
用户行为日志分析(python+hadoop+mapreduce+yarn+hive)
-
搭建完全分布式高可用大数据集群(VMware+CentOS+FinalShell)
-
搭建完全分布式高可用大数据集群(Hadoop+MapReduce+Yarn)
-
本机PyCharm远程连接虚拟机Python
-
搭建完全分布式高可用大数据集群(MySQL+Hive)
-
本机DataGrip远程连接虚拟机MySQL/Hive
在阅读本文前,请确保已经阅读过以上5篇文章,成功搭建了Hadoop+MapReduce+Yarn+Python+Hive的大数据集群环境。
写在前面
本文主要介绍基于mapreduce+hive技术,自己编写python代码实现用户行为日志分析的详细步骤。
-
电脑系统:
Windows -
技术需求:
Hadoop、MapReduce、Yarn、Python3.12.8、Hive -
使用软件:
VMware、FinalShell、PyCharm、DataGrip
注:本文的所有操作均在虚拟机master中进行,不涉及另外两台虚拟机。(但是要开机)
启动Hadoop
-
使用finalshell连接并启动
master、slave01、slave02三台虚拟机。 -
在虚拟机
master的终端输入命令start-all.sh启动hadoop、mapreduce和yarn。 -
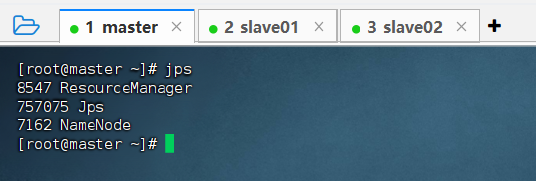
随后可以用命令
jps查看是否成功启动集群。
启动历史服务器
- 在
master的终端输入命令mr-jobhistory-daemon.sh start historyserver启动历史服务器。
- 历史服务器可以在mapreduce出错时查看报错原因。
- 如果不启动该历史服务器,则无法使用web页面(http://master:19888/jobhistory)查看mapreduce程序的运行状态。
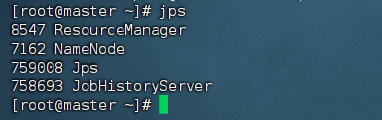
- 输入
jps查看历史服务器是否成功启动。
准备数据
- 创建文本数据
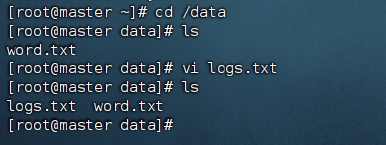
① 在虚拟机master的终端输入命令cd /data进入/data目录。
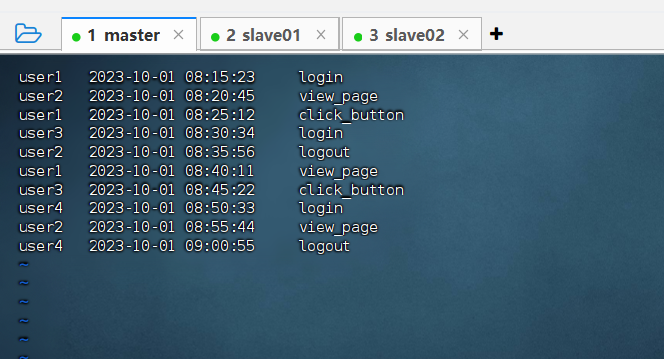
② 在虚拟机master的终端输入命令 vi logs.txt 创建并打开logs.txt文件,填入以下内容。
user1 2023-10-01 08:15:23 login
user2 2023-10-01 08:20:45 view_page
user1 2023-10-01 08:25:12 click_button
user3 2023-10-01 08:30:34 login
user2 2023-10-01 08:35:56 logout
user1 2023-10-01 08:40:11 view_page
user3 2023-10-01 08:45:22 click_button
user4 2023-10-01 08:50:33 login
user2 2023-10-01 08:55:44 view_page
user4 2023-10-01 09:00:55 logout
数据说明
user_id: 用户唯一标识。log_time: 日志时间,格式为YYYY-MM-DD HH:MM:SS。action: 用户执行的操作,例如login、logout、view_page、click_button等。
数据示例
user1在2023-10-01 08:15:23登录。user2在2023-10-01 08:20:45浏览页面。user1在2023-10-01 08:25:12点击按钮。user3在2023-10-01 08:30:34登录。user2在2023-10-01 08:35:56登出。user1在2023-10-01 08:40:11再次浏览页面。user3在2023-10-01 08:45:22点击按钮。user4在2023-10-01 08:50:33登录。user2在2023-10-01 08:55:44再次浏览页面。user4在2023-10-01 09:00:55登出。
- 创建目录
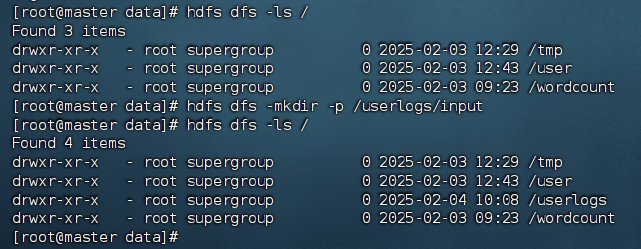
① 在终端输入以下命令,可以在HDFS中创建/userlogs/input目录,用于存放文件logs.txt。
hdfs dfs -mkdir -p /userlogs/input
② 在终端输入以下命令验证是否创建/userlogs/input目录。
hdfs dfs -ls /
- 上传文件
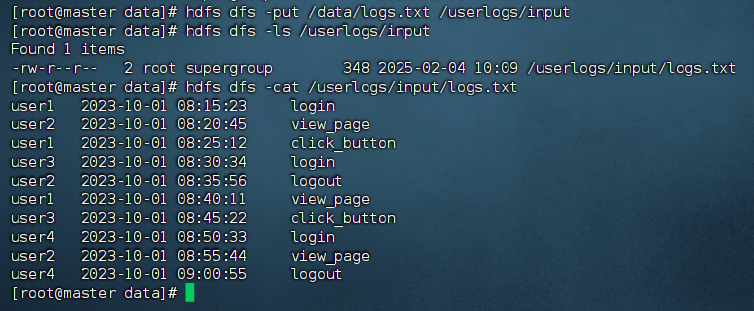
① 在终端执行以下命令将文件logs.txt上传到HDFS的/userlogs/input目录。
hdfs dfs -put /data/logs.txt /userlogs/input
② 在终端输入以下命令验证是否成功将文件logs.txt上传到HDFS的/userlogs/input目录。
hdfs dfs -ls /userlogs/input
③ 可以使用以下命令查看上传的logs.txt文件的内容。
hdfs dfs -cat /userlogs/input/logs.txt
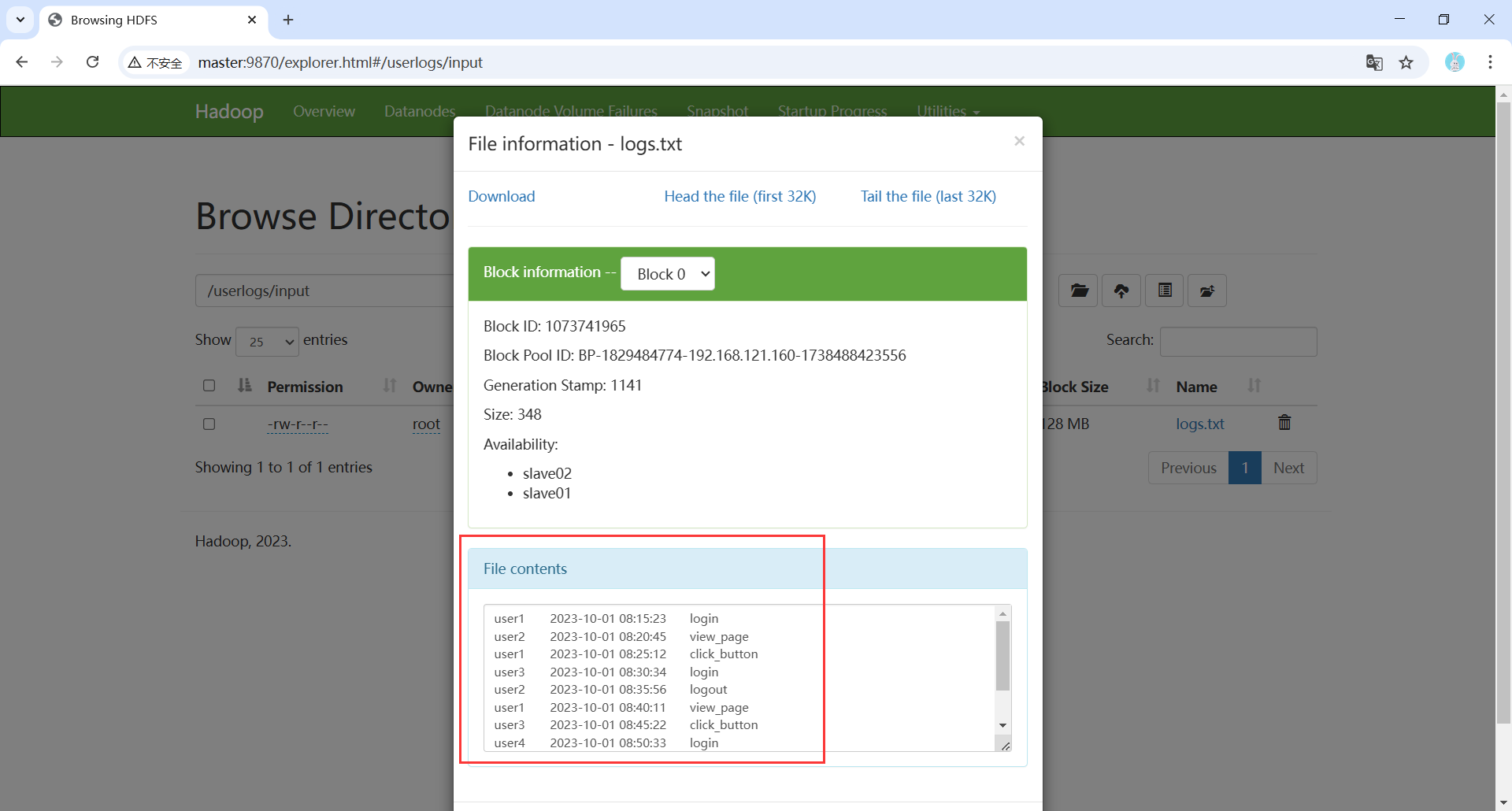
④ 也可以通过HDFS的Web UI(http://master:9870)查看文件logs.txt是否上传成功。
编写Python脚本
打开PyCharm专业版,远程连接虚拟机master,先创建一个文件夹userlogs,后在该文件夹中分别创建map.py和reduce.py两个脚本。
1. 编写mapper脚本map.py
在map.py脚本中填入以下代码。
import sysfor line in sys.stdin:# 假设输入的每一行是Hive表中的一行数据user_id, log_time, action = line.strip().split('\t')# 输出 user_id 和 actionprint(f"{user_id}\t{action}")
这段代码是一个典型的 MapReduce Mapper 脚本,用 Python 编写,用于处理从 Hive 表或 HDFS 文件中读取的日志数据。,以下是对代码的详细分析。
-
读取输入数据:
- 通过
sys.stdin逐行读取输入数据。输入数据通常来自 Hadoop Streaming 的输入文件(如 Hive 表导出文件或 HDFS 文件)。 - 每行数据的格式为
user_id\tlog_time\taction,例如:user1\t2023-10-01 08:15:23\tlogin。
- 通过
-
数据解析:
- 使用
line.strip().split('\t')对每行数据进行解析:strip():去除行首尾的空白字符(如换行符)。split('\t'):以制表符(\t)为分隔符,将行数据拆分为user_id、log_time和action三个字段。
- 使用
-
输出结果:
- 使用
print(f"{user_id}\t{action}")输出user_id和action,中间用制表符分隔。 - 输出格式为
user_id\taction,例如:user1\tlogin。
- 使用
总的来说,这段代码是一个简单但功能明确的 Mapper 脚本,适用于从结构化日志数据中提取关键字段并生成中间结果。通过优化异常处理和性能,可以使其更加健壮和高效。
2. 编写reducer脚本reduce.py
在reduce.py脚本中填入以下代码。
import sys
from collections import defaultdictaction_count = defaultdict(int)for line in sys.stdin:user_id, action = line.strip().split('\t')action_count[(user_id, action)] += 1for (user_id, action), count in action_count.items():print(f"{user_id}\t{action}\t{count}")
这段代码是一个典型的 MapReduce Reducer 脚本,用 Python 编写,用于对 Mapper 输出的中间结果进行聚合统计,以下是对代码的详细分析。
-
读取输入数据:
- 通过
sys.stdin逐行读取 Mapper 输出的中间结果,每行数据的格式为user_id\taction,例如:user1\tlogin。
- 通过
-
数据统计:
- 使用
defaultdict(int)创建一个字典action_count,用于统计每个(user_id, action)组合的出现次数。 - 对每行数据解析后,将
(user_id, action)作为键,累加其计数:action_count[(user_id, action)] += 1。
- 使用
-
输出结果:
- 遍历
action_count字典,输出每个(user_id, action)组合及其出现次数,格式为user_id\taction\tcount,例如:user1\tlogin\t3。
- 遍历
这段代码是一个简单但功能明确的 Reducer 脚本,适用于对 Mapper 输出的中间结果进行聚合统计。通过优化异常处理和性能,可以使其更加健壮和高效。
运行MapReduce程序
- 查看
mapreduce程序
进入虚拟机master的/opt/hadoop/share/hadoop/tools/lib目录,在该目录下执行ls命令,查看hadoop提供的mapreduce程序。
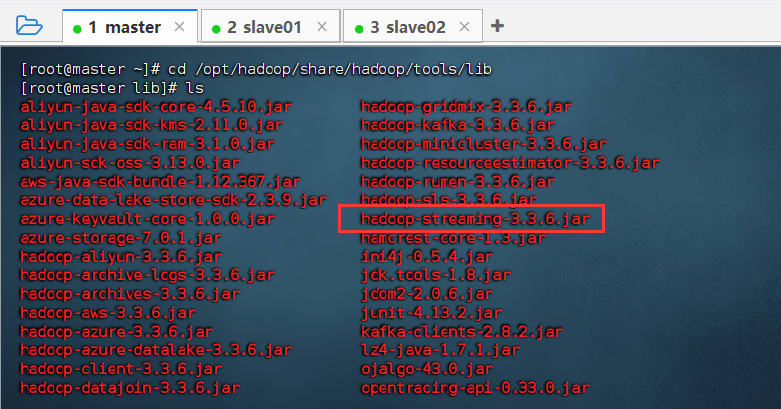
其中,hadoop-streaming-3.3.6.jar是执行mapreduce的程序。
- 执行
mapreduce程序
① 在终端输入命令cd /opt/python/code/userlogs进入存放map.py和reduce.py脚本的目录。

② 执行以下命令,统计logs.txt文件中的用户行为。
hadoop jar /opt/hadoop/share/hadoop/tools/lib/hadoop-streaming-3.3.6.jar -file map.py -file reduce.py -input /userlogs/input/logs.txt -output /userlogs/output -mapper "python map.py" -reducer "python reduce.py"
注意: 在每次执行这个命令前,请确保/userlogs/output的output文件夹不在HDFS中,如果在,请删除。
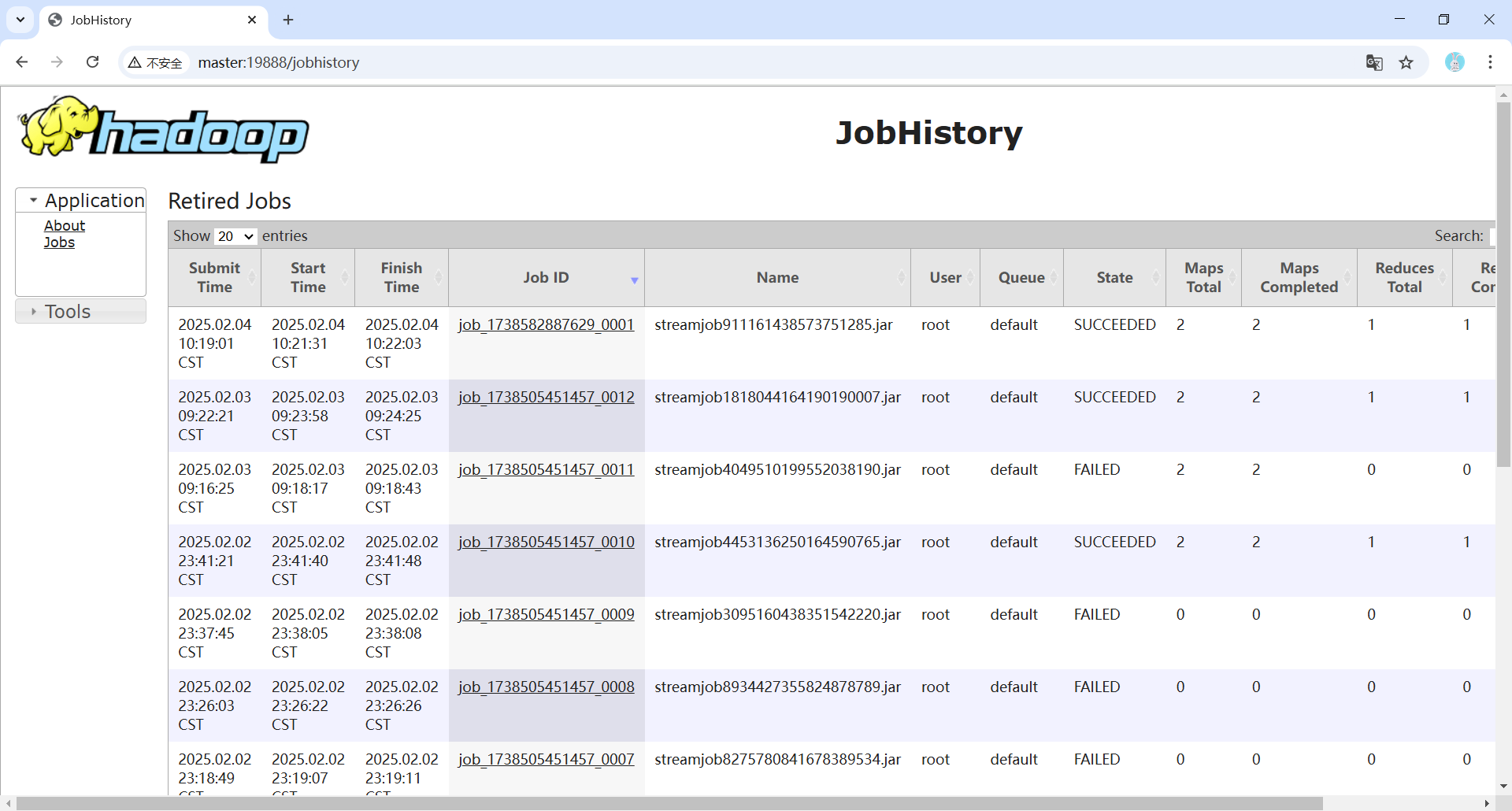
③ 出现以下信息说明程序执行成功。
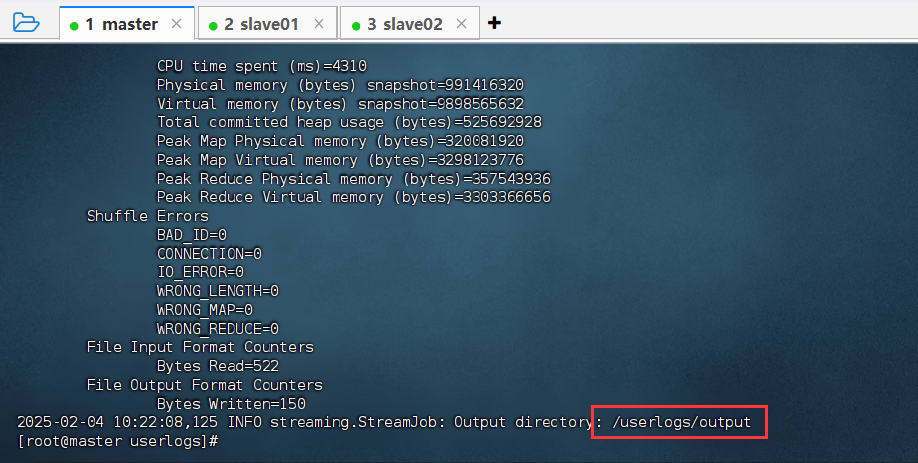
查看程序运行状态和结果
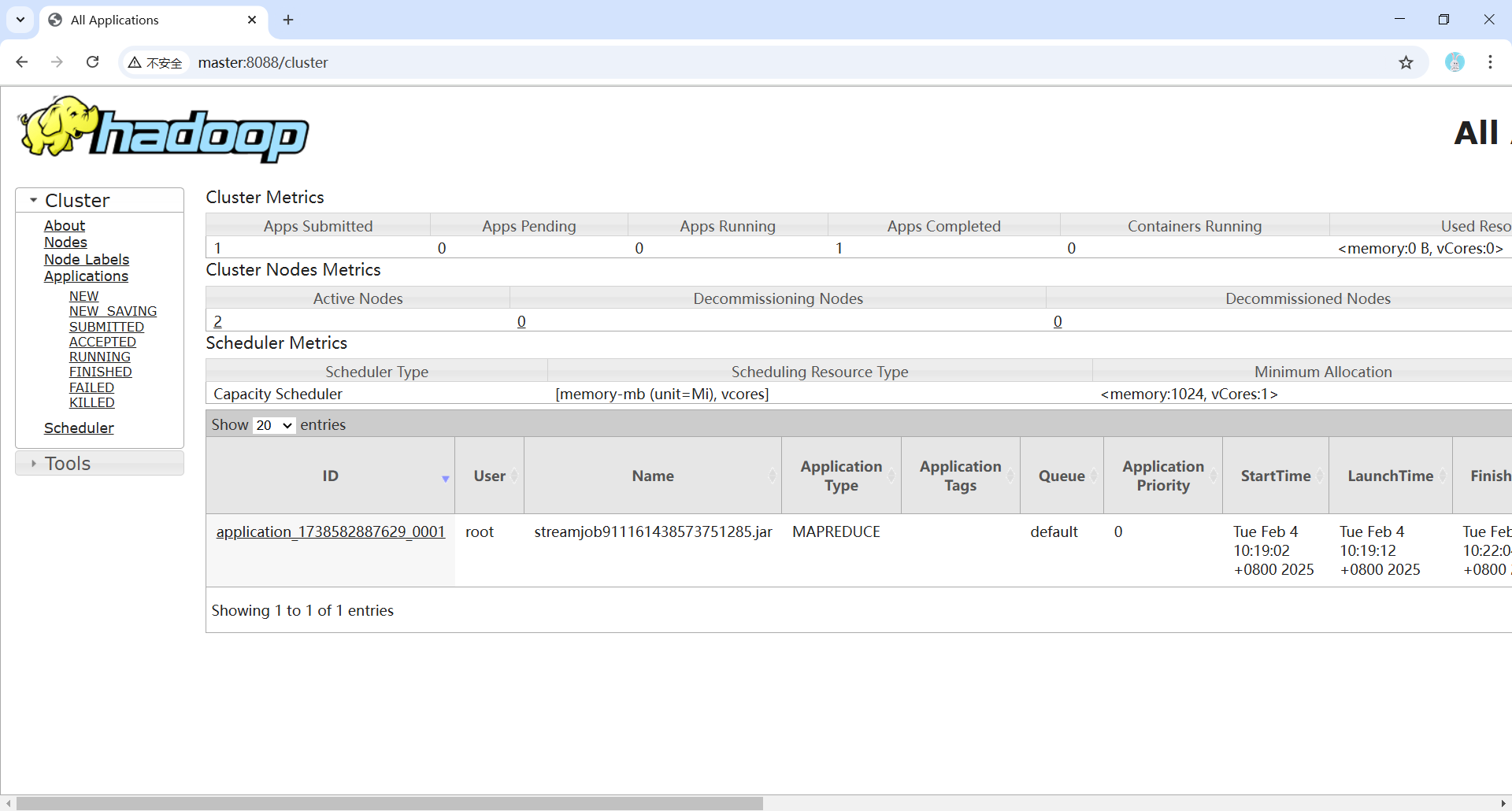
- MapReduce程序运行过程中,可以使用浏览器访问Web UI(http://master:8088)查看历史服务器。
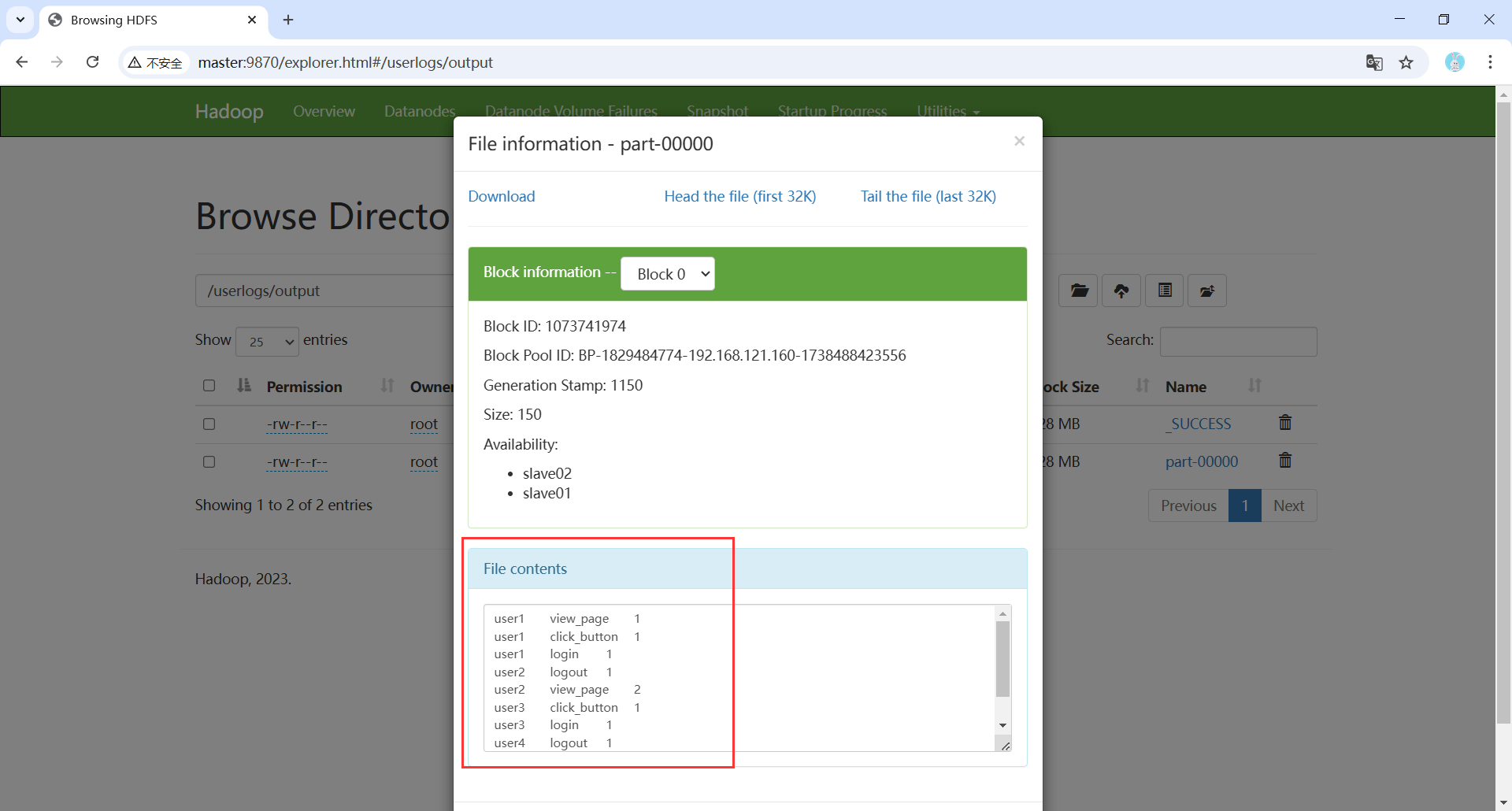
- MapReduce程序运行结束后,可以在HDFS的Web UI(http://master:9870)查看用户行为日志的统计的结果。
- 当然,也可以在
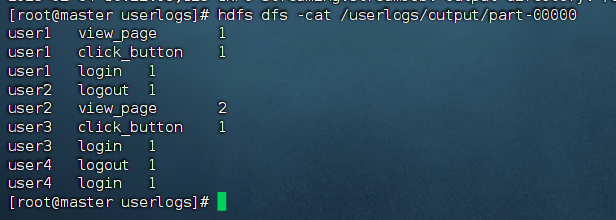
master的终端输入以下命令查看程序运行结果。
hdfs dfs -cat /userlogs/output/part-00000
注意: 如果在运行mapreduce程序时出现错误,可以使用浏览器访问Web UI(http://master:19888/jobhistory)查看历史服务器的logs文件。
将结果存入Hive
在虚拟机中启动Hive,打开DataGrip,远程连接虚拟机的hive。
① 启动hiveserver2服务:hive --service hiveserver2(第一个master终端)
② 启动beeline连接:beeline -u jdbc:hive2://master:10000 -n root(第三个master终端)
③ 使用DataGrip远程连接Hive
- 打开
DataGrip的Query Console,输入以下代码,创建一个名为userlogs的Hive表。
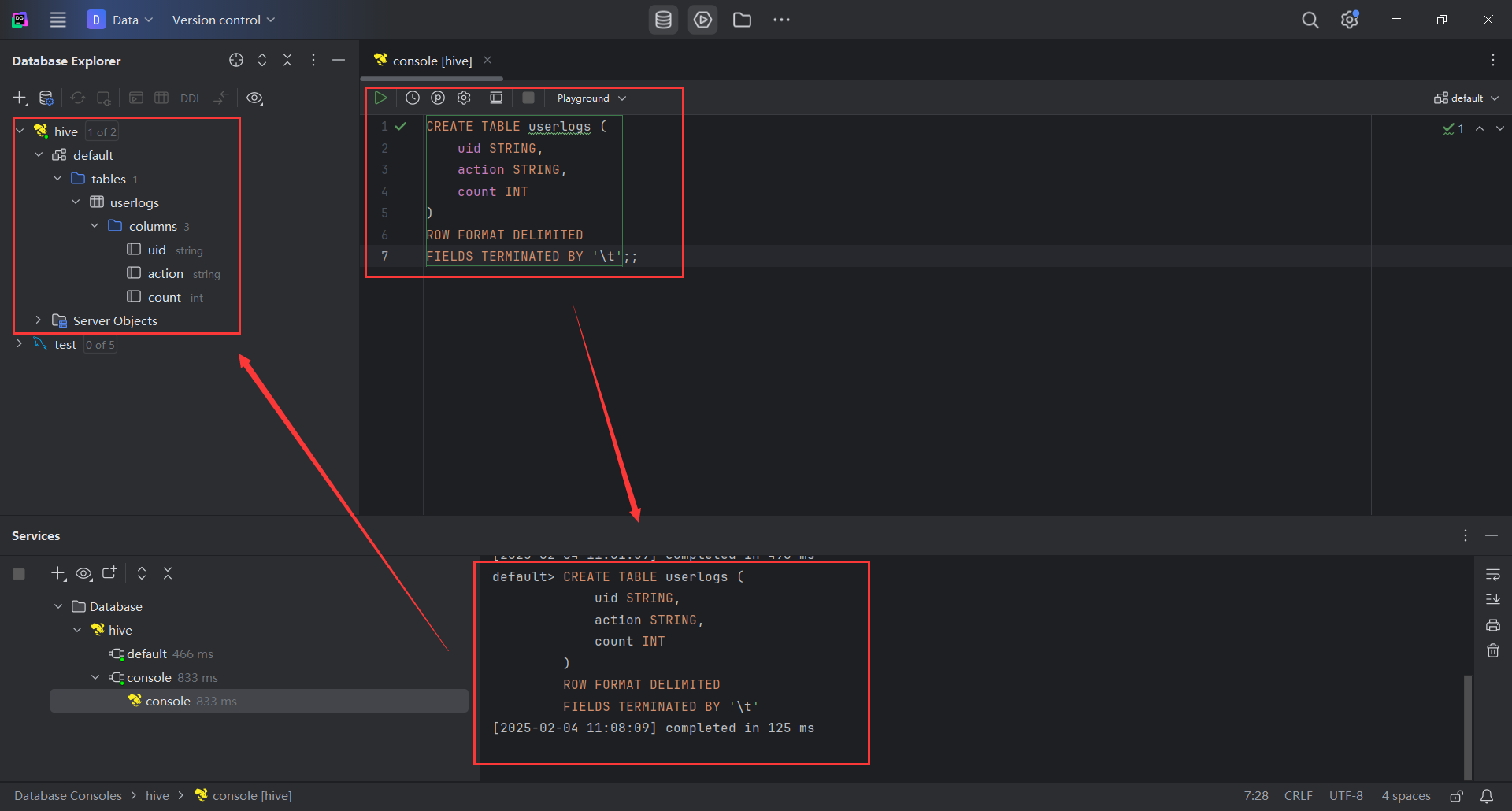
CREATE TABLE userlogs (uid STRING,action STRING,count INT
)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY '\t';
这段 SQL 语句用于在 Hive 中创建一个表 userlogs,让我们逐部分分析这段 SQL语句。
-
CREATE TABLE userlogs (...)-
CREATE TABLE userlogs: 这部分表示创建一个名为userlogs的表。 -
(...): 括号内定义了表的列名和数据类型。这里定义了 3 列。
-
-
列定义
-
uid STRING: 第一列是uid,数据类型是STRING。这里假设存储的是用户标识符(如user1、user2等)。STRING类型可以存储任意文本数据。 -
action STRING: 第二列是action,数据类型也是STRING。它表示用户的操作类型(如view_page、click_button、Login等)。 -
count INT: 第三列是count,数据类型是INT,表示操作的计数或频率(如1、2等)。
-
-
ROW FORMAT DELIMITED- 这部分表示数据的存储格式是 定界符分隔的 。在 Hive 中,
ROW FORMAT DELIMITED表示数据以某种字符(比如制表符、逗号等)分隔。
- 这部分表示数据的存储格式是 定界符分隔的 。在 Hive 中,
-
FIELDS TERMINATED BY '\t'FIELDS TERMINATED BY '\t': 这部分指定了字段之间使用制表符(\t)作为分隔符,也就是每列的值通过制表符分隔。这样,Hive 就知道如何解析存储在文件中的数据。
总的来说,这段 SQL 语句的功能是创建一个 userlogs 表,表中有三列:uid(用户标识符)、action(用户执行的操作)、count(操作次数)。每行数据的字段由制表符 \t 分隔,且表采用 定界符分隔 的存储格式。
这个表结构适用于存储类似于以下数据的记录:
user1 view_page 1
user1 click_button 1
user1 Login 1
user2 logout 1
user2 view_page 2
...
注意:该userlogs表默认创建在default数据库中。
- 在
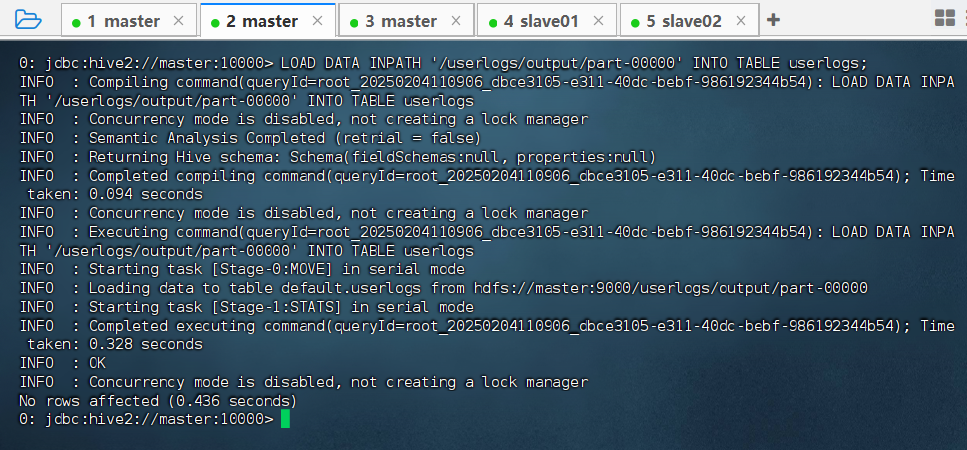
beeline命令行入以下命令,将mapreduce的输出加载到Hive的userlogs表中。
LOAD DATA INPATH '/userlogs/output/part-00000' INTO TABLE userlogs;
- 在DataGrip中查看
uselogs数据表中的数据。
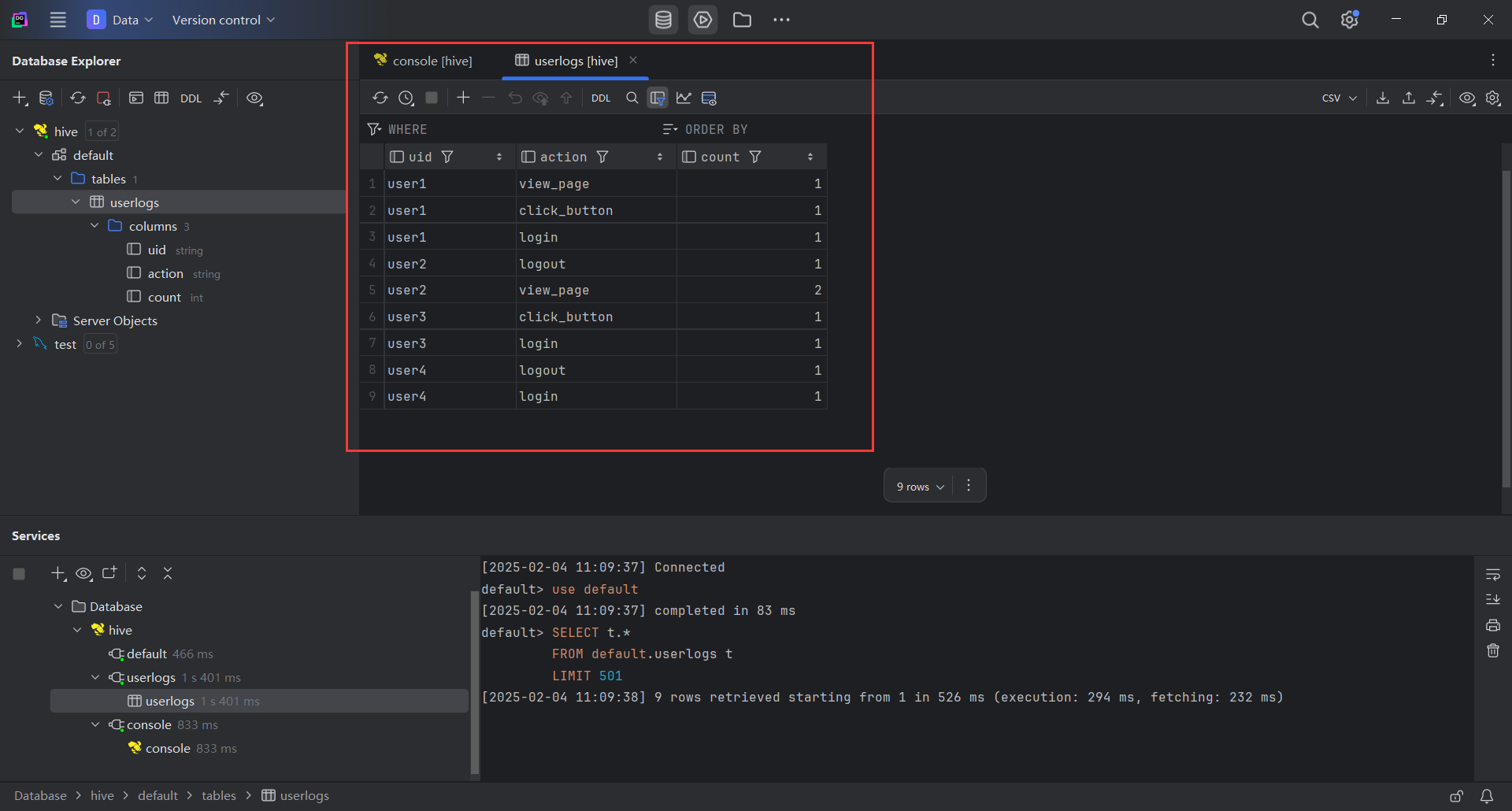
- 在
beeline使用SELECT * FROM userlogs LIMIT 10;命令查看数据信息。
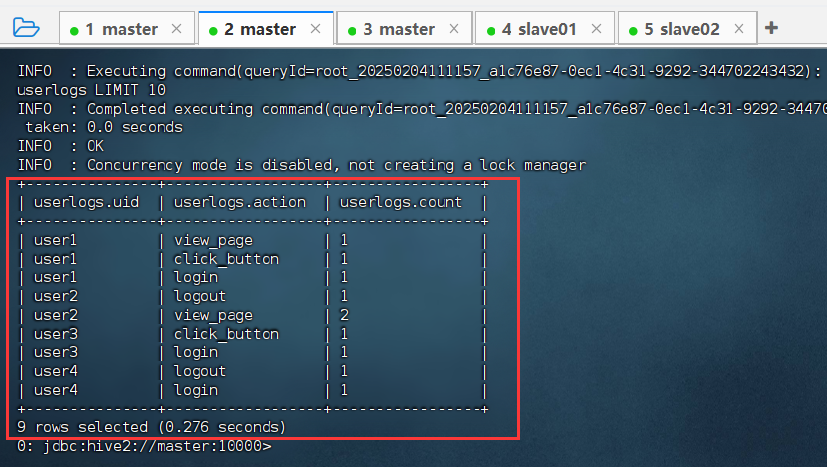
到此,成功将mapreduce的执行结果存入了hive的default数据库的userlogs数据表中。
注意事项
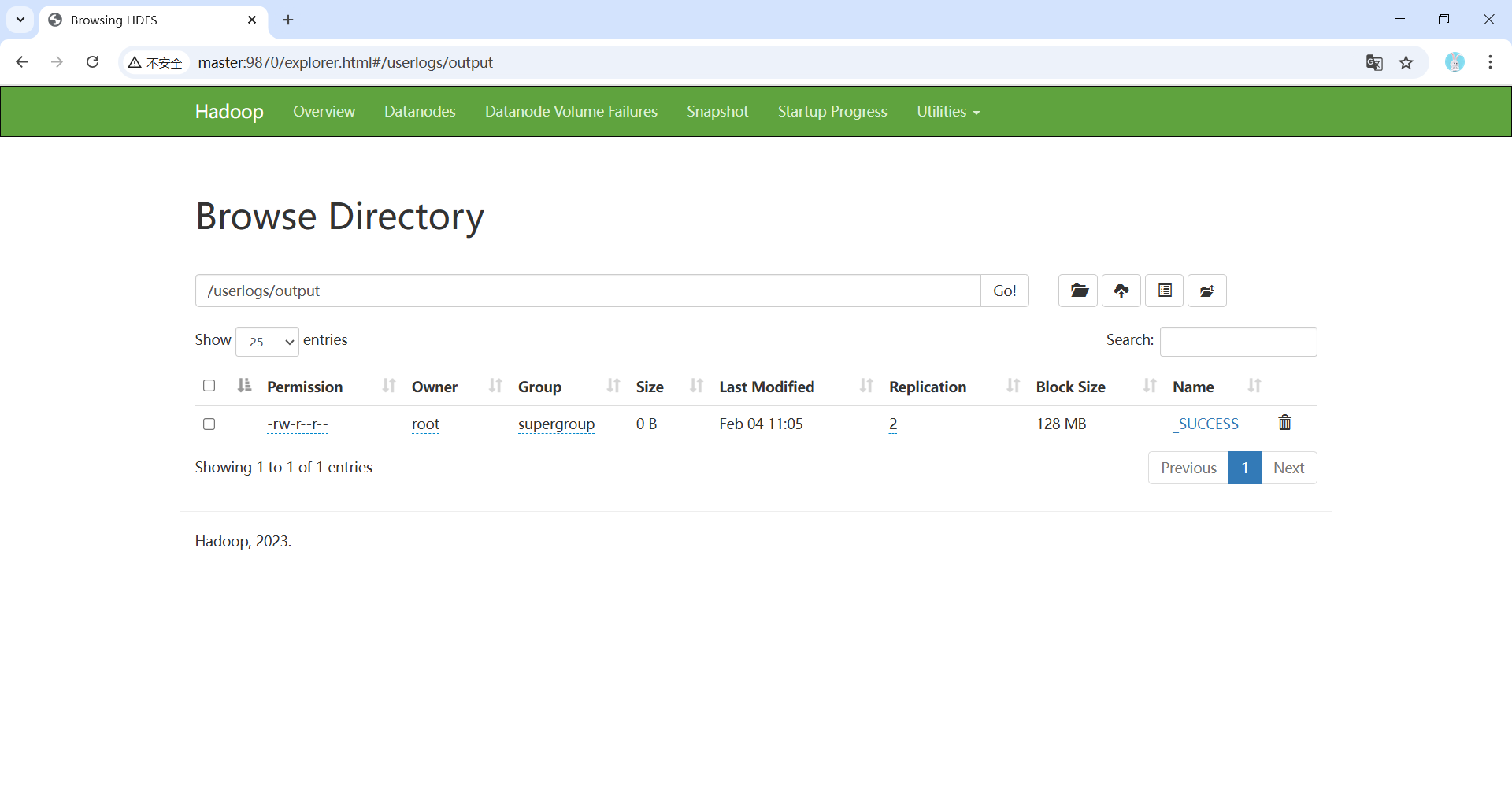
- 执行
LOAD DATA INPATH '/userlogs/output/part-00000' INTO TABLE userlogs;命令后,在HDFS中的part-00000文件将被移动至Hive中。
- 启动HiveServer2服务后,可以访问Web UI(http://master:10002/)查看Hive信息。

写在后面
本文仅供学习使用,原创文章,请勿转载,谢谢配合。












