
自学python如何成为大佬(目录):https://blog.csdn.net/weixin_67859959/article/details/139049996?spm=1001.2014.3001.5501
网络爬虫(又被称为网络蜘蛛、网络机器人,在某社区中经常被称为网页追逐者),可以按照指定的规则(网络爬虫的算法)自动浏览或抓取网络中的信息,通过Python可以很轻松地编写爬虫程序或者是脚本。
一个通用的网络爬虫基本工作流程如图1所示。
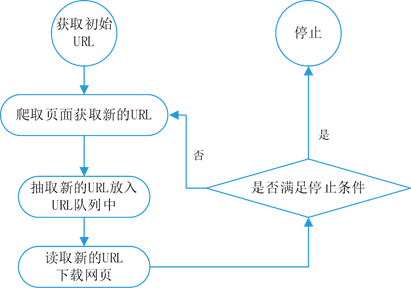
图1 通用的网络爬虫基本工作流程
网络爬虫的基本工作流程如下:
(1)获取初始的URL,该URL地址是用户自己制定的初始爬取的网页。
(2)爬取对应URL地址的网页时,获取新的URL地址。
(3)将新的URL地址放入URL队列中。
(4)从URL队列中读取新的URL,然后依据新的URL爬取网页,同时从新的网页中获取新的URL地址,重复上述的爬取过程。
(5)设置停止条件,如果没有设置停止条件时,爬虫会一直爬取下去,直到无法获取新的URL地址为止。设置了停止条件后,爬虫将会在满足停止条件时停止爬取。













