
如何设计一个分布式缓存系统?
一、缓存概述
对于缓存,相信大家已经十分熟悉了,在日常开发中,我们经常会使用到缓存。但对于缓存,这个看似简单的东西,你真的了解它吗?
1.1 什么是缓存?
缓存是一种用于存储临时数据的高速数据存储层,通过将频繁访问的数据存储在内存中,来提高数据访问性能。在计算机系统中,缓存无处不在,从 CPU 的多级缓存,到操作系统的页缓存,到浏览器的页面缓存,再到分布式系统中的数据缓存,都在发挥着重要作用。
1.2 为什么需要缓存?
• 提升性能:通过将热点数据存储在内存中,避免频繁访问数据库或磁盘,显著提高数据访问速度。
• 减轻数据库压力:降低数据库的访问负载,提高系统的并发处理能力。
• 提高系统可用性:当数据库出现故障时,缓存可以作为临时的数据源,保证系统的基本可用性。
根本原因还是 CPU、内存、磁盘的读取速度差异巨大:
• CPU L1 缓存: ~1ns
• 内存: ~100ns
• SSD: ~0.1ms
• HDD: ~10ms
1.3 适合使用缓存的场景
既然缓存能够提升系统性能,那么我们是否就可以无脑地使用缓存呢?肯定不是的。
以下这些场景才适合使用缓存:
• 读多写少的数据:如商品信息、用户信息等相对稳定的数据。
• 计算复杂的数据:如统计数据、排行榜等需要大量计算的数据。
• 高并发访问的数据:如热点新闻、热门商品等。
• 基础数据:如字典数据、配置信息等变更频率低的数据。
对于数据实时性要求不高的场景可以使用缓存,但如果要求实时性很高,建议直接使用数据库。因为现代数据库性能已经足够强大,而引入缓存会增加系统复杂度和维护成本。
1.4 Java中的缓存方案
1.本地缓存
• Map/ConcurrentHashMap:最简单的缓存实现,适合小规模数据。
• Guava Cache:Google 开源的本地缓存实现。
• EhCache:老牌的 Java 缓存框架。
• Caffeine:高性能的本地缓存库。
2.分布式缓存
• Redis:最流行的分布式缓存系统。
• Memcached:高性能的分布式内存缓存系统。
二、Caffeine 原理解析
Caffeine 是目前 Java 中性能最好的本地缓存方案,它在 Guava Cache 的基础上做了大量优化。
2.1 Caffeine 的设计思想
Caffeine 的设计目标是在保证高并发读写 性能的同时,能够最大限度地利用内存空间 。为了达到这个目标,Caffeine 在以下几个方面都做了精心的设计:
1、缓存淘汰算法的创新
• 传统的 LRU(最近最少使用)算法无法很好地处理扫描污染问题。
• 传统的 LFU(最不经常使用)算法对突发性的热点数据支持不好。
• Caffeine 创新性地采用了 Window TinyLFU 算法,结合了 LRU 和 LFU 的优点。
2、并发编程的精妙设计
• 采用了分段锁技术,降低锁粒度。
• 使用无锁编程技术,减少线程竞争。
• 优化的异步处理机制。
下面来详解下 Caffeine的Window TinyLFU算法。
2.2 Window TinyLFU 算法详解
Window TinyLFU 是 Caffeine 性能优化的关键所在,它主要包含以下几个部分:
2.2.1. 准入窗口(Admission Window)
准入窗口 的本质是一个小型的 LRU 缓存,用于过滤突发性的访问,避免对主缓存造成污染。
工作流程:
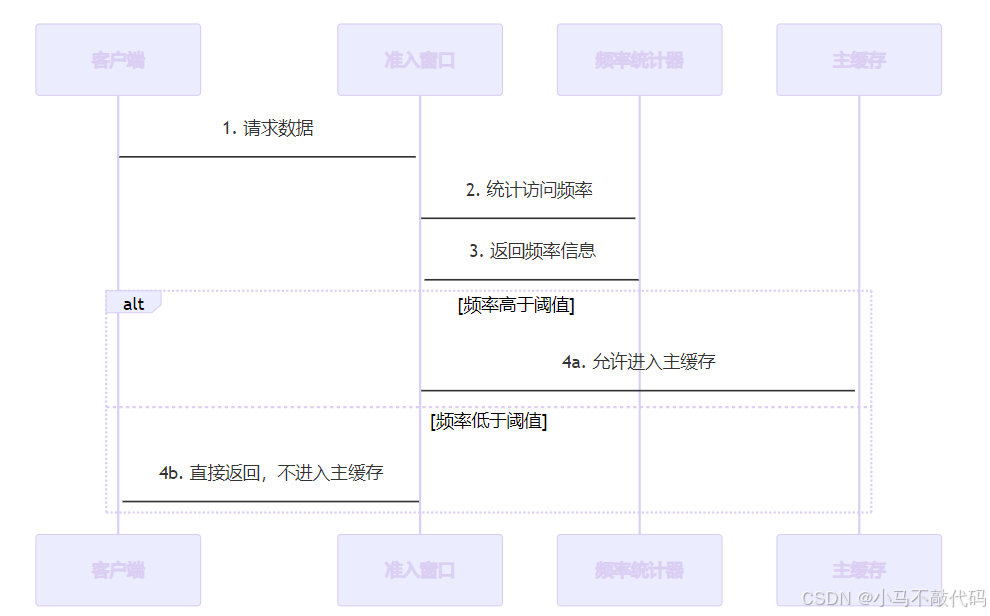
2.2.2.频率统计(Frequency Sketch)
Frequency Sketch 使用Count-Min Sketch 数据结构来记录访问频率,这是一个概率型数据结构,用较小的空间实现频率统计。
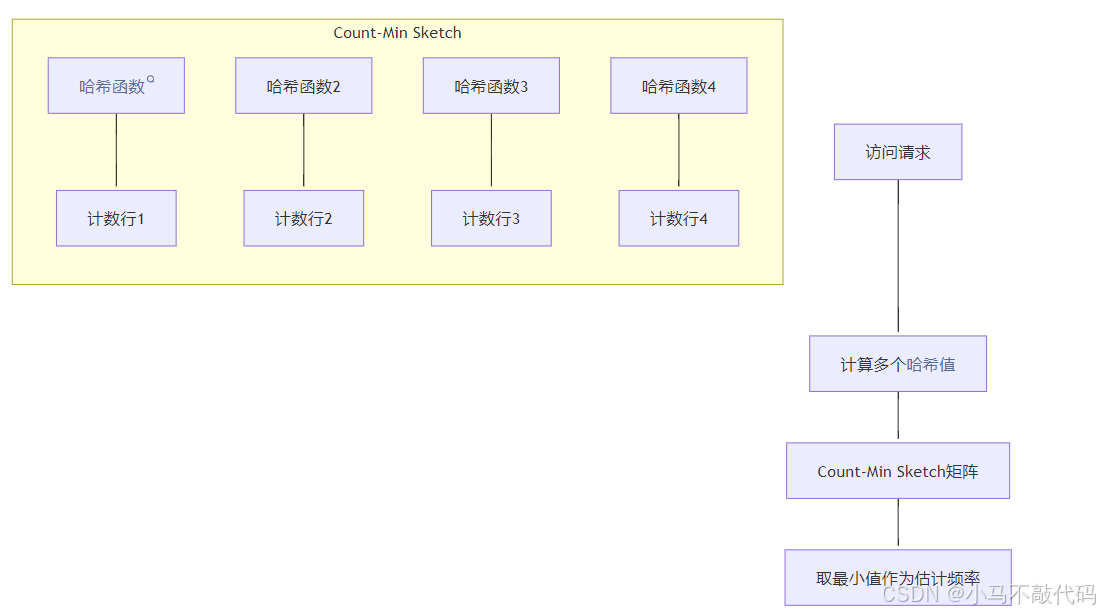
Count-Min Sketch 的工作原理:
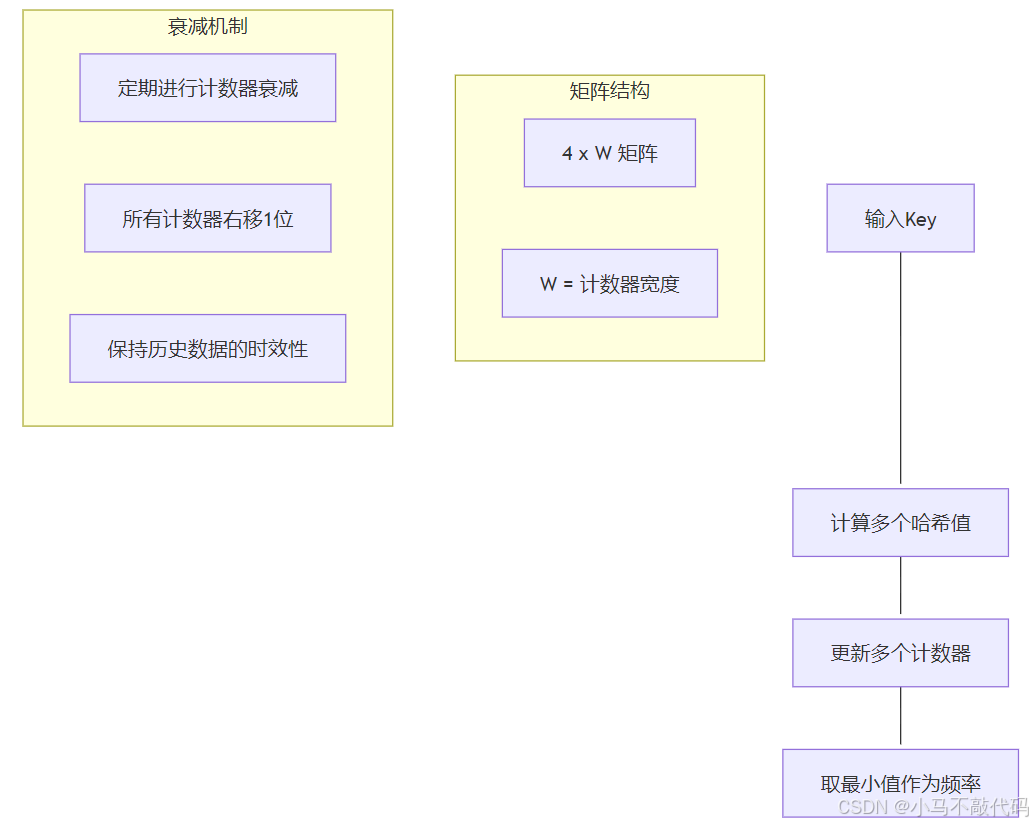
2.2.3. 优化的淘汰策略

示例实现代码:
public classFrequencySketch {privatefinallong[] table;privatefinalint[] seeds;privatefinalint width;privatefinalint rows;publicFrequencySketch(int width, int rows) {this.table = newlong[width * rows];this.seeds = newint[rows];this.width = width;this.rows = rows;// 初始化随机种子Randomrandom=newRandom(1234);for (inti=0; i < rows; i++) {seeds[i] = random.nextInt();}}publicvoidincrement(long item) {// 更新所有行的计数器for (inti=0; i < rows; i++) {intindex= indexOf(item, i);if (table[index] < Long.MAX_VALUE) {table[index]++;}}}publiclongfrequency(long item) {// 获取最小计数值作为估计频率longmin= Long.MAX_VALUE;for (inti=0; i < rows; i++) {min = Math.min(min, table[indexOf(item, i)]);}return min;}privateintindexOf(long item, int row) {// 使用不同的哈希函数计算索引longhash= item * seeds[row];hash += hash >>> 32;return ((int) hash & Integer.MAX_VALUE) % width + (row * width);}
}
2.3 高并发设计
Caffeine 在并发处理上也做了大量优化。
2.3.1. 分段锁设计
// 简化的分段锁示意
classStripedBuffer<K, V> {privatefinal Object[] locks;privatefinal Buffer<K, V>[] buffers;publicvoidwrite(K key, V value) {intindex= hash(key) % locks.length;synchronized (locks[index]) {buffers[index].put(key, value);}}
}
• 降低锁粒度,提高并发性
• 减少线程等待时间
• 优化写入性能
2.3.2.异步处理机制
// Caffeine 异步加载示例
LoadingCache<Key, Graph> graphs = Caffeine.newBuilder().maximumSize(10_000)// 设置缓存过期时间 .expireAfterWrite(Duration.ofMinutes(5))// 设置缓存刷新时间 .refreshAfterWrite(Duration.ofMinutes(1)).build(key -> createExpensiveGraph(key));
• 支持异步加载和刷新
• 非阻塞的缓存操作
• 提高系统吞吐量
2.3.3.写入缓冲区优化
• 使用 BufferWriter 减少锁竞争
• 批量处理写入请求
• 提高写入效率
三、缓存面临的问题
虽说缓存能够提升系统性能,但与此同时,使用缓存也同样会带来很多问题。
3.1 缓存三大问题
下面是缓存的几个经典问题,面试中也经常会被问到,也确实是我们在使用缓存时需要思考和解决的问题。
1、缓存击穿
• 问题:热点 key 过期导致大量请求直击数据库
• 解决:使用分布式锁 + 二级缓存
2、缓存雪崩
• 问题:大量缓存同时过期
• 解决:过期时间随机化、多级缓存、熔断降级
3、缓存穿透
• 问题:查询不存在的数据导致请求直击数据库
• 解决:布隆过滤器、空值缓存
发现没有,上述问题,其实都可以尝试在数据库和本地缓存之间加一层中间层来解决。这也是软件架构设计中的一个常见模式 - 通过分层来化解复杂性。如果一层中间层解决不了,那就再加一层。
3.2 缓存一致性问题
其实,使用缓存面临的最核心的问题,其实是 缓存一致性问题。 这里的一致性,指的是缓存和数据库间的数据一致性,以及多个实例之间本地缓存的一致性。
有哪些场景可能会导致缓存一致性问题?
常见的一致性问题
• 更新数据库后缓存未及时更新。
• 并发更新导致的数据不一致。
• 分布式环境下的数据同步问题,例如多实例的本地缓存不一致。
解决方案
• 先更新数据库,再删除缓存
• 延时双删
• 消息队列实现最终一致性
• 分布式锁保证并发安全
• 版本号机制
四、分布式缓存架构设计
接下来我们来探讨在一个分布式系统中,应该如何来设计我们的缓存系统,以及如何解决上面提到的各种问题。
4.1 多级缓存架构
应用层
↓
本地缓存(Caffeine)
↓
分布式缓存(Redis)
↓
数据库
4.2 缓存更新策略
常见的缓存更新策略有:
• Cache Aside Pattern
• 先更新数据库,再删除缓存
• Read/Write Through Pattern
• 先更新缓存,再更新数据源
• Write Behind Pattern
• 先更新缓存,异步更新数据源
这里我们选择的是 Cache Aside Pattern-先更新数据库,再删除缓存。为什么呢?
让我们通过一个具体的场景来分析下:
1.为什么是删除而不是更新缓存?
• 删除缓存的操作比更新缓存更简单,不容易出错。
• 删除缓存后,后续请求会重新加载数据,确保数据的正确性。
• 如果更新缓存,在并发情况下可能会出现数据不一致的问题。
2.为什么是先更新数据库,再删除缓存?
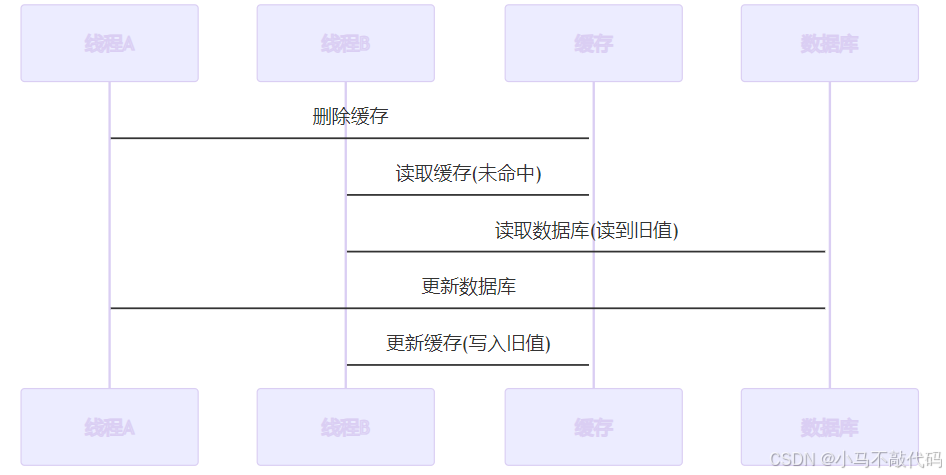
• 如果先删除缓存,再更新数据库,在高并发场景下会出现问题:
1、线程A删除缓存
2、线程B读取缓存未命中,读取旧数据
3、线程A更新数据库
4、线程B将旧数据写入缓存
• 最终缓存中是旧数据,造成数据不一致。
3.Cache Aside Pattern 策略是否存在并发问题?
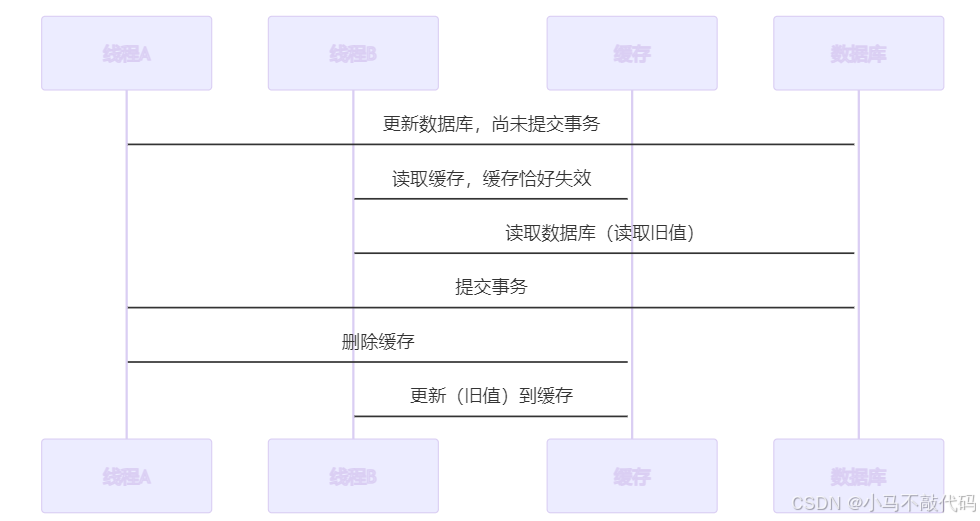
• 理论上存在并发问题,如下图,但概率极小。
• 需要满足以下条件才会出现问题:
1、缓存刚好失效。
2、线程A更新数据库,尚未提交事务,此时线程B读取旧数据。
3、线程A提交事务,删除缓存。
4、线程B更新缓存。
• 实际上在高并发场景中,这个时间窗口也非常小,因为一般从已经读取到数据到设置到缓存这个间隙其实非常短,除非刚好 因GC导致STW 了等极端情况。
4.3 如何解决极端情况下的并发问题?
• 延迟双删:在更新数据库后,延迟一段时间再次删除缓存,可以保障经过短暂时间后,缓存中的数据和数据库中的数据一致。
// 伪代码示例
void updateData() {// 1. 更新数据库db.update(data);// 2. 删除缓存cache.delete(key);// 3. 延迟一段时间后再次删除缓存Thread.sleep(500);cache.delete(key);
}
• 使用消息队列:将缓存删除操作通过消息队列异步执行。
// 伪代码示例
void updateData() {// 1. 更新数据库db.update(data);// 2. 发送消息到队列messageQueue.send(new CacheDeleteMessage(key));
}
4.4 如何使用消息队列解决极端情况下的并发问题?
延时双删能解决极端情况下的缓存一致性问题,可能很多同学都听说过,但为什么使用消息队列也可以?
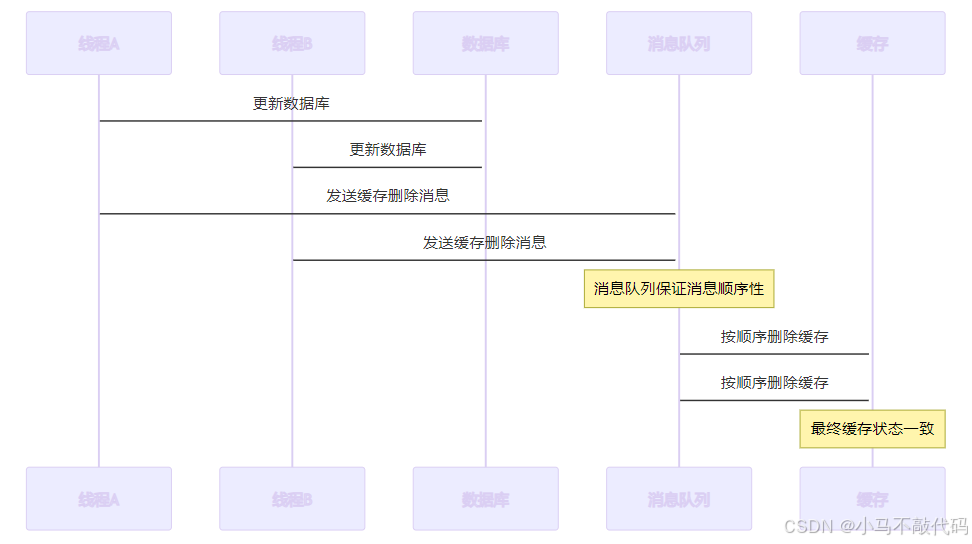
1、异步处理和解耦:
• 当数据库完成更新后(事务提交后),将缓存删除 操作作为一条消息发送到消息队列。
• 消息队列保证了删除操作的顺序性(需要使用顺序消费),即使存在多个请求对同一条数据进行操作,最终的缓存状态是一致的。
2、去重和幂等性:
• 由于删除缓存的操作本身就是幂等的,所以即便消息队列重复消费,也不会对结果产生影响。
3、重试机制:
• 如果由于某些异常,删除缓存的操作失败,消息队列可以提供重试机制,确保删除操作最终完成。
4、并发场景的一致性:
• 即使在高并发场景下,多个线程同时操作同一条数据,通过消息队列的异步特性,可以确保数据库和缓存的状态最终一致。
消息队列的实现
• 每次数据库更新完成后发送消息到队列。
• 消息队列可以按照先后顺序处理缓存的删除操作,确保缓存最终的状态一致。
流程图:
消息队列的实现示例
@Service
publicclassCacheUpdateService {@Autowiredprivate DatabaseService databaseService;@Autowiredprivate MessageQueueService messageQueueService;publicvoidupdateDataAndNotifyCache(String key, Object value) {// 1. 更新数据库databaseService.update(key, value);// 2. 发送缓存删除消息 注意要在事务提交后发送// 这里使用 Spring 的事务管理器来确保在事务提交后发送消息TransactionSynchronizationManager.registerSynchronization(newTransactionSynchronization() {@OverridepublicvoidafterCommit() {messageQueueService.sendMessage("cache_delete_topic", key);}});}
}
消费者示例:
@Component
public class CacheDeleteConsumer {@Resourceprivate CacheService cacheService;@KafkaListener(topics = "cache_delete_topic")public void onMessage(String key) {// 删除缓存,幂等操作cacheService.delete(key);}
}












