = scores.softmax(dim=-1) # (batch_size, h, seq_len, seq_len)if dropout is not None:p_attn = dropout(p_attn)# 对value中的行向量进行加权,获得上下文向量m = torch.matmul(p_attn, value) # (batch_size, h, seq_len, d_k)return m, p_attn
可以看到,transformer 中用到的注意力机制,不但是多头注意力机制,还是缩放点乘注意力机制,同时还是QKV注意力机制,但未必是自注意力机制,因为在解码器中,有可能是交叉注意力机制,这个后面会说。至于 mask,后面会讨论。
为了方便理解计算过程,上面代码的注释中,关于输入张量的维度都是基于自注意力机制的,交叉注意力机制计算时,query 和 key、value 的维度不一样,这个后面回介绍,只要理解了自注意力机制的计算过程,交叉注意力机制也能理解。
1.1.2 QKV注意力机制理解
这里的QKV注意力机制,和我们上篇文章中介绍的Key-Value注意力机制是类似的,key用于计算注意力权重,value用于计算上下文向量m(这里输出的是上下文向量m,后面都是用m来做预测,value只用了一次,也就是说,这里value只有一个功能,不需要再解耦出 Predict 来,我猜测这就是 transformer 用 Key-Value 而非 KVP 的愿意)。
这里相对于《FRUSTRATINGLY SHORT ATTENTION SPANS IN NEURAL LANGUAGE MODELING》中的 Key-Value 注意力机制,还增加了一个Query,因为Transformer 最开始是用于机器翻译,在解码过程中需要做交叉注意力机制,此时 Key 和 Query 将分别来自于输入序列和预测序列,此时代码torch.matmul(query, key.permute(0, 1, 3, 2)) / math.sqrt(d_k)发挥的作用是计算 Query 中每个词与 Key 中每个单词的注意力得分(对齐分数)。《FRUSTRATINGLY SHORT ATTENTION SPANS IN NEURAL LANGUAGE MODELING》中的 Key-Value 注意力机制用在了LSTM模型,不是 Encoder-Decoder 结构,所以原始的 Key-Value 注意力机制不需要 Query。
可以这么认为,QKV注意力机制,是 Encoder-Decoder 版本的 Key-Value 注意力机制。
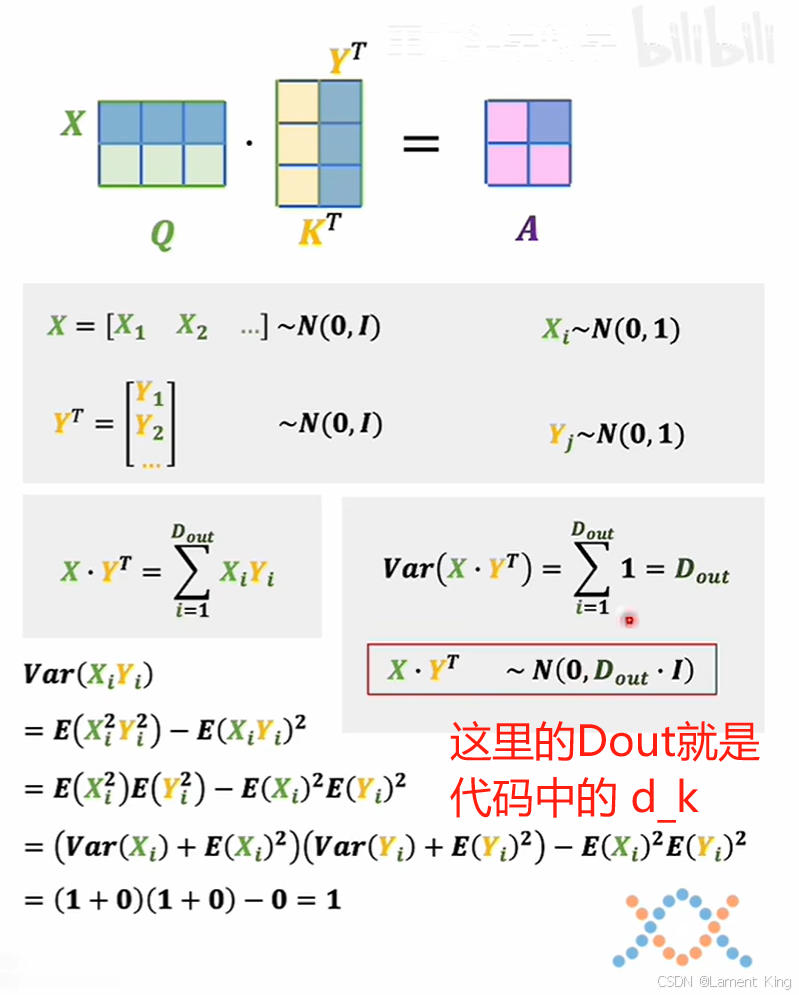
1.1.3 缩放的理解(除以 d k \sqrt{d_k} dk)
代码scores = torch.matmul(query, key.permute(0, 1, 3, 2)) / math.sqrt(d_k)最后还除了 d k \sqrt{d_k} dk,那是因为这里假设query和Key的每行都服从标准正态分布,那么它们点乘之后的方差将变成 d k d_k dk,为了让计算得到的分布依然服从标准正态分布,所以需要除以 d k \sqrt{d_k} dk。
下图中的方差计算可以证明这一点(图像来自于B站up主:王木头学科学的相关视频):
1.1.4 多头理解
论文《A structured self-attentive sentence embedding》中提到,多头注意力机制获得的句子嵌入矩阵,应该和句子的长度无关,但这里获得的句子嵌入矩阵的维度却是 (batch_size, h, seq_len, d_k),除去 batch_size 和 h,句子嵌入也是(seq_len, d_k),这是什么原因呢?
如果按照《A structured self-attentive sentence embedding》的观点,代码torch.matmul(query, key.permute(0, 1, 3, 2))中,注意力机制的头数不是h,而是 seq_len,因为 query 的后两个维度为(seq_len, d_k),对应原论文的 W s 2 W_{s2} Ws2,行数等于注意力机制的头数,而 query 的行数正是 seq_len。但是,在这 seq_len 个“注意力头”中,每个“头”只能看到词向量的一部分(d_k个维度),只有这 seq_len 个“头”一起使用,才能看到词向量的所有维度(d_model)。所以,应该按照“能完整看到整个词向量的次数”作为注意力机制的头数,seq_len 个“头”能看到一次完整的,它们合在一起才能算一个真正的注意力头,而 query 的维度为(batch_size, h, seq_len, d_k),去掉最前面的 batch_size (我们只讨论单个句子),能对每个单词的所有词向量完整地看 h 次,所以注意力机制的头数为 h。这样设计,也方便随后对 scores 做 mask,因为 mask 只能是 (seq_len, seq_len),要让 scores 的维度和 mask 一样。
函数attention的输出张量维度为 (batch_size, h, seq_len, d_k),对比CNN中的VGG、AlexNet、ResNet等网络,它们提取的特征图的维度为 (batch_size, c, h, w),第二个维度是通道,所以这里的多头,可以理解为多通道。
1.2 层归一化(LayerNorm)
1.2.1 代码
class LayerNorm(nn.Module):def __init__(self, features, eps=1e-6):"""层归一化:param features: d_model:param eps:"""super(LayerNorm, self).__init__()self.a_2 = nn.Parameter(torch.ones(features)) # 对a_2层参数用1初始化self.b_2 = nn.Parameter(torch.zeros(features)) # 对b_2层参数用0初始化self.eps = epsdef forward(self, x):""":param x: 维度为(batch_size, seq_len, d_model):return:"""mean = x.mean(-1, keepdim=True) # 对每行求均值# mean 的维度是 (batch_size, seq_len, 1),mean[i, j] 是 x[i, j, :]的均值# 也就是说,这里是对 x 的每句话、每个单词的词向量单独求均值# x 有 batch_size 句话,每句话有 seq_len 个单词,所以 mean 共有 batch_size X seq_len 个均值std = x.std(-1, keepdim=True) # 对每行求标准差# 将每行先转化为均值0、标准差1的分布,然后再转成均值b_2、标准差a_2的分布return self.a_2 * (x - mean) / (std + self.eps) + self.b_2# mean和std的维度都是(batch_size, seq_len, 1), # x的维度为(batch_size, seq_len, d_model),# a_2 和 b_2 的维度都是 (d_model, ),因此可以广播
1.2.2 理解
所谓层归一化,它其实就是对词向量的每个维度进行归一化,下图是BN(Batch Norm)和LN(Layer Norm)的对比示意图(图片来源:BatchNorm & LayerNorm,Un-Defined):
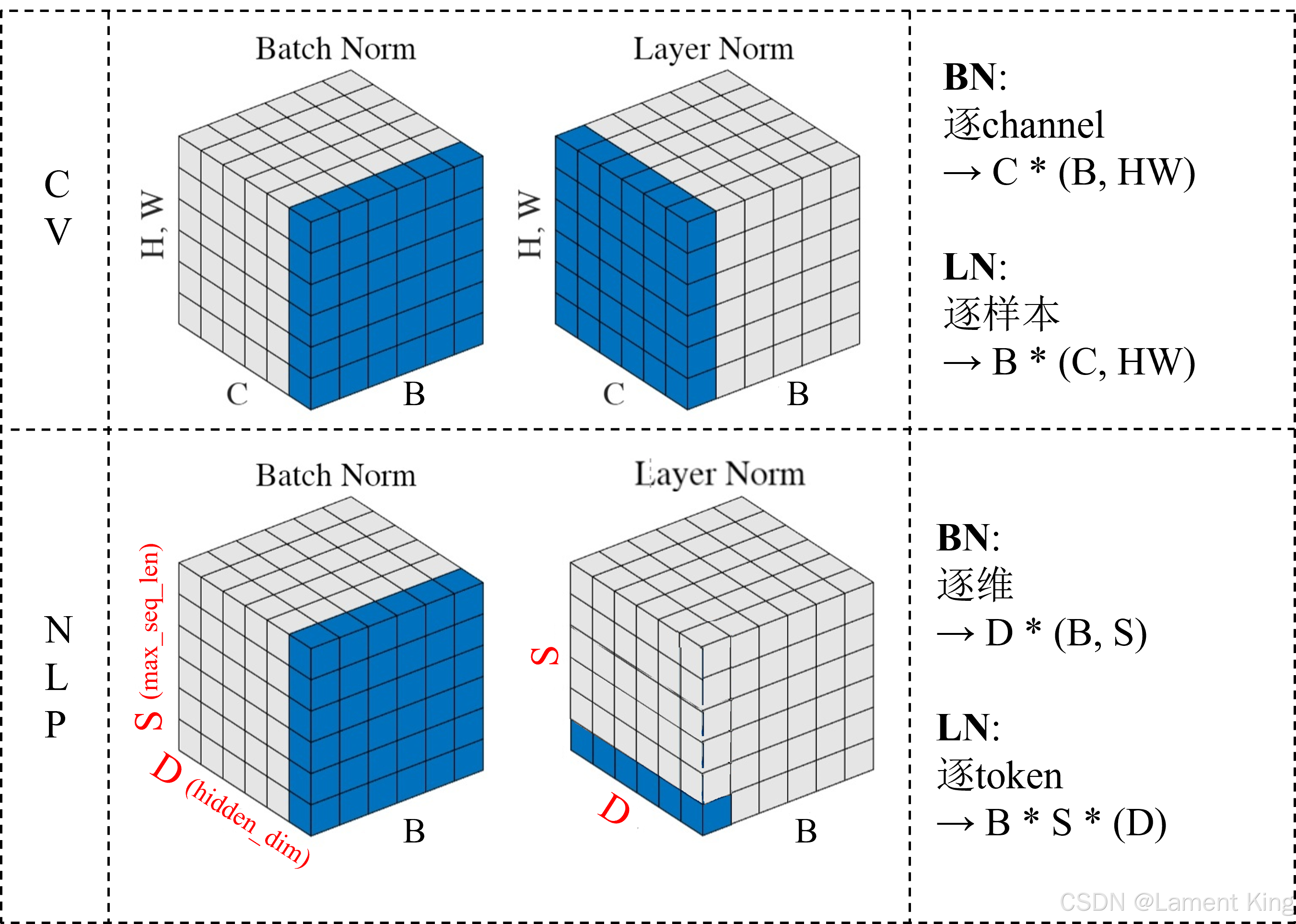
图中蓝色部分表示每个均值和标准差的计算范围,图中右边公式的含义,比如LN:B * S * (D),表示最后得到的均值(或标准差)的维度为B * S 或B * S * 1,括号(D)表示计算范围。
PyTorch中也集成了LayerNorm操作,可以通过接口LN = torch.nn.LayerNorm(embedding_dim)定义LN对象,然后通过LN(x)调用。
1.3 嵌入层(Embeddings)
1.3.1 代码
class Embeddings(nn.Module):def __init__(self, d_model, vocab):"""Args:d_model: 模型隐藏层维度vocab: 词表大小"""super(Embeddings, self).__init__()self.lut = nn.Embedding(vocab, d_model)self.d_model = d_modeldef forward(self, x):""":param x: 输入向量,已转化为单词在词汇表中的索引,维度为 (batch_size, seq_len),seq_len是句子长度:return: 词向量,维度为 (batch_size, seq_len, d_model)"""result = self.lut(x) * math.sqrt(self.d_model)# 词向量乘以sqrt(d_model),用于调整标准差,使得sum(result)的标准差与词向量一致return result
1.3.2 缩放理解(除以 d m o d e l \sqrt{d_{model}} dmodel)
从代码中可以看到,这里并没有使用预训练词嵌入,而是让其在训练过程中进行学习。
在前向传播的时候,result = self.lut(x) * math.sqrt(self.d_model),获得词向量之后还除了 d m o d e l \sqrt{d_{model}} dmodel,跟前面介绍多头注意力机制一样,为的是调整方差。
1.4 位置编码(Positional Encoding)
1.4.1 位置编码意义
上一篇文章中介绍的注意力机制,它们的操作对象 [ h 1 , h 2 , . . . , h n ] [h_1, h_2, ... , h_n] [h1,h2,...,hn] 都是 RNN/LSTM 的输出结果,这些个 h h h 带有浓厚的序列信息, h t h_{t} ht 都是由 h t − 1 h_{t-1} ht−1 计算得到,也就是说, h h h 中的数值能体现单词之间的先后关系。而 transformer 中没有 RNN/LSTM 这样的序列模型,如果没有位置编码的话,它将直接对词嵌入向量进行操作,而这些词嵌入向量的数值,无法体现内部之间的先后关系,因此需要在词向量中加入能体现相对位置关系的内容,这就是位置编码。也就是说,让“词嵌入+位置编码”替代 h h h。当然,以上是我的个人理解,未必正确。
有人会说,注意力机制的输入也是由每个位置的词嵌入拼接而成,第一个单词的词向量在第一行,第二个单词在第二行,它们的相对关系已经体现了位置信息了,为什么还要在词向量数值中添加?我个人理解是, [ h 1 , h 2 , . . . , h n ] [h_1, h_2, ... , h_n] [h1,h2,...,hn] 相对于 [ w 1 , w 2 , . . . , w n ] [w_1, w_2, ... , w_n] [w1,w2,...,wn] 更具有整体性,内部的相对关系更强,更有利于注意力机制的计算。
如果不在数值中添加位置信息,仅凭词向量之间的相对关系,那么会发生什么呢?以Bahdanau Attention为例,对齐分数为: e t j = v T t a n h ( W a s t − 1 + U a h j ) e_{tj}=v^Ttanh(W_as_{t-1}+U_ah_j) etj=vTtanh(Wast−1+Uahj),这里 s t − 1 s_{t-1} st−1 是 decoder 第 t-1 个位置的隐藏层输出, h j h_j hj 是 encoder 第 j 个位置的隐藏层输出。如果是仅凭词向量的相对关系来确定对齐分数,那么相当于把对齐分数中,encoder 和 decoder 的隐藏层输出改成词嵌入向量,即 e t j = v T t a n h ( W a w t − 1 d e c o d e r + U a w j e n c o d e r ) e_{tj}=v^Ttanh(W_aw^{decoder}_{t-1}+U_aw^{encoder}_j) etj=vTtanh(Wawt−1decoder+Uawjencoder),这就是对源语言与目标语言的两个单词强行硬算注意力机制了。
1.4.2 位置编码的公式
在 Transformer 中,位置编码 P E ( p o s , i ) PE(pos, i) PE(pos,i) 的公式如下:
P E ( p o s , 2 i ) = sin ( p o s 1000 0 2 i d model ) P E ( p o s , 2 i + 1 ) = cos ( p o s 1000 0 2 i d model ) \begin{aligned} PE(pos, 2i) & = \sin\left(\frac{pos}{10000^{\frac{2i}{d_{\text{model}}}}}\right) \\ PE(pos, 2i+1) & = \cos\left(\frac{pos}{10000^{\frac{2i}{d_{\text{model}}}}}\right) \end{aligned} PE(pos,2i)PE(pos,2i+1)=sin(10000dmodel2ipos)=cos(10000dmodel2ipos)
pos:token 在序列中的位置索引(从 0 开始)
1.4.3 代码
class PositionalEncoding(nn.Module):def __init__(self, d_model, dropout, max_len=5000):""":param d_model: 词嵌入向量的长度:param dropout: 随机失活概率:param max_len: 句子长度"""super(PositionalEncoding, self).__init__()self.dropout = nn.Dropout(p=dropout)"""计算位置编码"""# 用0初始化pe = torch.zeros(max_len, d_model)"""通过两层循环计算,方便理解,实际应用中,是通过矩阵计算完成,速度更快"""for pos in range(max_len):for i in range(0, d_model, 2):pe[pos, i] = math.sin(pos / (10000 ** (i/d_model)))pe[pos, i + 1] = math.cos(pos / (10000 ** (i/d_model)))# 偶数和随后的奇数,三角函数中的分母是相同的# 增加一个batch_size维度pe = pe.unsqueeze(0)# 将pe设置为常数self.register_buffer("pe", pe)def forward(self, x):"""x的shape为 (batch_size, seq_len, d_model),seq_len是句子长度"""x = x + self.pe[:, : x.size(1)].requires_grad_(False)# 因为 self.pe 的维度为(1, 5000, 512),5000是能容纳的最大句子长度# 这里 self.pe[:, : x.size(1)] 是根据实际句子长度来获取对应的 pereturn self.dropout(x)
1.4.4 位置编码公式理解
从单词的位置层面来看,位置编码为每个单词的每个词向量维度提供的是绝对的位置信息,经过位置编码处理后,pe[0, 1, 3]和pe[0, 2, 3]虽然同是词向量的第3个维度,但因为所处的单词不一样,所以它们的值也就不一样。但由于正弦和余弦函数的性质,任意两个位置(同一个d_model维度)的编码可以通过线性变换相互表示,这意味着模型可以隐式地学习到单词之间的相对位置关系,而无需显式地编码距离。
从词向量维度层面看,每次输入模型的不是单个词向量,而是多个,每个词向量维度都是一个序列,每个序列的变化速度不同,因此模型可以捕捉到不同的周期信息。位置编码在不同的词向量维度上有不同的波长信息,不同维度的周期性特性可以看作是对位置信息的一种“分解”,这种设计使得不同维度对应不同的周期性模式。
以下是直观理解:
- 公式中的分母 1000 0 2 i d model 10000^{\frac{2i}{d_{\text{model}}}} 10000dmodel2i 决定了每个维度的波长。
- 对于较小的 i i i,波长较长(变化缓慢);对于较大的 i i i,波长较短(变化较快)。
- 假设 d model = 8 d_{\text{model}} = 8 dmodel=8,则前几个维度的波长可能是:
- 第 0 维:波长为 1000 0 0 / 4 = 1 10000^{0/4} = 1 100000/4=1(非常长的周期)。
- 第 2 维:波长为 1000 0 2 / 4 = 100 10000^{2/4} = 100 100002/4=100(稍短的周期)。
- 第 6 维:波长为 1000 0 6 / 4 = 10000 10000^{6/4} = 10000 100006/4=10000(非常短的周期)。
通过让不同维度具有不同的周期性特性,模型能够从多个尺度感知序列中的位置关系:
- 低频维度捕捉全局信息:波长较长的维度(如第 0 维、第 2 维)变化较慢,适合捕捉全局范围内的位置关系。
- 高频维度捕捉局部信息:波长较短的维度(如第 6 维、第 7 维)变化较快,适合捕捉局部范围内的位置关系。
- 综合多尺度信息:模型通过自注意力机制结合所有维度的信息,从而同时利用全局和局部的位置关系。
另外,正弦和余弦函数是确定性和连续的,即使在训练时未见过的序列长度上,它们仍然能够提供合理的位置编码
2 部件
2.1 前馈网络(PositionwiseFeedForward)
2.1.1 代码
class PositionwiseFeedForward(nn.Module):def __init__(self, d_model, d_ff, dropout=0.1):"""FFN层:param d_model::param d_ff: 中间向量维度:param dropout:"""super(PositionwiseFeedForward, self).__init__()self.w_1 = nn.Linear(d_model, d_ff)self.w_2 = nn.Linear(d_ff, d_model)self.dropout = nn.Dropout(dropout)def forward(self, x):x = self.w_1(x).relu()x = self.dropout(x)x = self.w_2(x)return x
2.1.2 理解
FFN其实就是两个全连接层相互嵌套,在整个 Transformers 中 FFN 的参数占比大概是 2/3,关于这个模块的作用,目前并不是特别清楚,业内普遍认为 FNN 中存储的是来自训练数据的记忆,Attention 的计算过程是对当前输入的样本进行信息提取。
FFN 的计算过程为: F F N ( x ) = R e L U ( x W 1 + b 1 ) W 2 + b 2 FFN(x) =ReLU(xW_1+b_1)W_2+b2 FFN(x)=ReLU(xW1+b1)W2+b2
它和 Key-Value 记忆网络的计算过程 M e m o r y N e t ( x ) = s o f t m a x ( x K T ) V MemoryNet(x) =softmax(xK^T)V MemoryNet(x)=softmax(xKT)V 很像,都是做两次线性变换,只是激活函数不一样。
所以《Transformer Feed-Forward Layers Are Key-Value Memories》认为,FFN 是一个 Key-Value 记忆网络,第一层线性变换是获取 Key Memory,第二层线性变换是获取 Value Memory,标准 Key-Value 记忆网络用 softmax 进行归一化,而 FFN 则采用 ReLU 进行筛选,本质上都差不多。
2.2 编码器子层(EncoderLayer)
2.2.1 代码
class EncoderLayer(nn.Module):def __init__(self, d_model, dropout, h, d_ff):"""解码器子层:param d_model: 词嵌入维度(模型的隐藏维度):param dropout: Dropout中随机失活的比例:param h: 多头注意力机制中的头数:param d_ff: FFN中中间向量的维度"""super(EncoderLayer, self).__init__()self.self_attn = MultiHeadedAttention(h, d_model, dropout)self.feed_forward = PositionwiseFeedForward(d_model, d_ff, dropout)self.LN_1 = LayerNorm(d_model)self.LN_2 = LayerNorm(d_model)self.dropout1 = nn.Dropout(dropout)self.dropout2 = nn.Dropout(dropout)def forward(self, x, mask):input_x = x.clone()# 先做自注意力机制x = self.LN_1(x)x = self.self_attn(x, x, x, mask)x = self.dropout1(x)x = input_x + xatt_x = x.clone()# 再做FFNx = self.LN_2(x)x = self.feed_forward(x)x = self.dropout2(x)x = att_x + xreturn x
这个没什么好讲的,就是搭积木。
2.3 编码器(Encoder)
2.3.1 代码
class Encoder(nn.Module):def __init__(self, d_model, dropout, h, d_ff):"""编码器:param d_model: 词嵌入维度(模型的隐藏维度):param dropout: Dropout中随机失活的比例:param h: 多头注意力机制中的头数:param d_ff: FFN中中间向量的维度"""super(Encoder, self).__init__()# 带有两个编码器子层self.layer_1 = EncoderLayer(d_model, dropout, h, d_ff)self.layer_2 = EncoderLayer(d_model, dropout, h, d_ff)self.norm = LayerNorm(d_model)def forward(self, x, mask):x = self.layer_1(x, mask)x = self.layer_2(x, mask)x = self.norm(x)return x
标准的 transformer 模型中,encoder有6个 EncoderLayer,我们这里为了缩短运行时间,就设置两个。
2.4 解码子层(DecodeLayer)
2.4.1 代码
class DecoderLayer(nn.Module):def __init__(self, d_model, dropout, h, d_ff):super(DecoderLayer, self).__init__()self.self_attn = MultiHeadedAttention(h, d_model, dropout)self.cross_attn = MultiHeadedAttention(h, d_model, dropout)self.feed_forward = PositionwiseFeedForward(d_model, d_ff, dropout)self.LN_1 = LayerNorm(d_model)self.LN_2 = LayerNorm(d_model)self.LN_3 = LayerNorm(d_model)self.dropout1 = nn.Dropout(dropout)self.dropout2 = nn.Dropout(dropout)self.dropout3 = nn.Dropout(dropout)def forward(self, y, memory, src_mask, tgt_mask):""":param y: 源语言的输入:param memory: 来自encoder的输出:param src_mask: 源语言的 mask,即 encoder 中所使用的 mask:param tgt_mask: 目标语言的 mask:return:"""input_y = y.clone()# 先做自注意力机制y = self.LN_1(y)y = self.self_attn(y, y, y, tgt_mask)y = self.dropout1(y)y = input_y + yatt1_y = y.clone()# 再做交叉注意力机制y = self.LN_2(y)y = self.cross_attn(y, memory, memory, src_mask)y = self.dropout2(y)y = att1_y + yatt2_y = y.clone()# 再做FFNy = self.LN_3(y)y = self.feed_forward(y)y = self.dropout3(y)y = att2_y + yreturn y
2.4.2 理解
这里比 EncoderLayer 稍微复杂一些,因为有两个注意力模块,第一个是对解码器的输入做自注意力,第二个是做交叉注意力,以上一个模块(即自注意力模块)的输出为Q,以编码器的输出为K和V,它是先计算 encoder 中每个词与 decoder 中每个单词的注意力得分(对齐分数),然后归一化获取权重,然后根据权重对V进行加权,获取来自 encoder 输出的上下文向量。
2.5 解码器(Decoder)
2.5.1 代码
class Decoder(nn.Module):def __init__(self, d_model, dropout, h, d_ff):super(Decoder, self).__init__()self.layer_1 = DecoderLayer(d_model, dropout, h, d_ff)self.layer_2 = DecoderLayer(d_model, dropout, h, d_ff)self.norm = LayerNorm(d_model)def forward(self, y, memory, src_mask, tgt_mask):""":param y: 源语言的输入:param memory: 来自encoder的输出:param src_mask: 源语言的 mask,即 encoder 中所使用的 mask:param tgt_mask: 目标语言的 mask:return:"""y = self.layer_1(y, memory, src_mask, tgt_mask)y = self.layer_2(y, memory, src_mask, tgt_mask)return self.norm(y)
2.6 生成器(Generation)
2.6.1 代码
class Generator(nn.Module):"Define standard linear + softmax generation step."def __init__(self, d_model, vocab):super(Generator, self).__init__()self.proj = nn.Linear(d_model, vocab) # 线性层def forward(self, x):return log_softmax(self.proj(x), dim=-1)# log_softmax是torch.nn.functional.log_softmax的指代,# 它是先对输入的向量先做softmax,然后使用log取对数(底数是e)
2.6.2 理解
它是将解码器的输出转化为目标语言的单词概率分布。
3 整体结构
3.1 零部件整合
class EncoderDecoder(nn.Module):def __init__(self, d_model, src_vocab, tgt_vocab, h, d_ff, dropout=0.1):""":param d_model: 词嵌入向量长度:param dropout: 随机失活概率:param src_vocab: 源语言词汇表大小:param tgt_vocab: 目标语言词汇表大小"""super(EncoderDecoder, self).__init__()self.encoder = Encoder(d_model, dropout, h, d_ff)self.decoder = Decoder(d_model, dropout, h, d_ff)self.src_embed = nn.Sequential(Embeddings(d_model, src_vocab), PositionalEncoding(d_model, dropout))self.tgt_embed = nn.Sequential(Embeddings(d_model, tgt_vocab), PositionalEncoding(d_model, dropout))self.generator = Generator(d_model, tgt_vocab)def forward(self, src, tgt, src_mask, tgt_mask):"Take in and process masked src and target sequences."x = self.src_embed(src)memory = self.encoder(x, src_mask)y = self.tgt_embed(tgt)y = self.decoder(y, memory, src_mask, tgt_mask)y = self.generator(y)return ydef encode(self, src, src_mask):"""单独使用编码器"""x = self.src_embed(src)return self.encoder(x, src_mask)def decode(self, memory, src_mask, tgt, tgt_mask):"""单独使用解码器"""y = self.tgt_embed(tgt)return self.decoder(y, memory, src_mask, tgt_mask)
3.2 模型制作函数
def make_model(src_vocab, tgt_vocab, d_model=512, d_ff=2048, h=8, dropout=0.1):"""根据超参数构建模型Args:src_vocab: 源语言词表大小tgt_vocab: 目标语言词表大小N: 编码器和解码器中堆叠的层数,默认为 6 层d_model: 模型隐藏层的维度,它是token经过嵌入后的维度,默认为 512d_ff: 前馈网络(Feed-Forward Network)中的中间层维度大小,默认为 2048。h: 多头注意力机制中注意力头的数量,默认为 8。dropout: Dropout 的比例,用于防止过拟合,默认为 0.1。Returns:"""model = EncoderDecoder(d_model, src_vocab, tgt_vocab, h, d_ff, dropout)# This was important from their code.# Initialize parameters with Glorot / fan_avg.for p in model.parameters():if p.dim() > 1:nn.init.xavier_uniform_(p)return model
3.3 mask函数与mask机制
def subsequent_mask(size):# 生成 mask 的矩阵,用于遮盖未来信息,防止模型看到未来信息# 先生成全为 1 的矩阵ones = torch.ones(1, size, size)# torch.tril 提取矩阵的下三角部分,包括对角线subsequent_mask = torch.tril(ones, diagonal=0).type(torch.uint8)# 将subsequent_mask转化为布尔值mask = subsequent_mask.bool()# 返回布尔值构成的(1, size, size)张量return mask
mask作用的理解要结合前面介绍的 attention 函数(即在多头注意力机制模块中调用的 attention 函数)。
在attention函数中,有(为了方便理解,我去掉了dropout,并重新做了注释):
# 计算对齐分数scores = torch.matmul(query, key.permute(0, 1, 3, 2)) / math.sqrt(d_k) # (batch_size, h, seq_len, seq_len)if mask is not None:# 将mask为0的地方置为-1e9,-1e9相当于负无穷大,为的是softmax后的值都为0scores = scores.masked_fill(mask == 0, -1e9) # (batch_size, h, seq_len, seq_len)# 计算注意力权重(归一化)p_attn = scores.softmax(dim=-1) # (batch_size, h, seq_len, seq_len)# 对value中的行向量进行加权,获得上下文向量m = torch.matmul(p_attn, value) # (batch_size, h, seq_len, d_k)# value[0, 0]是一个 (seq_len, d_k) 矩阵,我们可以理解为,它是由 seq_len 个行向量拼接而成# p_attn[0, 0, 0, :]是一个 (seq_len, ) 维的向量,它对应的是 value[0, 0] 中 seq_len 个行向量的权重# torch.matmul(p_attn[0, 0, 0, :], value[0, 0]) 则是将seq_len 个行向量加权求和# p_attn[0, 0, 0, k] 对应的是向量 value[0, 0, k] 在向量 m[0, 0, 0] 中的权重
它先把 mask 为 0 的部分替换成了负无穷大,随后在计算注意力权重的时候 softmax 函数会把负无穷大转换为0,这样在对 value 进行加权的时候,mask 为0的位置,其对应 value 中指定位置的行向量,在上下文向量 m 中的权重就是 0。
举个例子,若 mask[0, 0, 3, 5] 为 Fasle,那么p_attn[0, 0, 3, 5]为0,则向量 value[0, 0, 5] 在 m[0, 0, 3] 中所占的权重就是0,说人话就是:
第3个单词对第5个单词不进行注意力机制计算(或者说,虽然点乘了,但不纳入考虑)。
至于为什么 subsequent_mask 要生成下三角矩阵,这个需要先知道 decoder 的输入,我们后面会介绍。
4 中间过程分析
4.1 测试代码
def inference_test():# 创建模型test_model = make_model(11, 11, 512)# 为了简便,测试模型中只有两个编码器和两个解码器,源语言词表大小与目标语言的词表大小都为 11# 输入的是数字0-9,共10个词,再加一个填充词(100),所以词表大小为11# 设置评估模式test_model.eval()# 源语言src = torch.LongTensor([[0, 1, 2, 3, 4, 5, 6, 7, 8, 9]])src_mask = torch.ones(1, 1, 10)# 编码memory = test_model.encode(src, src_mask) # memory的维度为(batch_size, seq_len, d_model),它是编码器最后一层的输出# 初始化输出ys = torch.zeros(1, 1).type_as(src)for i in range(9):tgt_mask = subsequent_mask(ys.size(1)).type_as(src.data)out = test_model.decode(memory, src_mask, ys, tgt_mask)prob = test_model.generator(out[:, -1])_, next_word = torch.max(prob, dim=1)next_word = next_word.data[0]ys = torch.cat([ys, torch.empty(1, 1).type_as(src.data).fill_(next_word)], dim=1)print("Example Untrained Model Prediction:", ys)if __name__ == '__main__':inference_test()
从代码中可以看到,模型在创建后,不是直接调用 EncoderDecoder 的 forward 函数,而是调用一次编码器,然后调用若干次解码器,也就是说,这里是编码器解码器单独调用。forward 函数是在训练的时候起作用,正向传播与反向传播都是利用 forward 中的路径,我们会在下一篇文章中介绍。
输出:
Example Untrained Model Prediction: tensor([[0, 7, 7, 7, 7, 7, 7, 7, 7, 7]])
4.2 通过debug查看encoder和decoder的行为
4.2.1 EncoderLayer 中的 mask
我们在EncoderLayer的forward中打断点,如下图所示:
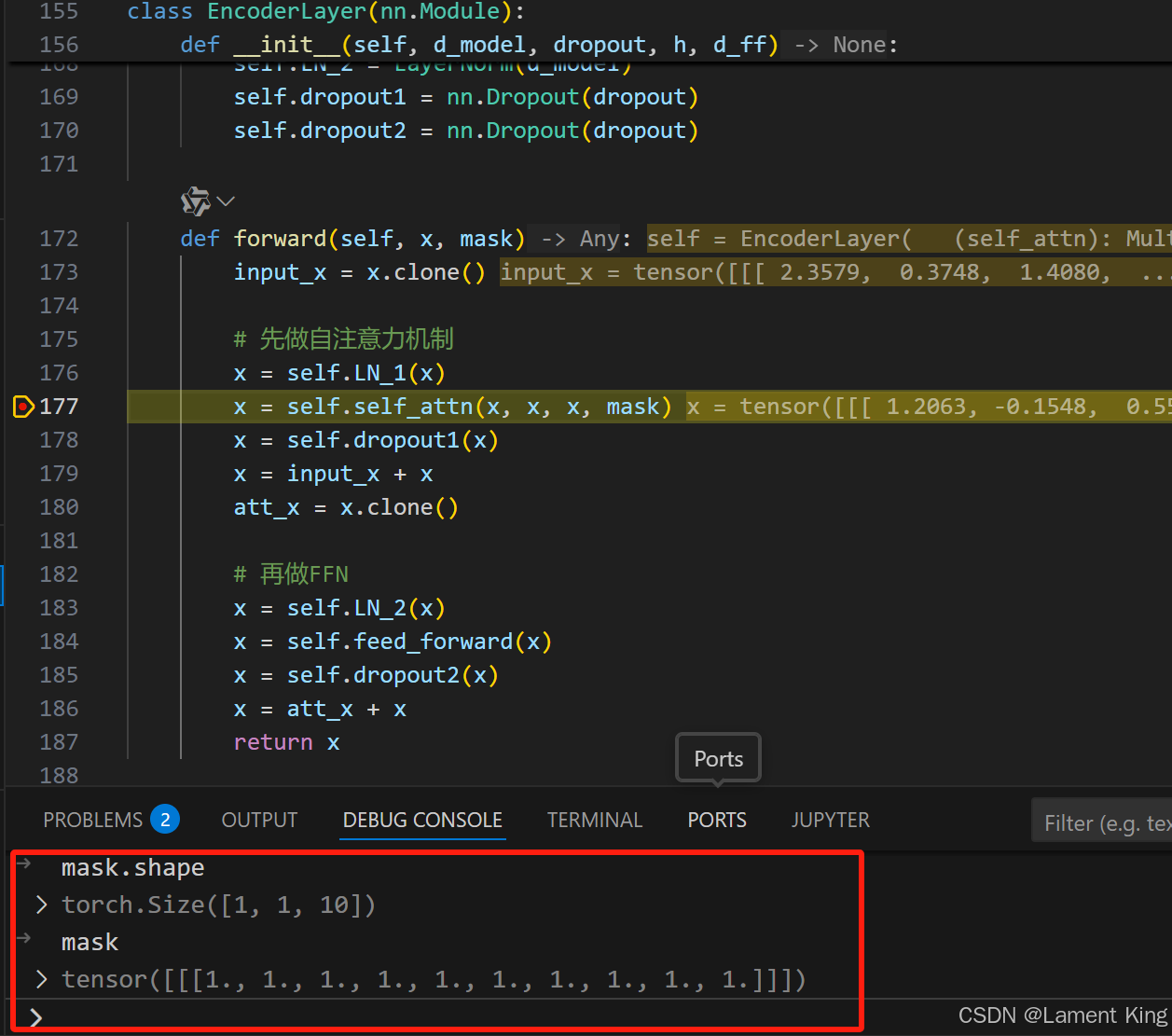
然后查看mask,可以看到,它是一个维度为(1, 1, 10)的张量,且每个元素都是1,也就是说,mask没有起作用。那么是不是意味着,在encoder阶段,就不需要 mask 了呢?
事实并非如此,我们这里的程序是因为只有一个序列,batch_size为1,如果batch_size为4,并且4个序列中的长度不一致,为了对齐,就需要对其中比较短的序列进行填充(假设用100填充)。假设有一条序列为[0, 2, 3, 1],而seq_len为6,那么填充之后为[0, 2, 3, 1, 100, 100],那么对应的mask为:

100所在列为False,意味着任何词对100的注意力(权重)都是0。但是100对其它词的注意力(权重)并不是0,100只有对自己的注意力是0,所以100对应的行,有True有False。
4.2.2 Decoder的输入
decoder的输入由四部分组成,分别是:memory, src_mask, ys, tgt_mask。这里面 memory 是 encoder 的输出,输入到 decoder 中是为了做交叉注意力机制,src_mask 是源语言的 mask,它在 encoder 中使用过一次,输入到 decoder 中,同样是为了做交叉注意力机制(通过src_mask 来确定目标语言同源语言的哪些词做,哪些词不做)。
至于 ys 和 tgt_mask,它主要用来做自注意力机制,稍后会分析。
4.2.3 Decoder中的自注意力机制
分析下面这段代码的打印结果,可以更好的理解 ys 和 tgt_mask:
def print_decoder_input():# 创建模型test_model = make_model(11, 11, 512)# 设置评估模式test_model.eval()# 源语言src = torch.LongTensor([[0, 1, 2, 3, 4, 5, 6, 7, 8, 9]])src_mask = torch.ones(1, 1, 10)# 编码memory = test_model.encode(src, src_mask) # memory的维度为(batch_size, seq_len, d_model),它是编码器最后一层的输出# 初始化输出ys = torch.zeros(1, 1).type_as(src)# 解码for i in range(4):tgt_mask = subsequent_mask(ys.size(1)).type_as(src.data)print('ys:', ys)print('tgt_mask:')print(tgt_mask)out = test_model.decode(memory, src_mask, ys, tgt_mask)prob = test_model.generator(out[:, -1])_, next_word = torch.max(prob, dim=1)next_word = next_word.data[0]ys = torch.cat([ys, torch.empty(1, 1).type_as(src.data).fill_(next_word)], dim=1)print('next_word:', next_word)print('-'*80)print()print("Example Untrained Model Prediction:", ys)if __name__ == '__main__':print_decoder_input()
输出
ys: tensor([[0]])
tgt_mask:
tensor([[[1]]])
next_word: tensor(8)
--------------------------------------------------------------------------------ys: tensor([[0, 8]])
tgt_mask:
tensor([[[1, 0],[1, 1]]])
next_word: tensor(5)
--------------------------------------------------------------------------------ys: tensor([[0, 8, 5]])
tgt_mask:
tensor([[[1, 0, 0],[1, 1, 0],[1, 1, 1]]])
next_word: tensor(6)
--------------------------------------------------------------------------------ys: tensor([[0, 8, 5, 6]])
tgt_mask:
tensor([[[1, 0, 0, 0],[1, 1, 0, 0],[1, 1, 1, 0],[1, 1, 1, 1]]])
next_word: tensor(6)
--------------------------------------------------------------------------------ys: tensor([[0, 8, 5, 6, 6]])
tgt_mask:
tensor([[[1, 0, 0, 0, 0],[1, 1, 0, 0, 0],[1, 1, 1, 0, 0],[1, 1, 1, 1, 0],[1, 1, 1, 1, 1]]])
next_word: tensor(6)
--------------------------------------------------------------------------------Example Untrained Model Prediction: tensor([[0, 8, 5, 6, 6, 6]])
可以看到,首轮循环中,ys 使用的是初始值,即0,在真实环境中,输入的是起始符。这相当于模型读取完源语言了,要快开始写目标语言了,此时要执行decoder,decoder也得有输入单词,所以只能输入起始符。首轮循环生成的单词是8,它被加入到 ys 中,新的 ys 作为第二轮循环的 decoder 的输入,所以第二轮循环的 ys 为 tensor([[0, 8]])。依次类推,之后每轮生成的单词,都加入到 ys 中,作为下一轮循环的 decoder 的输入。所以,Decoder的输入,并不是像 RNN/LSTM 那样一个词一个词地输入,而是每次把所有已经生成的词整合成一个矩阵,然受一起输入,越往后,这个矩阵越大。
循环开始时 ys 只有一个单词tensor([[0]]),所以目标语言的 mask(即tgt_mask)为 tensor([[[1]]]),而 tgt_mask 在 decoder 中只在做自注意力机制的时候使用,也就是说,唯一的单词只能对自己做自注意力机制。第二轮循环中,ys 为 tensor([[0, 8]]),此时 tgt_mask 为:
tensor([[[1, 0],[1, 1]]])
也就是说,第一个单词只能对自己做自注意力机制,第二个单词可以对第一个单词,也可以对自己。
观察后续几轮循环的 tgt_mask ,可以发现这是一个下三角矩阵,即 decoder 的输入中,第 i i i 个单词只能对自己( i i i )和自己之前(0 ~ i − 1 i-1 i−1)的单词做自注意力机制。这样设计的目的,是为了在生成单词的时候,确保只能依赖之前已经生成的单词。
4.2.4 Decoder中的交叉注意力机制输入张量的维度
因为decoder每次输入的 ys 长度不一样,导致做交叉注意力机制时,query的维度不一样,它的维度为(batch_size, h, decoder_seq_len, d_model),decoder_seq_len始终在变,而 key 和 value 来自于 encoder 的输出,始终是(batch_size, h, encoder_seq_len, d_model)。
4.2.5 Decoder中的重复计算问题
细心的读者可能已经发现,这里面出现大量的重复计算。在第一轮循环时,第一个单词已经对自己做了注意力机制,后续几轮循环却仍然在做;第二轮循环时,第二单词已经对第一个单词做了注意力机制,后续的循环还在继续做。用通俗一点的话说,假如第3轮预测得到[0, 8, 5, 6],这里0是初始的(即起始符),8、5、6是计算得到的,第四轮预测得到[0, 8, 5, 6, 6],这里把8、5、6的预测过程重新走了一遍,而非只预测最后一个6。
5 总结
本文通过逐步搭建Transformer模型的方式,逐个讲解了transformer的零部件,然后又介绍了mask,还介绍了 Decoder 中的自注意力机制。本文的重点是:QKV 注意力机制、位置编码的作用、Encoder中的mask、Decoder中的自注意力机制与交叉注意力机制的过程,这些理解了,transformer主体就理解了。












