
一、容器化环境抓包
在日常kubernetes的运维中,经常遇到pod的网络问题,如pod间网络不通,或者端口不通,更复杂的,需要在容器里面抓包分析才能定位。
而kubertnets的场景,pod使用的镜像一般都是尽量精简,很多都是基于alpine基础镜像制作的,因而pod内没有ping,telnet,nc,curl命令,更别说tcpdump这种复杂的工具了。除了在容器或者镜像内直接安装这些工具这种最原始的法子,我们探讨下其他法子。
- kubectl debug方式功能更强大,缺点是需要附加镜像,要在目标pod创建debug agent的容器,比较笨重,但是优点是能使用的工具更多,不需要ssh到pod所在节点,除了netstat,tcpdump工具,还能使用htop,iostat等其他高级工具,不仅能对网络进行debug,还能对IO等其他场景进行诊断,适用更复杂的debug场景。
- 直接进入容器net ns方式相对比较轻量,复用pod所在宿主机工具,但鱼和熊掌不可兼得,缺点是只能进行网络方面的debug,且需要ssh登录到pod所在节点操作。
一)kubectl debug插件方式
https://www.cnblogs.com/centos-python/articles/13409595.html
项目地址 kubect debug,https://github.com/aylei/kubectl-debug
kubectl-debug 是一个简单的 kubectl 插件,能够帮助你便捷地进行 Kubernetes 上的 Pod 排障诊断。背后做的事情很简单: 在运行中的 Pod 上额外起一个新容器,并将新容器加入到目标容器的 pid, network, user 以及 ipc namespace 中,这时我们就可以在新容器中直接用 netstat, tcpdump 这些熟悉的工具来解决问题了, 而旧容器可以保持最小化,不需要预装任何额外的排障工具。操作流程可以参见官方项目地址文档。
步骤分别是:
- 插件查询 ApiServer:demo-pod 是否存在,所在节点是什么
- ApiServer 返回 demo-pod 所在所在节点
- 插件请求在目标节点上创建 Debug Agent Pod
- Kubelet 创建 Debug Agent Pod
- 插件发现 Debug Agent 已经 Ready,发起 debug 请求(长连接)
- Debug Agent 收到 debug 请求,创建 Debug 容器并加入目标容器的各个 Namespace 中,创建完成后,与 Debug 容器的 tty 建立连接
接下来,客户端就可以开始通过 5,6 这两个连接开始 debug 操作。操作结束后,Debug Agent 清理 Debug 容器,插件清理 Debug Agent,一次 Debug 完成。
二)kubernetes中pod+wireShark抓包
1、找到pod所在的宿主机
kubectl get po -n flyte -o wide

2、获取宿主机的详情
kubectl get node nebula-dev-node02-183 -o wide

3、ssh连接到宿主机
ssh 192.168.10.183

4、查到pod的id
# docker ps|grep flyteadmin 34d9a13d3f89 ca7e09f358f8 "sh -c 'ln -s /usr/s…" 23 hours ago Up 23 hours k8s_redoc_flyteadmin-675b978d44-98zg5_flyte_93cb40d8-3fe2-4426-bb8b-e251e77db03d_0

docker ps|grep ${pod关键词}|grep bin|awk '{print $1}'
5、获取pod的stat id
# docker inspect --format {{.State.Pid}} 34d9a13d3f89
11389

docker inspect --format {{.State.Pid}} $(docker ps|grep ${pod关键词}|grep bin|awk '{print $1}')
6、获取容器虚拟网卡序号
nsenter为util-linux里面的一个工具,除了进入容器net ns,还支持其他很多操作,可以查看官方文档。
# nsenter -n -t 11389 ip addr
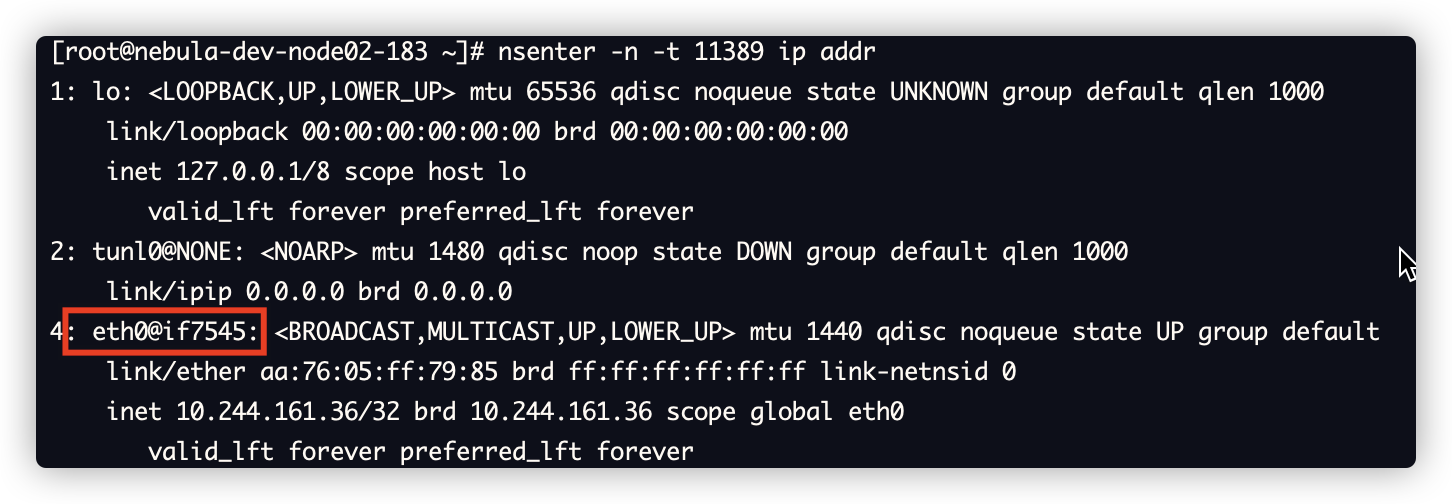
nsenter -n -t ${pod_stat_id} ip addr|grep eth0@|awk -F ": " '{print $2}'|awk -F "@" '{print $2}'|awk -F "if" '{print $2}'
几步集成到一起
nsenter -n -t $(docker inspect --format {{.State.Pid}} $(docker ps|grep freeman|grep bin|awk '{print $1}')) ip addr|grep eth0@|awk -F ": " '{print $2}'|awk -F "@" '{print $2}'|awk -F "if" '{print $2}'
7、获取容器虚拟网卡信息
# ip addr|grep 7545 7545: calid97ed9edaec@if4: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1440 qdisc noqueue state UP group default

几步集成到一起
ip addr|grep $(nsenter -n -t $(docker inspect --format {{.State.Pid}} $(docker ps|grep freeman|grep bin|awk '{print $1}')) ip addr|grep eth0@|awk -F ": " '{print $2}'|awk -F "@" '{print $2}'|awk -F "if" '{print $2}')|awk -F ": " '{print $2}'|awk -F "@" '{print $1}'
8、tcp对网卡进行抓包
]# tcpdump -i calid97ed9edaec -w k8s_redoc_flyteadmin.cap tcpdump: listening on calid97ed9edaec, link-type EN10MB (Ethernet), capture size 262144 bytes

9、ctrl+C 终止抓包, 下载cap文件, 使用Wireshark打开
二、kube-proxy的iptables与IPvs
一)iptables
1、iptables的功能
- 流量转发:DNAT实现IP地址和端口的映射
- 负载均衡:statistic模块为每个后端设置权重
- 会话保持:recent模块设置会话保持时间
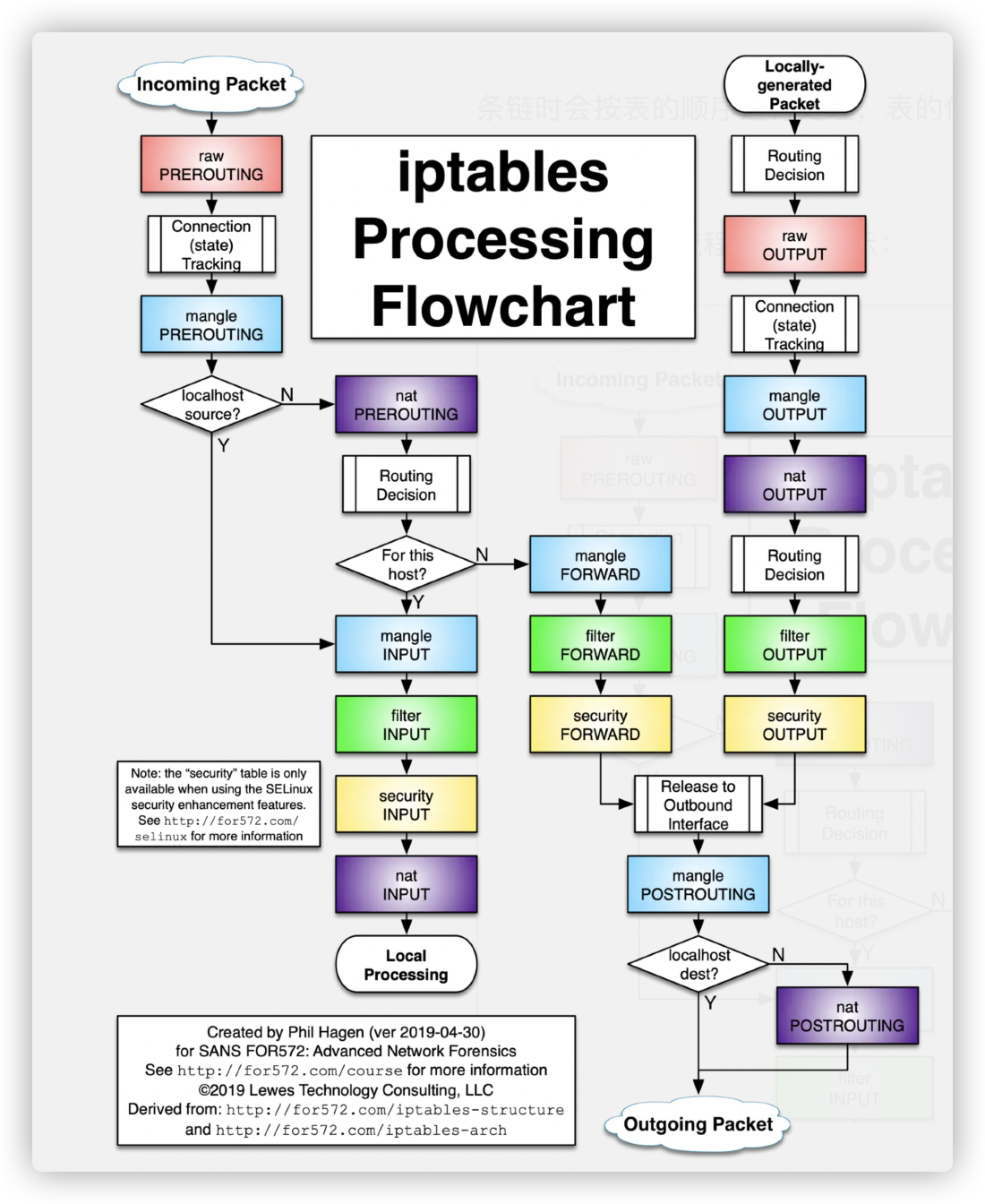
2、iptables 有五张表和五条链
五条链分别对应为:
- PREROUTING 链:数据包进入路由之前,可以在此处进行 DNAT;
- INPUT 链:一般处理本地进程的数据包,目的地址为本机;
- FORWARD 链:一般处理转发到其他机器或者 network namespace 的数据包;
- OUTPUT 链:原地址为本机,向外发送,一般处理本地进程的输出数据包;
- POSTROUTING 链:发送到网卡之前,可以在此处进行 SNAT;
五张表分别为:
- filter 表:用于控制到达某条链上的数据包是继续放行、直接丢弃(drop)还是拒绝(reject);
- nat 表:network address translation 网络地址转换,用于修改数据包的源地址和目的地址;
- mangle 表:用于修改数据包的 IP 头信息;
- raw 表:iptables 是有状态的,其对数据包有链接追踪机制,连接追踪信息在 /proc/net/nf_conntrack 中可以看到记录,而 raw 是用来去除链接追踪机制的;
- security 表:最不常用的表,用在 SELinux 上;
这五张表是对 iptables 所有规则的逻辑集群且是有顺序的,当数据包到达某一条链时会按表的顺序进行处理,表的优先级为:raw、mangle、nat、filter、security。
3、iptables的工作流程
4、kube-proxy的iptables模式
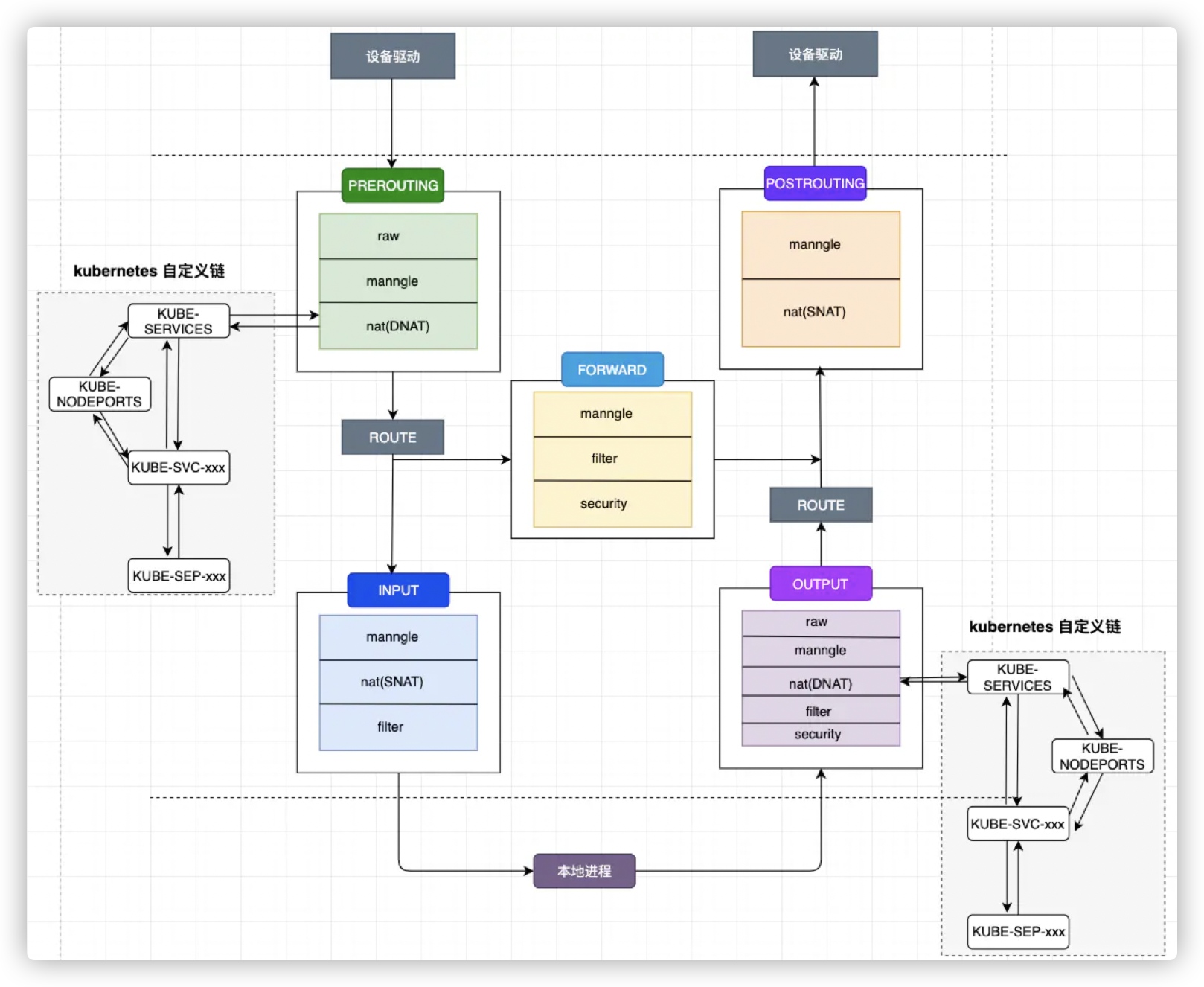
kube-proxy 组件负责维护 node 节点上的防火墙规则和路由规则,在 iptables 模式下,会根据 service 以及 endpoints 对象的改变来实时刷新规则,kube-proxy 使用了 iptables 的 filter 表和 nat 表,并对 iptables 的链进行了扩充,自定义了 KUBE-SERVICES、KUBE-EXTERNAL-SERVICES、KUBE-NODEPORTS、KUBE-POSTROUTING、KUBE-MARK-MASQ、KUBE-MARK-DROP、KUBE-FORWARD 七条链,另外还新增了以“KUBE-SVC-xxx”和“KUBE-SEP-xxx”开头的数个链,除了创建自定义的链以外还将自定义链插入到已有链的后面以便劫持数据包。
kubernetes自定义链
二)IPvs
1、iptables的问题
iptables效率低,k8s v1.11已经release了IPVS
- 规则线性匹配时延
- 规则更新时延
- 可扩展性差
2、IPVS详解
kube-proxy ipvs 模式源码分析 - 简书
设置成IPVS模块需要满足
- k8s版本 >= v1.11
- 安装ipset, ipvsadm安装ipset, ipvsadm, yum install ipset ipvsadm -y
- 确保 ipvs已经加载内核模块, ip_vs、ip_vs_rr、ip_vs_wrr、ip_vs_sh、nf_conntrack_ipv4。如果这些内核模块不加载,当kube-proxy启动后,会退回到iptables模式。
检查是否加载
# lsmod | grep -e ip_vs -e nf_conntrack_ipv4 nf_conntrack_ipv4 15053 63 nf_defrag_ipv4 12729 1 nf_conntrack_ipv4 ip_vs_sh 12688 0 ip_vs_wrr 12697 0 ip_vs_rr 12600 0 ip_vs 145497 6 ip_vs_rr,ip_vs_sh,ip_vs_wrr nf_conntrack 133095 10 ip_vs,nf_nat,nf_nat_ipv4,nf_nat_ipv6,xt_conntrack,nf_nat_masquerade_ipv4,nf_nat_masquerade_ipv6,nf_conntrack_netlink,nf_conntrack_ipv4,nf_conntrack_ipv6 libcrc32c 12644 5 xfs,ip_vs,libceph,nf_nat,nf_conntrack
修改kube-proxy 启动参数
在每个worker节点上修改,kube-proxy启动参数
vi /etc/systemd/system/kube-proxy.service, 加上 --proxy-mode=ipvs \,然后执行下面命令
systemctl daemon-reload service kube-proxy restart
kube-proxy ipvs原理分析
由于 IPVS 的 DNAT 钩子挂在 INPUT 链上,因此必须要让内核识别 VIP 是本机的 IP。k8s 通过设置将service cluster ip 绑定到虚拟网卡kube-ipvs0,其中下面的172.16.x.x都是VIP,也就是cluster-ip。
ipvs 会使用 iptables 进行包过滤、SNAT、masquared(伪装)。具体来说,ipvs 将使用ipset来存储需要DROP或masquared的流量的源或目标地址,以确保 iptables 规则的数量是恒定的,这样我们就不需要关心我们有多少服务了。
在以下情况时,ipvs依然依赖于iptables:
- kube-proxy 配置参数 –masquerade-all=true, 如果 kube-proxy 配置了–masquerade-all=true参数,则 ipvs 将伪装所有访问 Service 的 Cluster IP 的流量,此时的行为和 iptables 是一致的。
- 在 kube-proxy 启动时指定集群 CIDR,如果 kube-proxy 配置了–cluster-cidr=参数,则 ipvs 会伪装所有访问 Service Cluster IP 的外部流量,其行为和 iptables 相同。
- Load Balancer 类型的 Service
- NodePort 类型的 Service
- 指定 externalIPs 的 Service
三)iptables与IPVS的区别与联系
1、区别:
- 底层数据结构:iptables 使用链表,ipvs 使用哈希表
- 负载均衡算法:iptables 只支持随机、轮询两种负载均衡算法而 ipvs 支持的多达 8 种;
- 操作工具:iptables 需要使用 iptables 命令行工作来定义规则,ipvs 需要使用 ipvsadm 来定义规则。
此外 ipvs 还支持 realserver 运行状况检查、连接重试、端口映射、会话保持等功能。
2、联系:
ipvs 和 iptables 都是基于 netfilter内核模块,两者都是在内核中的五个钩子函数处工作












