
背景
子图匹配(subgraph matching)旨在从给定的数据图中找出与查询图符合子图同构约束的子图集合。子图匹配的结果常被用于社区发现、图切分、图聚类等图算法的输入,同时也在金融反欺诈、电网管理、社交网络等实际应用中发挥作用。从算法的目标输出分类,子图匹配可以分为四个层次:(1)确定给定的两个图是否符合子图同构约束;(2)找到一个子图同构约束中互相匹配的顶点对;(3)统计数据图中符合子图匹配约束的子图个数;(4)找到所有匹配的子图。目前,相关研究人员已经针对上述四种不同层次的需求分别给出了大量解决方案。
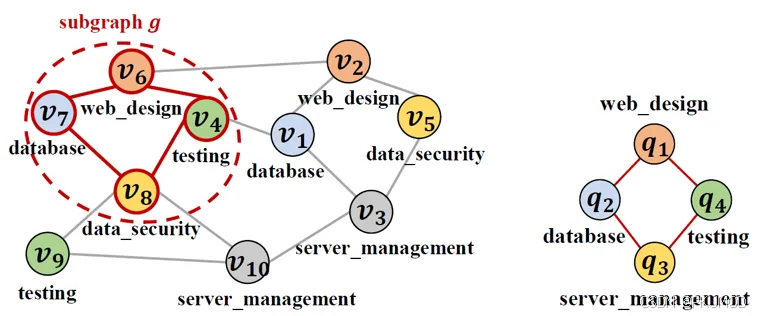
现有工作中主流的设计思路在本文中称为传统方法,其基本遵循“Filter->Order->Enumeration”的逻辑顺序[1],对三个环节给出了大量优化策略。其中,Filter阶段旨在根据标签、度数和邻域的拓扑结构等信息生成查询图中顶点或边在数据图中的的候选顶点或边的集合,以缩小后续的搜索空间。Order阶段旨在根据Filter阶段得到的候选集合大小,以及从数据图中得到的诸如标签选择度等要素,或在Enumeration之前生成完整的匹配顺序,或在Enumeration的每一个迭代步,结合上一轮迭代的一些运行信息动态地确定下一个要匹配的查询顶点。Enumeration阶段则是利用Filter阶段得到的候选集和Order阶段得到的匹配顺序,在解空间中搜索匹配结果,其中涉及到的优化策略包括剪枝、快速集合求交计算、复用中间结果、压缩中间结果等等。
随着面向图的机器学习技术的不断发展,其强大的表达能力和挖掘图数据中深层次联系的潜力逐渐得到学术界的重视,因此,相关研究人员提出了利用图机器学习方法对子图匹配算法进行优化的各类思路。
总的说来,图机器学习方法可以从三个方面切入。其一是在上述“Filter->Order->Enumeration”三个阶段中需要综合考虑各种各样的图的性质,而这些性质的权重往往是固定的,但复杂的图数据分布使得解决方案在面对不同性质的图数据和查询图时应当能够动态地调整这些权重。而机器学习方法可以很好地完成这一任务。其二是传统方法在进行剪枝等决策时通常依赖启发式规则和贪心类算法,这使得该类方法更容易进入局部最优解,而图神经网络的表达能力能够在一定程度上缓解这一问题。其三是子图匹配的枚举过程被认为是NP难问题,但如果能够通过机器学习方法得到顶点或边的嵌入,随后在嵌入空间中完成匹配,则有机会绕过这一搜索过程。
代表工作
本文将介绍两篇利用图机器学习方法改进子图匹配算法的代表性工作。
Reinforcement Learning Based Query Vertex Ordering Model for Subgraph Matching [2]
本文是来自新南威尔士大学和悉尼大学等高校的研究人员发表在ICDE 2022上的工作RL-OVO。
该工作的动机是,其一,机器学习方法能够更好地利用图数据的信息,使得通过学习得到不同的查询图下最优的匹配顺序选择结果成为可能;其二,现有方法中基于启发式规则的贪心算法容易陷入局部最优解,而该工作通过引入强化学习得到策略网络来完成匹配顺序的生成。
RL-OVO的整体架构如下图所示,其主要不同点在于在匹配规则的生成阶段引入了强化学习技术。
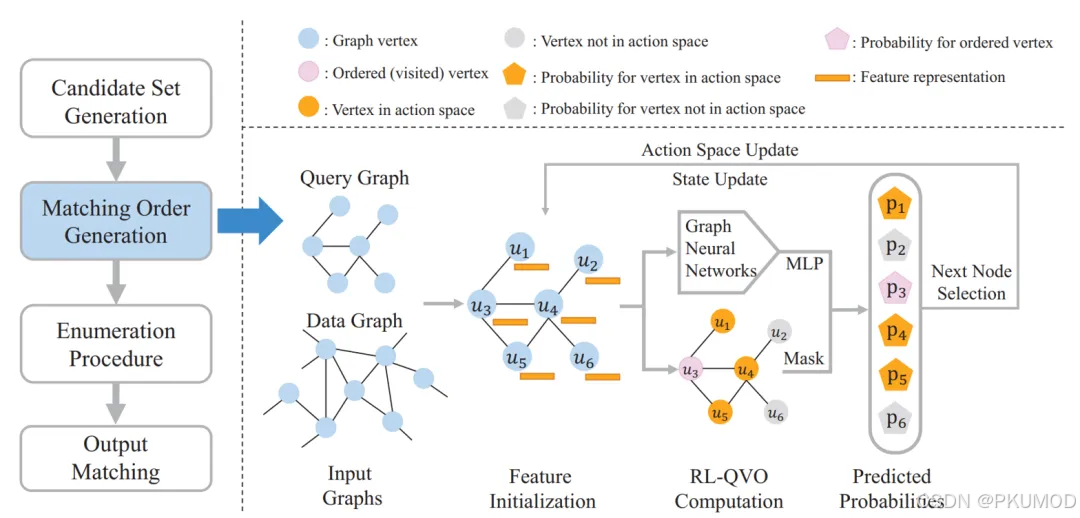
从强化学习的各个要素来看,RL-OVO中的状态定义为当前已经生成的部分匹配顺序以及查询图的图嵌入矩阵。其中,在初始化阶段,RL-OVO首先从查询图和数据图得到查询图中每个点的特征矩阵作为策略网络的初始输入。论文中给出的特征构建如下公式所示:
h u ( 0 ) ( 1 ) = d e g r e e ( u ) / α d e g r e e h_u^{(0)}(1) = degree(u) / \alpha_{degree} hu(0)(1)=degree(u)/αdegree
h u ( 0 ) ( 2 ) = l a b e l ( u ) h_u^{(0)}(2) = label(u) hu(0)(2)=label(u)
h u ( 0 ) ( 3 ) = i d ( u ) h_u^{(0)}(3) = id(u) hu(0)(3)=id(u)
h u ( 0 ) ( 4 ) = ∣ { v ∈ G ∣ d e g r e e ( u ) < d e g r e e ( u ) } ∣ / ( ∣ V ( G ) ∣ × α d ) h_u^{(0)}(4) = |\{v \in G | degree(u) < degree(u)\}| / (|V(G)| \times \alpha_d) hu(0)(4)=∣{v∈G∣degree(u)<degree(u)}∣/(∣V(G)∣×αd)
h u ( 0 ) ( 5 ) = ∣ { v ∈ G ∣ L ( u ) = L ( u ) } ∣ / ( ∣ V ( G ) ∣ × α L ) h_u^{(0)}(5) = |\{v \in G | L(u) = L(u)\}| / (|V(G)| \times \alpha_L) hu(0)(5)=∣{v∈G∣L(u)=L(u)}∣/(∣V(G)∣×αL)
h u ( 0 ) ( 6 ) = ∣ V ( q ) ∣ − t + 1 h_u^{(0)}(6) = |V(q)| - t + 1 hu(0)(6)=∣V(q)∣−t+1
h u ( 0 ) ( 7 ) = I ( u ∉ ϕ t − 1 ) h_u^{(0)}(7) = \mathbb{I}(u \notin \phi_{t-1}) hu(0)(7)=I(u∈/ϕt−1)
其中综合考虑了顶点本身信息及其邻居的信息,还考虑了顺序生成过程中的进度信息。RL-OVO中的Reward函数包括三部分,其一是枚举计数(Reduced enumeration),考虑模型生成的匹配顺序相比传统方法中SOTA的匹配顺序之间所需枚举回溯次数的差距;其二是有效性回报(Valid reward),当模型输出的关于下一个匹配点选择的概率分布中概率最高的点是未被选取的点时,其为一个较小的正值,否则为0;其三是熵回报,对模型输出的概率分布计算其熵得到,以提高模型的泛化能力。上述三者的加权求和即为每一步的Reward函数。同时,为了强调在匹配顺序中顺序靠前的点的重要性,RL-OVO在Reward函数中加入了与顶点在匹配顺序中相关的衰减因子(decay factor)。
RL-OVO的策略网络由图神经网络部分与多层感知机部分构成,前者得到查询点的嵌入,后者生成用于决策的概率分布。论文中选择的图神经网络架构为GCN。在训练过程中使用了经典的PPO策略,使用上一个epoch中的参数作为采样策略网络。同时,为了加速训练进程,作者提出了一种增量训练的策略,在其中一个查询集上训练大量epoch,之后只需要在其他查询集上训练少量epoch即可。

从上图实验结果中可见,在绝大部分数据集上,RL-OVO都取得了与其他传统方法相比更好的性能。
Efficient Exact Subgraph Matching via GNN-based Path Dominance Embedding [3]
本文是来自华东师范和肯特州立大学的研究者发表在VLDB 2024上的工作。其核心思想是通过训练GNN模型,得到符合Donminance约束的图表示,通过图表示构建图上的路径表示,并用于构建支持快速进行子图匹配的索引结构。
该工作的图神经网络模型架构如下图所示,要得到一个顶点 v 1 v_1 v1的图表示,首先需要获取其一步邻居构成的星状图(unit star graph),随后初始化子图中每个点的图表示,先后经过GAT层,Readout层和全连接层得到 v 1 v_1 v1的图表示。

上述网络的训练过程中,该工作与其他工作的明显不同在于,其强制规定损失函数必须收敛到0。如下图所示中的损失函数是对上述星状图及其子图之间的图表示中每个对应维度的值求差得到的(论文中有理论证明,本文篇幅有限不进行展示)。

这样设计损失函数并且规定损失函数必须收敛到0的原因是需要得到的图表示满足Dominance embedding的定义,如下图所示,嵌入 o ( q 1 ) o(q_1) o(q1)的每个维度都小于嵌入 o ( v 1 ) o(v_1) o(v1),则称 o ( v 1 ) o(v_1) o(v1)落在 o ( q 1 ) o(q_1) o(q1)的doninating region中。由于在训练过程中规定损失必须收敛到0,所以只有落在dominating region中的顶点才有可能与 q 1 q_1 q1匹配。这一思想的核心在于使用图表示空间维护了子图之间的同构关系,使得只要通过比较图表示中每个维度的值的大小就可以确定两个点能够匹配。

得到符合Dominance embedding要求的顶点表示后,将一条路径上的所有顶点表示进行拼接即可得到符合Dominance约束的路径表示。这一表示是后续构建用于进行精确子图匹配的路径索引的基础。

具体而言,文中的方法是对每个顶点抽取所有其经过的 L L L跳路径,其中 L L L是给定的参数。随后,得到这一路径集合中所有路径的表示,以此为输入构建一棵R* 树,R* 树是对R树的一种改进,是一种通过划分高维空间中的最小矩形区域对高维数据进行高效索引的数据结构。在实际操作中,生成的R* 树包括了多个利用不同的初始化参数训练得到的GNN模型的路径表示,也包括了与路径上顶点的标签相关的路径标签编码。由于路径编码满足dominance条件,通过在R* 树上进行搜索,同时匹配dominance条件和标签条件,便能够得到与查询路径匹配的路径集合。


从上图实验结果中我们可以看到,本文提出的GNN-PE方法能够在运行时间上在所有的数据集中打败现有的在CPU上的传统算法,但不可否认的是其空间开销和预处理时间都显著高于其他方法。
总结
纵观使用图神经网络优化子图匹配方法的相关工作,本文作者发现其存在两点不足:
其一,与传统方法的比较中,考虑的因素不够全面,比较不够公平。现有方法比较的传统方法绝大部分是运行在CPU端的方法,甚至是单线程实现的方法,而基于机器学习的方法需要使用GPU进行训练,同时在推理过程中有不同程度的并行计算优化,而这部分并发化带来的提升在实验中没有得到很好的体现。基于机器学习的方法投入了十倍的算力成本,但并不能保证带来十倍以上的性能收益。
其二,在相关文章的实验比较中,边规模超过一亿及以上的数据集没有出现,本文作者猜测可能与图规模增大时图神经网络训练成本提高,收敛速度下降有关。
参考文献
[1].Zhijie Zhang, Yujie Lu, Weiguo Zheng, Xuemin Lin: A Comprehensive Survey and Experimental Study of Subgraph Matching: Trends, Unbiasedness, and Interaction. Proc. ACM Manag. Data 2(1): 60:1-60:29 (2024)
[2].Hanchen Wang, Ying Zhang, Lu Qin, Wei Wang, Wenjie Zhang, Xuemin Lin: Reinforcement Learning Based Query Vertex Ordering Model for Subgraph Matching. ICDE 2022: 245-258
[3].Yutong Ye, Xiang Lian, Mingsong Chen:Efficient Exact Subgraph Matching via GNN-based Path Dominance Embedding. Proc. VLDB Endow. 17(7): 1628-1641 (2024)

欢迎关注北京大学王选计算机研究所数据管理实验室微信公众号“图谱学苑“
实验室官网:https://mod.wict.pku.edu.cn/
微信社区群:请回复“社区”获取
实验室开源产品图数据库gStore:
gStore官网:https://www.gstore.cn/
GitHub:https://github.com/pkumod/gStore
Gitee:https://gitee.com/PKUMOD/gStore












