
并查集
并查集原理
在一些应用问题中,需要将n个不同的元素划分成一些不相交的集合。开始时,每个元素自成一个单元素集合,然后按一定的规律将归于同一组元素的集合合并。在此过程中要反复用到查询某一个元素归属于那个集合的运算。适合于描述这类问题的抽象数据类型称为并查集(union-findset)。
下边是我画的一个示例图,好好看看如何划分集合的规则
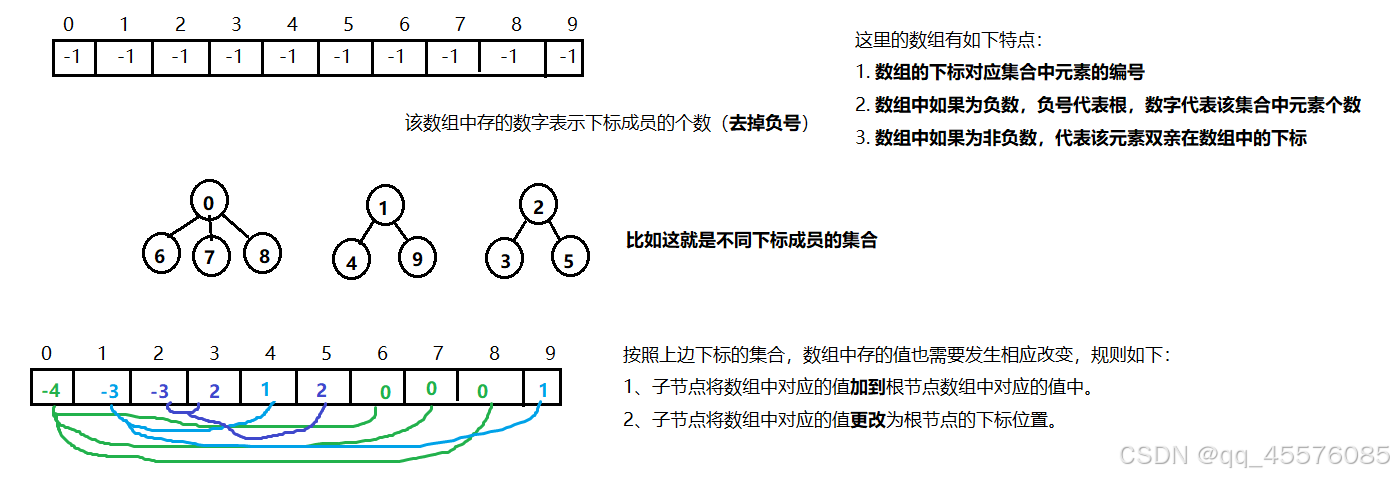
存储并查集的数组有如下特点:
1. 数组的下标对应集合中元素的编号
2. 数组中如果为负数,负号代表根,数字代表该集合中元素个数
3. 数组中如果为非负数,代表该元素双亲在数组中的下标
下边是并查集合并集合的一个示例图
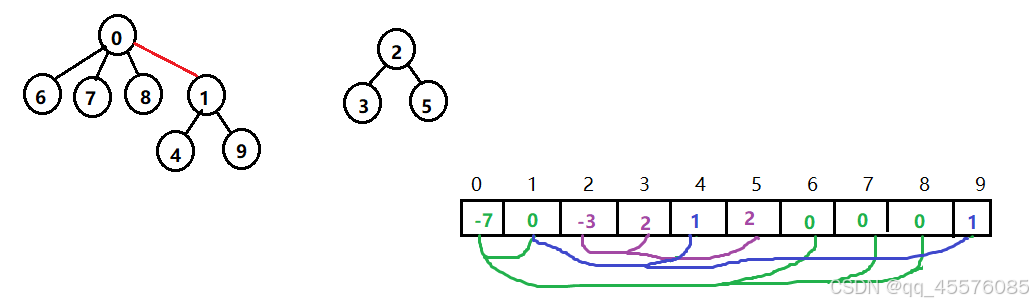
这里将例子中的第二个集合合并到第一个集合。这里的并查集变化如上。
通常并查集有如下功能:
1、查找元素属于哪个集合
沿着数组表示的树形关系,向上找到根节点,即数组中该集合表示负数的位置。
2、查看两个元素是否属于同一个集合
沿着数组表示的树形关系,向上找到根节点,看根节点是否相同
3、将两个集合归并成一个集合
(1)将两个集合中的元素合并
(2)将一个集合名称改为另一个集合的名称
4、集合的个数
遍历数组,数组中元素为负数的个数即集合的个数
并查集代码实现
/*
* 数据结构--------并查集
*/
class UnionFindSet
{
public:UnionFindSet(size_t n):_ufs(n, -1){}//合并,x1和x2进行合并void Union(int x1, int x2){int root1 = FindRoot(x1);int root2 = FindRoot(x2);//如果本身就在一个集合,就不用再合并了if (root1 == root2){return;}//走到这里就说明不是一个集合了/** 这里做数据压缩,当数据量大的时候,能较好的提升效率* 这里假定将数据量小的往数据量大的合并*/if (abs(_ufs[root1]) < abs(_ufs[root2])){std::swap(root1, root2);}/** 这里假定是将第二个合并到第一个*/_ufs[root1] += _ufs[root2];_ufs[root2] = root1;}//找根的位置int FindRoot(int x){int root = x;while (_ufs[root] >= 0){root = _ufs[root];}/** 路径压缩* 路径压缩,就是将多层压成一层的,将多层转变为根的孩子*/while (_ufs[x] >= 0){//由叶节点到根,依次修改int parent = _ufs[x];_ufs[x] = root;x = parent;}return root;}//x1和x2是否在一个集合中bool InSet(int x1, int x2){return FindRoot(x1) == FindRoot(x2);}//计算集合中树的数量 size_t SetSize(){size_t size = 0;for (size_t i = 0; i < _ufs.size(); ++i){if (_ufs[i] < 0) {++size;}}return size;}
private:vector<int> _ufs;
};
这里在合并和查找根的时候做些了路径压缩的优化。合并的时候,策略是将数据量少的合并到数据量多的,较少操作的数据量。查找的时候,策略将多层的数据优化为一层,提升查找效率。
图
图的基础知识
完全图:在有n个顶点的无向图中,若有n * (n-1)/2条边,即任意两个顶点之间有且仅有一条边,则称此图为无向完全图,比如上图G1;在n个顶点的有向图中,若有n * (n-1)条边,即任意两个顶点之间有且仅有方向相反的边,则称此图为有向完全图。
邻接顶点:在无向图中G中,若(u, v)是E(G)中的一条边,则称u和v互为邻接顶点,并称边(u,v)依附于顶点u和v;在有向图G中,若<u, v>是E(G)中的一条边,则称顶点u邻接到v,顶点v邻接自顶点u,并称边<u, v>与顶点u和顶点v相关联。
顶点的度:顶点v的度是指与它相关联的边的条数,记作deg(v)。在有向图中,顶点的度等于该顶点的入度与出度之和,其中顶点v的入度是以v为终点的有向边的条数,记作indev(v);顶点v的出度是以v为起始点的有向边的条数,记作outdev(v)。因此:dev(v) = indev(v) + outdev(v)。注意:对于无向图,顶点的度等于该顶点的入度和出度,即dev(v) = indev(v) = outdev(v)。
路径:在图G = (V, E)中,若从顶点vi出发有一组边使其可到达顶点vj,则称顶点vi到顶点vj的顶点序列为从顶点vi到顶点vj的路径。
路径长度:对于不带权的图,一条路径的路径长度是指该路径上的边的条数;对于带权的图,一条路径的路径长度是指该路径上各个边权值的总和。
简单路径与回路:若路径上各顶点v1,v2,v3,…,vm均不重复,则称这样的路径为简单路
径。若路径上第一个顶点v1和最后一个顶点vm重合,则称这样的路径为回路或环。
子图:设图G = {V, E}和图G1 = {V1,E1},若V1属于V且E1属于E,则称G1是G的子图。
连通图:在无向图中,若从顶点v1到顶点v2有路径,则称顶点v1与顶点v2是连通的。如果图中任意一对顶点都是连通的,则称此图为连通图。
强连通图:在有向图中,若在每一对顶点vi和vj之间都存在一条从vi到vj的路径,也存在一条从vj到vi的路径,则称此图是强连通图。
生成树:一个连通图的最小连通子图称作该图的生成树。有n个顶点的连通图的生成树有n个顶点和n-1条边。
最小生成树
连通图中的每一棵生成树,都是原图的一个极大无环子图,即:从其中删去任何一条边,生成树 就不在连通;反之,在其中引入任何一条新边,都会形成一条回路。
若连通图由n个顶点组成,则其生成树必含n个顶点和n-1条边。因此构造最小生成树的准则有三条:
1. 只能使用图中的边来构造最小生成树
2. 只能使用恰好n-1条边来连接图中的n个顶点
3. 选用的n-1条边不能构成回路
克鲁斯卡尔算法
贪心策略:每次迭代时,选出一条具有最小权值,且两端点不在同一连通分量上的边,加入生成树。
步骤:1、初始化即将返回的生成树。2、使用优先级队列选出图中的最小边。3、使用并查集判断选出的最小边是否会构成环。如若选出的最小边并未出现在并查集中,则可以将其加入并查集中,视为找到了一条新的边。
图解:
代码实现:
struct Edge
{size_t _srci;size_t _dsti;W _w;Edge(size_t srci, size_t dsti, const W& w):_srci(srci),_dsti(dsti),_w(w){}bool operator>(const Edge& e) const{return _w > e._w;}
};
/*
* 克鲁斯卡尔算法(最小生成树)
*/
W Kruskal(Self& minTree)
{//初始化size_t n = _vertexs.size();minTree._vertexs = _vertexs;minTree._indexMap = _indexMap;minTree._matrix.resize(n);for (size_t i = 0; i < n; ++i){minTree._matrix[i].resize(n, MAX_W);}//使用优先级队列找出最小边priority_queue<Edge, vector<Edge>, std::greater<Edge>> Minque; //greaterfor (size_t i = 0; i < n; ++i){for (size_t j = 0; j < n; ++j){//这里是无向图,所以使用i<j 可以避免重复查找if (i < j && _matrix[i][j] != MAX_W){Minque.push(Edge(i, j, _matrix[i][j]));}}}//选出n-1条边size_t size = 0;W totalW = W();//这里使用并查集,将选入的边收入同一个集合UnionFindSet ufs(n);while (!Minque.empty()){//取出最小边Edge min = Minque.top();Minque.pop();if (!ufs.InSet(min._srci, min._dsti))//该最小边并未出现在集合中{cout << _vertexs[min._srci] << "->" << _vertexs[min._dsti] << ":" << min._w << endl;minTree._AddEdge(min._srci, min._dsti, min._w);ufs.Union(min._srci, min._dsti);++size;totalW += min._w;}else{cout << "构成环:";cout << _vertexs[min._srci] << "->" << _vertexs[min._dsti] << ":" << min._w << endl;}}if (size == n - 1){return totalW;}else{return W();}}普利姆算法
贪心策略:选择当前未被选中的顶点中,与已选顶点集合距离最近的顶点,并将其加入到最小生成树中(即每次选边的时候是从两个集合中的顶点直接相连的边中选取权值最小的那一条。),直到所有顶点都被选中。
步骤:1、初始化最小生成树,并确定起点。2、使用优先级队列选出已选集合和未选集合之间最近的边。3、如果选出的最近边在已选集合中,则构环。反之,则不构环,将最近边加入已选集合中
代码实现:
//普利姆算法W Prim(Self& minTree, const W& src){size_t srci = GetVertexIndex(src);size_t n = _vertexs.size();minTree._vertexs = _vertexs;minTree._indexMap = _indexMap;minTree._matrix.resize(n);for (size_t i = 0; i < n; ++i){minTree._matrix[i].resize(n, MAX_W);}vector<bool> X(n, false);//已选集合vector<bool> Y(n, true);//未选集合X[srci] = true;Y[srci] = false;//从X->Y集合中连接的边里面选出最小的边priority_queue<Edge, vector<Edge>, greater<Edge>> minq;for (size_t i = 0; i < n; ++i){if (_matrix[srci][i] != MAX_W){minq.push(Edge(srci, i, _matrix[srci][i]));}}cout << "Prim开始选边" << endl;size_t size = 0;W totoalW = W();while (!minq.empty()){Edge min = minq.top();minq.pop();//如果最小边的目标点也在X集合中,则构成环if (X[min._dsti] == true){cout << "构成环:";cout << _vertexs[min._srci] << "->" << _vertexs[min._dsti] << ":" << min._w << endl;}else{minTree._AddEdge(min._srci, min._dsti, min._w);cout << _vertexs[min._srci] << "->" << _vertexs[min._dsti] << ":" << min._w << endl;X[min._dsti] = true;Y[min._dsti] = false;++size;totoalW += min._w;if (size == n - 1){break;}for (size_t i = 0; i < n; ++i){/** 将新添加顶点的相邻边添加进优先级队列,但是上一个顶点的边不能在添加进去,* 即不能存在在未添加集合X中*/if (_matrix[min._dsti][i] != MAX_W && X[i] == false){minq.push(Edge(min._dsti, i, _matrix[min._dsti][i]));}}}}if (size == n - 1){return totoalW;}else{return W();}}最短路径
(单源)迪杰斯特拉算法
贪心策略:选择当前未被选中的顶点中,与已选顶点集合距离最近的顶点,并将其加入到已选集合中。
步骤:1、构造两个数组,dist表示记录srci-其他顶点最短路径权值数组;pPath表示记录srci-其他顶点最短路径父顶点数组。2、选择的最短路径顶点且不在已选集合中。3、进行松弛操作,更新其它路径。
缺陷:不适用于负权值的有向图
代码实现:
/*
* src表示源点
* dist表示记录srci-其他顶点最短路径权值数组
* pPath表示记录srci-其他顶点最短路径父顶点数组
*/
void Dijkstra(const V& src, vector<W>& dist, vector<int>& pPath)
{size_t srci = GetVertexIndedx(src);size_t n = _vertexs.size();dist.resize(n, MAX_W);pPath.resize(n, -1);dist[srci] = 0;pPath[srci] = srci;vector<bool> S(n, false);//已经确定最短路径的顶点集合for (size_t k = 0; k < n; ++k){/** 选最短路径顶点且不在S更新其它路径*/int u = 0;//这里的u表示不在集合S中的点的下标W min = MAX_W;//这里是记录源点到u的最小权值for (size_t i = 0; i < n; ++i){if (S[i] == false && dist[i] < min){u = i;min = dist[i];}}S[u] = true;//将u加入已选定的集合中/** 松弛操作更新u连接顶点v* (srci->u + u->v) < (srci->v),则更新*/for (size_t v = 0; v < n; ++v){if (S[v] == false&& _matrix[u][v] != MAX_W&& (dist[u] + _matrix[u][v] < dist[v])){dist[v] = dist[u] + _matrix[u][v];pPath[v] = u;}}}
}(单源)贝尔曼福德算法
核心:每次迭代对每条边都进行松弛操作(即先后对所有的顶点的相邻顶点进行松弛),执行迭代的次数最多是边的个数。
步骤:执行流程和迪杰斯特拉算法类似,都是以松弛操作为核心。
优势:寻找最短路径的时候,能够解决带有负权路径的情况。
代码实现:
bool BellmanFord(const V& src, vector<W>& dist, vector<int>& pPath)
{size_t n = _vertexs.size();size_t srci = GetVertexIndedx(src);//vector<W> dist,记录srci-其它顶点最短路径权值数组dist.resize(n, MAX_W);//vector<int> pPath 记录srci-其它顶点最短路径顶点数组pPath.resize(n, -1);//先更新srci->srci为缺省值dist[srci] = W();//最多更新n轮cout << "----upgrade start!!----" << endl;for (size_t k = 0; k < n; ++k){//i->j 松弛更新cout << "第" << k + 1 << "轮更新" << endl;//类似冒泡排序的优化-----提前跳出bool update = false;for (size_t i = 0; i < n; ++i){for (size_t j = 0; j < n; ++j){// srci->i,i->jif (_matrix[i][j] != MAX_W && dist[i] + _matrix[i][j] < dist[j]){update = true;cout << _vertexs[i] << "->" << _vertexs[j] << ":" << _matrix[i][j] << endl;dist[j] = dist[i] + _matrix[i][j];;pPath[j] = i;}}}//如果这个轮次中没有更新出更短路径,那么后续的轮次就不需要再走了if (update == false){break;}}/** 检测负权回路* 贝尔曼福特算法无法解决带负权回路的情况*/for (size_t i = 0; i < n; ++i){for (size_t j = 0; j < n; ++j){// 还能继续更新就表示带负权回路if (_matrix[i][j] != MAX_W && dist[i] + _matrix[i][j] < dist[j]){return false;}}}cout << "----upgrade done!!----" << endl;return true;
}











